Python爬虫scrapy框架实践
爬取湖北工业大学宣讲会信息
爬虫学习
(开发使用的是Python2.7版本 ,这里采用scrapy框架)
之前尝试直接爬取,但是速度远不及scrapy框架。
首先创建项目
这里先输入scrapy2 startproject hbut,即可创建一个名为hbut的项目,这里使用scrapy2的原因是因为电脑上面同时存在Python3,为了避免与Python3的scrapy相冲突,这里将Python2 的scrapy改名为scrapy2

创建爬虫模块
在Termina命令栏下进入hbut里面的spiders目录下面,接着输入scrapy2 genspider hugong https://hbut.91wllm.com
这时在spiders目录下面创建了一个hugong.py的文件

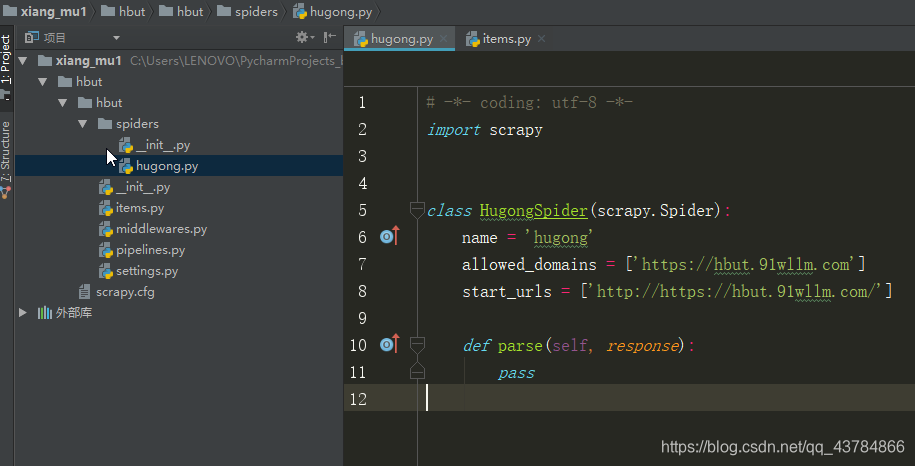
最终文件目录如下图:
编写代码
上面介绍完了使用pycharm创建一个完整的爬虫项目,现在我们继续进行编写代码
定义item文件
这里我们先确定要爬取的内容,举办宣讲会的公司名称,举办时间,地点,还有关于招聘的页面链接。
先确定这些爬取内容后,我们先定义item,item.py代码如下:
class HbutItem(scrapy.Item):
# define the fields for your item here like:
# 公司名称
name = scrapy.Field()
# 地点
place = scrapy.Field()
# 时间
time = scrapy.Field()
# 链接
url = scrapy.Field()
编写爬虫模块
这一步主要是解析数据,scrapy框架解析html默认的解析方法有Selector方法和XPath解析,这里采用XPath解析
这里使用的FireFox浏览器查看页面源代码,打开网页https://hbut.91wllm.com/teachin,源代码如图:
 同时点击下一页,查看页面的链接的规律,发现从第二页(http://hbut.91wllm.com/teachin/index?page=2)往后,只有链接的page后面的数字增加,所以可以采用这个规律来构造url链接
同时点击下一页,查看页面的链接的规律,发现从第二页(http://hbut.91wllm.com/teachin/index?page=2)往后,只有链接的page后面的数字增加,所以可以采用这个规律来构造url链接
代码如下:
# -*- coding: utf-8 -*-
import scrapy
from hbut.items import HbutItem
class HugongSpider(scrapy.Spider):
name = "hugong"
allowed_domains = ['hbut.91wllm.com']
url = "http://hbut.91wllm.com/teachin/index?page="
i = 1
start_urls = [url + str(i)]
def parse(self, response):
infos = response.xpath('//div[@class="infoBox mt10"]/ul[@class="infoList teachinList"]')
for info in infos:
name = info.xpath('./li[@class="span1"]/a/text()|./li[@class="span1"]/a/@title').extract()[0] #这里使用“或”来提取公司名称,防止单个匹配方法失效
