图神经网络(GNN)基础
前言
现在很多的学习任务需要处理内在关系丰富的图结构数据,比如物理系统建模,分子指纹,蛋白质结构分析,疾病分类。GNN的优点非常明显就是可以以任意深度表示其附近的信息,并且根据适当的方法利用它们。但是缺点在于GNN难以学习。
图(graph)是一种数据结构,图神经网络(Graph Neural Network)是深度学习在图结构数据上的一些模型、方法和应用。常见的图结构由节点(node)和边(edge)构成,节点包含了实体(entity)信息,边包含实体间的关系(relation)信息。
不动点理论
GNN的理论基础是不动点(the fixed point)理论,这里的不动点理论专指巴拿赫不动点定理(Banach’s Fixed Point Theorem)。首先我们用 F F F表示若干个 f f f堆叠得到的一个函数,也称为全局更新函数,那么图上所有结点的状态更新公式可以写成:
H t + 1 = F ( H t , X ) H^{t+1}=F(H^t,X) Ht+1=F(Ht,X)
不动点定理指的就是,不论 H 0 H^0 H0是什么,只要 F F F是个压缩映射(contraction map), H 0 H^0 H0经过不断迭代都会收敛到某一个固定的点,
这里需要额外解释的是 H H H是每个结点隐藏状态向量的堆叠,同时压缩映射的概念可以通过一张图很清晰的理解 经过 F F F变换后的新空间一定比原先的空间要小,原先的空间被压缩了。想象这种压缩的过程不断进行,最终就会把原空间中的所有点映射到一个点上。这就可以类比于不断更新的隐藏状态参数,经历数次的迭代得到趋于稳定的 H H H值之后将它看作是最后映射成为的不动点
经过 F F F变换后的新空间一定比原先的空间要小,原先的空间被压缩了。想象这种压缩的过程不断进行,最终就会把原空间中的所有点映射到一个点上。这就可以类比于不断更新的隐藏状态参数,经历数次的迭代得到趋于稳定的 H H H值之后将它看作是最后映射成为的不动点
至于如何保证 f f f是一个压缩映射在这里不做讨论,只是了解GNN的理论基础
图的状态更新及输出
变量定义
GNN的理论基础是不动点理论。给定一张图 G G G,每个节点都有自己的特征(feature),用 X v X_v Xv表示节点 v v v的特征;连接两个节点的边也有特征信息用 X ( v , u ) X_(v,u) X(v,u)表示节点 v v v和 u u u之间边的特征信息。
GNN的学习目标
GNN的学习目标是获得每个结点的图感知隐藏状态 h v h_v hv(state embedding)并基于此获得每个结点的输出以达到对所输入的数据模型进行学习的目的,其中个包含了每个结点来自邻居节点的信息。
GNN的状态更新
为了让每个节点感知到全局结点的信息,GNN通过迭代式遍历更新所有结点的隐藏状态,例如在在 t + 1 t+1 t+1时刻,结点 v v v的隐藏状态按照如下方式更新![]() 上面这个公式中的 f f f就是隐藏状态的状态更新函数,在论文中也被称为局部转移函数(local transaction function)公式中的 x c o [ v ] x_co[v] xco[v]指的是与结点v相邻的边的特征, x n e [ v ] x_ne[v] xne[v]指的是结点v的邻居结点的特征, h n t e [ v ] h^t_ne[v] hnte[v]则指邻居结点在t时刻的隐藏状态. f f f是对所有结点都成立的,是一个全局共享的函数。首先来看一个具体点的隐藏状态向量的求解
