BUUCTF reverse:CrackRTF
写在前面:
这道题做了一半多后就陷入了死胡同,思考一天后依旧无法前进,所以看了一位大佬的wp,真的获益匪浅,感觉做题的思路广了很多
1.查壳
 无壳,32位文件
无壳,32位文件
2.IDA分析
找到main函数,F5反编译
int __cdecl main_0()
{
DWORD v0; // eax
DWORD v1; // eax
CHAR String; // [esp+4Ch] [ebp-310h]
int v4; // [esp+150h] [ebp-20Ch]
CHAR String1; // [esp+154h] [ebp-208h]
BYTE pbData; // [esp+258h] [ebp-104h]
memset(&pbData, 0, 0x104u);
memset(&String1, 0, 0x104u);
v4 = 0;
printf("pls input the first passwd(1): ");
scanf("%s", &pbData);
if ( strlen((const char *)&pbData) != 6 )
{
printf("Must be 6 characters!\n");
ExitProcess(0);
}
v4 = atoi((const char *)&pbData);
if ( v4 < 100000 )
ExitProcess(0);
strcat((char *)&pbData, "@DBApp");
v0 = strlen((const char *)&pbData);
sub_40100A(&pbData, v0, &String1);
if ( !_strcmpi(&String1, "6E32D0943418C2C33385BC35A1470250DD8923A9") )// 123321
{
printf("continue...\n\n");
printf("pls input the first passwd(2): ");
memset(&String, 0, 0x104u);
scanf("%s", &String);
if ( strlen(&String) != 6 )
{
printf("Must be 6 characters!\n");
ExitProcess(0);
}
strcat(&String, (const char *)&pbData); // pbdata="123321@DBApp"
memset(&String1, 0, 0x104u);
v1 = strlen(&String); // v1=18
sub_401019((BYTE *)&String, v1, &String1);
if ( !_strcmpi("27019e688a4e62a649fd99cadaafdb4e", &String1) )
{
if ( !sub_40100F(&String) )
{
printf("Error!!\n");
ExitProcess(0);
}
printf("bye ~~\n");
}
}
return 0;
}
if ( strlen((const char *)&pbData) != 6 )
{
printf("Must be 6 characters!\n");
ExitProcess(0);
}
v4 = atoi((const char *)&pbData);
if ( v4 < 100000 )
ExitProcess(0);
这一块代码我们知道,我们输入的密码长度为6位,atoi这个函数是将字符串转化成整形的,并且转化为整形后的数要大于100000
strcat((char *)&pbData, "@DBApp");
v0 = strlen((const char *)&pbData);
这两行代码,第一行将@DBApp连接到输入的密码后面,第二行求出连接之后的密码的长度,为12
sub_40100A(&pbData, v0, &String1);
sub_40100A是一个加密函数,我们进入函数查看一下
int __cdecl sub_401230(BYTE *pbData, DWORD dwDataLen, LPSTR lpString1)
{
int result; // eax
DWORD i; // [esp+4Ch] [ebp-28h]
CHAR String2; // [esp+50h] [ebp-24h]
BYTE v6[20]; // [esp+54h] [ebp-20h]
DWORD pdwDataLen; // [esp+68h] [ebp-Ch]
HCRYPTHASH phHash; // [esp+6Ch] [ebp-8h]
HCRYPTPROV phProv; // [esp+70h] [ebp-4h]
if ( !CryptAcquireContextA(&phProv, 0, 0, 1u, 0xF0000000) )
return 0;
if ( CryptCreateHash(phProv, 0x8004u, 0, 0, &phHash) )// 创建一个空哈希对象
{
if ( CryptHashData(phHash, pbData, dwDataLen, 0) )// 对一块数据进行哈希,把它加到指定的哈希对象中
{
CryptGetHashParam(phHash, 2u, v6, &pdwDataLen, 0);// 得到一个哈希对象参数
*lpString1 = 0;
for ( i = 0; i < pdwDataLen; ++i )
{
wsprintfA(&String2, "%02X", v6[i]);