# 地点
place = info.xpath('./li[@class="span4"]/text()').extract()[0]
# 时间
time = info.xpath('./li[@class="span5"][2]/text()').extract()[0]
# 页面链接
url = "http://hbut.91wllm.com" + info.xpath('./li[@class="span1"]/a/@href').extract()[0]#采用字符串的拼接来构造完整的链接
item = HbutItem(name=name, place=place, time=time, url=url)
yield item
if self.i <= 68: #页面有68页,做个循环来方便翻页
self.i += 1
yield scrapy.Request(url=self.url+str(self.i),callback=self.parse) #采用回调方法来回调自己本身,实现翻页功能
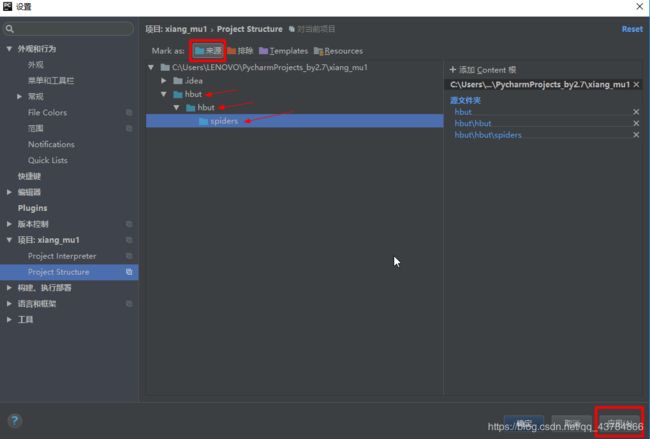
这里要注意的是直接导入item.py里面的类会报错
这样打开pycharm的设置,确定文件的来源,点击应用后确定,即可可成功
定制Item Pipline
我们这里将数据保存为json格式
piplines.py代码如下:
import json
class HbutPipeline(object):
def __init__(self):
self.file = open("hubut.json","wb")
def process_item(self, item, spider):
line = json.dumps(dict(item)) + ",\n"
self.file.write(line)
return item
def close_file(self):
self.file.close()
设置settings.py文件
在settings.py文件里面,注释掉ROBOTSTXT_OBEY,并禁用cookie(将COOKIES_ENABLED设置为False),启用DEFAULT_REQUEST_HEADERS设置请求头
DEFAULT_REQUEST_HEADERS = {
'User-Agent':'Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10_6_8; en-us) AppleWebKit/534.50 (KHTML, like Gecko) Version/5.1 Safari/534.50'
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
}
启用ITEM_PIPELINES用于保存数据
ITEM_PIPELINES = {
'hbut.pipelines.HbutPipeline': 300,
}
启动爬虫
从Terminal里面进入spiders目录下,输入scrapy2 crawl hugong即可执行代码
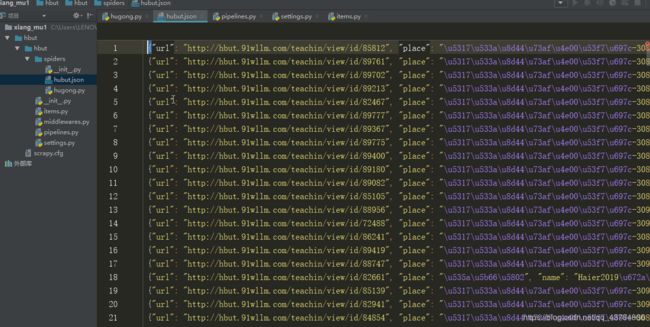
保存数据如下(数据编码格式为utf-8):
补充
如果要保存为Excel格式,可以在settings.py加上
FEED_FORMAT="csv"
并禁用piplines
此时启动命令为 scrapy2 crawl hugong -o hbut.csv
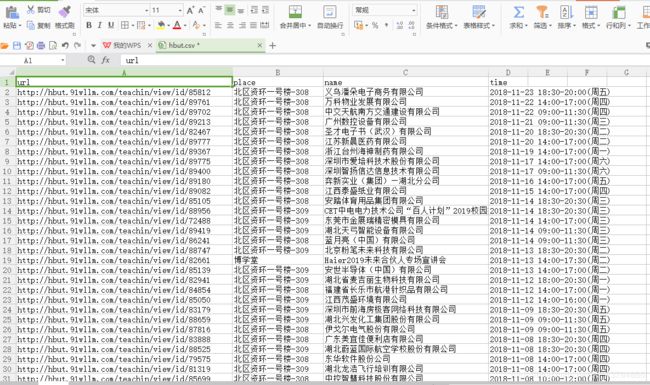
即可将数据保存为名为hbut.csv的Excel文件
结尾
如有不足之处,欢迎指正。
请勿用于商业用途。