上面这个公式中的 f f f就是隐藏状态的状态更新函数,在论文中也被称为局部转移函数(local transaction function)公式中的 x c o [ v ] x_co[v] xco[v]指的是与结点v相邻的边的特征, x n e [ v ] x_ne[v] xne[v]指的是结点v的邻居结点的特征, h n t e [ v ] h^t_ne[v] hnte[v]则指邻居结点在t时刻的隐藏状态. f f f是对所有结点都成立的,是一个全局共享的函数。首先来看一个具体点的隐藏状态向量的求解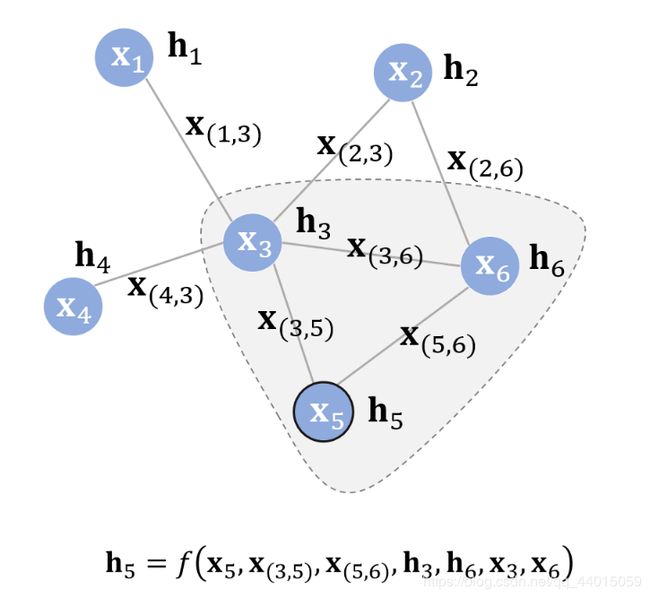 假设结点5为中心结点,其隐藏状态的更新函数如图所示。至此只是完成了某一结点隐藏状态参数的求解,同时还需要综合考虑全局结点以及边的信息对某一结点的影响。因此需要对任何一节点的的隐藏状态进行实时更新,不断优化隐藏状态参数值。总结来说就是不断地利用当前时刻邻居结点的隐藏状态作为部分输入来生成下一时刻中心结点的隐藏状态,直到每个结点的隐藏状态变化幅度很小,整个图的信息流动趋于平稳。至此,每个结点都“知晓”了其邻居的信息。状态更新公式仅描述了如何获取每个结点的隐藏状态。
假设结点5为中心结点,其隐藏状态的更新函数如图所示。至此只是完成了某一结点隐藏状态参数的求解,同时还需要综合考虑全局结点以及边的信息对某一结点的影响。因此需要对任何一节点的的隐藏状态进行实时更新,不断优化隐藏状态参数值。总结来说就是不断地利用当前时刻邻居结点的隐藏状态作为部分输入来生成下一时刻中心结点的隐藏状态,直到每个结点的隐藏状态变化幅度很小,整个图的信息流动趋于平稳。至此,每个结点都“知晓”了其邻居的信息。状态更新公式仅描述了如何获取每个结点的隐藏状态。
在具体实现中, f 其实通过一个简单的前馈神经网络(Feed-forward Neural Network)即可实现。比如说,一种实现方法可以是把每个邻居结点的特征、隐藏状态、每条相连边的特征以及结点本身的特征简单拼接在一起,在经过前馈神经网络后做一次简单的加和。

GNN的输出
经过上述隐藏状态参数的获取和更新之后,已经得到了每一个结点相对平稳的隐藏状态参数。之后需要在此基础之上对隐藏状态参数进行处理得到每个结点的输出。因此我们还需要另外一个函数 g g g来描述如何根据每个结点的隐藏状态向量产生对应的输出。比如输出可以是结点的标签。
g g g函数定义如下
![]() g g g又被称为局部输出函数(local output function),与 f f f类似, g g g也可以由一个神经网络来表达,它也是一个全局共享的函数。
g g g又被称为局部输出函数(local output function),与 f f f类似, g g g也可以由一个神经网络来表达,它也是一个全局共享的函数。
流程表示
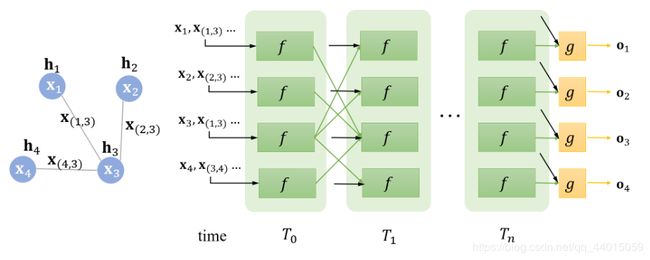 仔细观察两个时刻之间的连线,它与图的连线密切相关。比如说在 T 1 T1 T1时刻,结点 1 的状态接受来自结点 3 的上一时刻的隐藏状态,因为结点 1 与结点 3相邻。直到 T n Tn Tn时刻,各个结点隐藏状态收敛,每个结点后面接一个 g g g即可得到该结点的输出 o o o。
仔细观察两个时刻之间的连线,它与图的连线密切相关。比如说在 T 1 T1 T1时刻,结点 1 的状态接受来自结点 3 的上一时刻的隐藏状态,因为结点 1 与结点 3相邻。直到 T n Tn Tn时刻,各个结点隐藏状态收敛,每个结点后面接一个 g g g即可得到该结点的输出 o o o。
对于不同的图来说,收敛的时刻可能不同,因为收敛是通过两个时刻 p p p范数的差值是否小于某个阈值 ϵ ϵ ϵ来判定的,比如: ∣ ∣ H t + 1 ∣ ∣ 2 − ∣ ∣ H t ∣ ∣ 2 < ϵ ||Ht+1||_2−||Ht||_2<ϵ ∣∣Ht+1∣∣2−∣∣Ht∣∣2<ϵ
模型学习
虽然每个节点都会隐藏状态以及输出,但并不是每个结点都会有相应的监督信号(也就是标签信息)。社交网络中只有部分用户被明确标记了是否为水军账号,这就构成了一个典型的结点二分类问题。
那么很自然地,模型的损失即通过这些有监督信号的结点得到。假设监督结点一共有 p p p个,模型损失可以形式化为: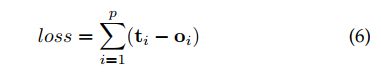 那么,模型如何学习呢?根据前向传播计算损失的过程,不难推出反向传播计算梯度的过程。在前向传播中,模型:
那么,模型如何学习呢?根据前向传播计算损失的过程,不难推出反向传播计算梯度的过程。在前向传播中,模型:
- 调用 f f f若干次,比如 T n T_n Tn次,直到 h v T n h^{Tn}_v hvTn收敛。
- 此时每个结点的隐藏状态接近不动点的解。
- 对于有监督信号的结点,将其隐藏状态通过 g g g得到输出,进而算出模型的损失。
根据上面的过程,在反向传播时,我们可以直接求出 f 和 g g g对最终的隐藏状态 h v T n h^{Tn}_v hvTn的梯度。然而,因为模型递归调用了 f f f若干次,为计算 f f f和 g g g对最初的隐藏状态 h v 0 h^0_v hv0的梯度,我们需要同样递归式/迭代式地计算 T n T_n Tn次梯度。最终得到的梯度即为 f f f和 g g g对 h v 0 h^0_v hv0的梯度,然后该梯度用于更新模型的参数。这个算法就是 Almeida-Pineda 算法
实例探究
下面我们举个实例来说明图神经网络是如何应用在实际场景中的,假设我们现在有这样一个任务,给定一个环烃化合物的分子结构(包括原子类型,原子键等),模型学习的目标是判断其是否有害。这是一个典型的二分类问题,一个训练样本如下图所示:
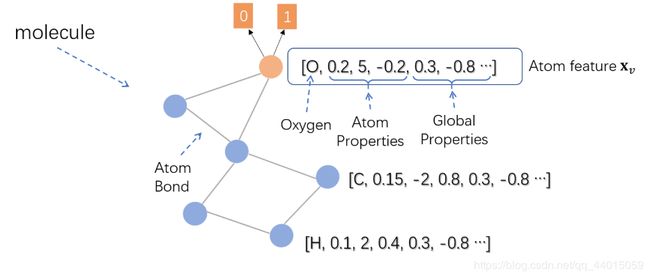 由于化合物的分类实际上需要对整个图进行分类,在论文中,作者将化合物的根结点的表示作为整个图的表示,如图上红色的结点所示。Atom feature 中包括了每个原子的类型(Oxygen, 氧原子)、原子自身的属性(Atom Properties)、化合物的一些特征(Global Properties)等。把每个原子看作图中的结点,原子键视作边,一个分子(Molecule)就可以看作一张图。在不断迭代得到根结点氧原子收敛的隐藏状态后,在上面接一个前馈神经网络作为输出层(即g函数),就可以对整个化合物进行二分类了。
由于化合物的分类实际上需要对整个图进行分类,在论文中,作者将化合物的根结点的表示作为整个图的表示,如图上红色的结点所示。Atom feature 中包括了每个原子的类型(Oxygen, 氧原子)、原子自身的属性(Atom Properties)、化合物的一些特征(Global Properties)等。把每个原子看作图中的结点,原子键视作边,一个分子(Molecule)就可以看作一张图。在不断迭代得到根结点氧原子收敛的隐藏状态后,在上面接一个前馈神经网络作为输出层(即g函数),就可以对整个化合物进行二分类了。
传统GNN的局限
初代GNN,也就是基于循环结构的图神经网络的核心是不动点理论。它的核心观点是通过结点信息的传播使整张图达到收敛,在其基础上再进行预测。收敛作为GNN的内核,同样局限了其更广泛的使用,其中最突出的是两个问题:
- GNN只将边作为一种传播手段,但并未区分不同边的功能。虽然我们可以在特征构造阶段 ( x ( u , v ) ) (x_{(u,v)}) (x(u,v))为不同类型的边赋予不同的特征,但相比于其他输入,边对结点隐藏状态的影响实在有限。GNN没有为边设置独立的可学习参数,也就意味着无法通过模型学习到边的某些特性。
- 对不动点采用迭代的方式来更新节点的隐藏状态效率不理想。在迭代过程中,原始GNN使用相同的参数,而其他比较著名的模型在不同的网络层采用不同的参数,使得模型能够学习到更加深的特征表达
- 如果把GNN应用在图表示的场景中,使用不动点理论并不合适。这主要是因为基于不动点的收敛会导致结点之间的隐藏状态间存在较多信息共享,从而导致结点的状态太过光滑(Over Smooth),并且属于结点自身的特征信息匮乏(Less Informative)。
Reference
参考
这篇文章真的是写的非常棒,反复看论文没法清晰理解的地方立马清楚了
本篇文章参考了许多此篇文章的内容,不过在结构和一些内容上加了一些笔者自己的理解。后续会根据此片参考的后续继续更新