lstrcatA(lpString1, &String2);
}
CryptDestroyHash(phHash); // 销毁一个哈希对象
CryptReleaseContext(phProv, 0); // 用于释放从CryptAcquireContext调用返回的句柄
result = 1;
}
else
{
CryptDestroyHash(phHash);
CryptReleaseContext(phProv, 0);
result = 0;
}
}
else
{
CryptReleaseContext(phProv, 0);
result = 0;
}
return result;
}
这个函数里面有许多没见过的函数
于是百度,知道了这些函数是用来进行哈希加密的
CryptCreateHash(phProv, 0x8004u, 0, 0, &phHash)
BOOL CryptCreateHash(
HCRYPTPROV hProv,
ALG_ID Algid,
HCRYPTKEY hKey,
DWORD dwFlags,
HCRYPTHASH *phHash
);
代码中的0x8004是标识符
 并且是sha1的加密算法
并且是sha1的加密算法
所以我们可以用python中的hashlib模块把前六位密码爆破出来(100001-999999)
顺道学了一波hashlib模块的基本用法
爆破代码如下
import hashlib
string='@DBApp'
for i in range(100000,999999):
flag=str(i)+string
x = hashlib.sha1(flag.encode("utf8"))
y = x.hexdigest()
if "6e32d0943418c2c33385bc35a1470250dd8923a9" == y:
print(flag)
break
结果为123321@DBApp
所以我们知道了前六位密码是123321,输入进程序看看对不对
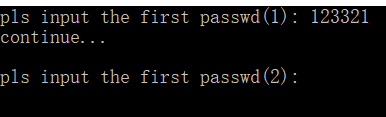
没有问题
然后进入到第二部分密码的分析
scanf("%s", &String);
if ( strlen(&String) != 6 )
{
printf("Must be 6 characters!\n");
ExitProcess(0);
}
同样的,第二部分密码也是六位,但不同的是,程序中并没有说明第二部分的密码的范围,所以不能爆破,所以我们继续往下分析程序
strcat(&String, (const char *)&pbData);
这一行代码将上一部分的123321@DBApp连接到第二部分密码的后面
sub_401019((BYTE *)&String, v1, &String1);
sub_401019是与sub_40100A一样的加密函数
if ( !_strcmpi("27019e688a4e62a649fd99cadaafdb4e", &String1) )
由于无法爆破,所以这一行哈希值代码我们无法利用,只能跳过
下面又有一个函数sub_40100F,点进去看一看
char __cdecl sub_4014D0(LPCSTR lpString)
{
LPCVOID lpBuffer; // [esp+50h] [ebp-1Ch]
DWORD NumberOfBytesWritten; // [esp+58h] [ebp-14h]
DWORD nNumberOfBytesToWrite; // [esp+5Ch] [ebp-10h]
HGLOBAL hResData; // [esp+60h] [ebp-Ch]
HRSRC hResInfo; // [esp+64h] [ebp-8h]
HANDLE hFile; // [esp+68h] [ebp-4h]
hFile = 0;
hResData = 0;
nNumberOfBytesToWrite = 0;
NumberOfBytesWritten = 0;
hResInfo = FindResourceA(0, (LPCSTR)'e', "AAA");
if ( !hResInfo )
return 0;
nNumberOfBytesToWrite = SizeofResource(0, hResInfo);
hResData = LoadResource(0, hResInfo);
if ( !hResData )
return 0;
lpBuffer = LockResource(hResData);
sub_401005(lpString, (int)lpBuffer, nNumberOfBytesToWrite);
hFile = CreateFileA("dbapp.rtf", 0x10000000u, 0, 0, 2u, 0x80u, 0);
if ( hFile == (HANDLE)-1 )
return 0;
if ( !WriteFile(hFile, lpBuffer, nNumberOfBytesToWrite, &NumberOfBytesWritten, 0) )
return 0;
CloseHandle(hFile);
return 1;
}
又是一大片从来没见过的函数
枯了枯了。。。。
但该百度的还是得百度
HRSRC FindResourceA(
HMODULE hModule,
LPCSTR lpName,
LPCSTR lpType
);
FindResourceA function
Determines the location of a resource with the specified type and name in the specified module.
确定具有指定类型和名称的资源在指定模块中的位置。
hModule:处理包含资源的可执行文件的模块。NULL值则指定模块句柄指向操作系统通常情况下创建最近过程的相关位图文件。
lpName:指定资源名称。
lpType:指定资源类型。
返回值:如果函数运行成功,那么返回值为指向被指定资源信息块的句柄。为了获得这些资源,将这个句柄传递给LoadResource函数。如果函数运行失败,则返回值为NULL。
SizeofResource表示该函数返回指定资源的字节数大小。
LoadResource function
检索一个句柄,该句柄可用于获取指向内存中指定资源的第一个字节的指针。
总之这三个函数,一个找句柄,一个通过句柄找指针,一个范围查找的资源的大小
hResInfo = FindResourceA(0, (LPCSTR)'e', "AAA");
if ( !hResInfo )
return 0;
nNumberOfBytesToWrite = SizeofResource(0, hResInfo);
hResData = LoadResource(0, hResInfo);
if ( !hResData )
return 0;
lpBuffer = LockResource(hResData);
这一段代码的含义就是,从AAA文件中查找字符,然后如果没有找到就返回,找到了的话就计算出资源的大小,把资源第一个字符出的指针传给lpBuffer
这里我们可以用一个叫做ResourceHacker的工具来查看资源
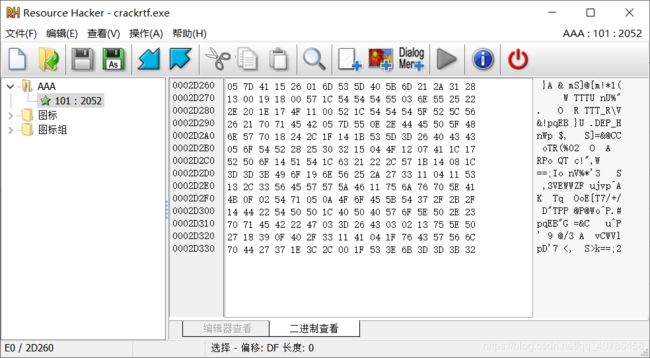 然而一片乱码,不懂
然而一片乱码,不懂
主要是不太懂FindResourceA函数的具体用法,否则有十六进制的数据也应该有办法的
继续往下看代码
sub_401005(lpString, (int)lpBuffer, nNumberOfBytesToWrite);
又碰到一个函数sub_401005
unsigned int __cdecl sub_401420(LPCSTR lpString, int a2, int a3)
{
unsigned int result; // eax
unsigned int i; // [esp+4Ch] [ebp-Ch]
unsigned int v5; // [esp+54h] [ebp-4h]
v5 = lstrlenA(lpString);
for ( i = 0; ; ++i )
{
result = i;
if ( i >= a3 )
break;
*(_BYTE *)(i + a2) ^= lpString[i % v5];
}
return result;
}
一个主逻辑是异或的函数
转换成正常的C语言如下
unsigned int result; // eax
unsigned int i; // [esp+4Ch] [ebp-Ch]
unsigned int v5; // [esp+54h] [ebp-4h]
v5 = strlen(lpString);
for ( i = 0; ; ++i )
{
result = i;
if ( i >= a3 )
break;
a2[i] ^= lpString[i % v5];
}
return result;
资源的每一位和密码的每一位循环异或
异或结束之后,生成一个rtf文件
接下来这一步是我觉得很骚气 巧妙的一步
思考一下
我们的密码一共是6+12=18位
我们现在想要的是前六位的密码,循环异或的话,那么也就是说,资源的前六位与密码的前六位异或的结果就是rtf文件的前六位
我们找来一个rtf文件,看看它的标志位
![]() 前六位是
前六位是{\rtf1
再看一下资源的前六位
![]()
逻辑理清楚之后,就可以开始写脚本了
rtf = '{\\rtf1' \\需要注意,\r需要转义,变成\\r
A = [0x05, 0x7D, 0x41, 0x15, 0x26, 0x01]
password=''
for i in range(len(rtf)):
x = ord(rtf[i]) ^ A[i]
password+=chr(x)
print(password)
结果为~!3a@0
接下来就可以继续输入第二段密码了
两端密码输入完后,就会在程序所在文件夹中生成一个带有flag的rtf文件,打开就能得到flag
flag为Flag{N0_M0re_Free_Bugs}
我觉得这是一道非常棒的题目,既让我在做题过程中通过查询资料获取新的知识点,又开阔了做题思路,发散了思维,所以我迫不及待的在博客中写下了这道题,感谢那些之前做出来并且分享思路的大佬们