大模型日报-20240204
文章目录
-
- 大模型也有小偷?为保护你的参数,上交大给大模型制作「人类可读指纹」
- 阿里全新Agent玩转手机:刷短视频自主点赞评论,还学会了跨应用操作
- 代谢数据集上四项指标达94%~98%,西南交大团队开发多尺度图神经网络框架,助力药物研发
- A16Z 最新 AI 洞察|2023 年是 AI 视频元年,2024 年还有这些难题需要解决
- 比肩GPT-4,商汤日日新大幅升级4.0,多模态能力领先一步
- 年龄两岁,教龄一年半:婴儿AI训练师登上Science
- 亚马逊推出人工智能购物助手 TRufusJ
- 2B参数性能超Mistral-7B:面壁智能多模态端侧模型开源
- Stutz分享在谷歌DeepMind的经历和反思:人工智能领域的发展速度令人难以置信
- OpenBMB发布一系列边缘模型,包括接近Mistral 7B的2.4B基础模型
- Jim Fan:机器人学是一个负担重重的领域,有太多设计不良的软件、算法补丁和过时的思维模式
- SwarmBrain: 通过大语言模型在实时战略游戏《星际争霸II》中实现具身智能体
- GPTGuard
- Flipner AI
- MoE-LLaVA
大模型也有小偷?为保护你的参数,上交大给大模型制作「人类可读指纹」
https://mp.weixin.qq.com/s/wy2HKsG-HRk8p6pe5pW87A
大模型的预训练需要耗费巨量的计算资源和数据,因而预训练模型的参数也正成为各大机构重点保护的核心竞争力和资产。然而,不同于传统的软件知识产权保护可以通过比对源代码来确认是否存在代码盗用,对预训练模型参数盗用的判断存在以下两方面的新问题:1) 预训练模型的参数,尤其是千亿级别模型的参数,通常不会开源。2) 更重要的是,预训练模型的输出和参数都会随着 SFT、RLHF、continue pretraining 等下游处理步骤而变化。这使得无论是基于模型输出还是基于模型参数,都很难判断某一模型是否是基于另一现有模型微调得来。因此,对大模型参数的保护是一个尚缺乏有效解决方案的全新问题。为此,来自上海交通大学林洲汉老师的 Lumia 研究团队研发了一种人类可读的大模型指纹,这一方法可以在不需要公开模型参数的条件下,有效识别各个大模型之间的血统关系。
阿里全新Agent玩转手机:刷短视频自主点赞评论,还学会了跨应用操作

https://mp.weixin.qq.com/s/bt2VNschheVL413mSV5guw
会操纵手机的智能体,又迎来了全新升级!新的Agent打破了APP的界限,能够跨应用完成任务,成为了真·超级手机助手。比如根据指示,它可以自行搜索篮球比赛的结果,然后根据赛况在备忘录中撰写文稿。来自阿里的一篇最新论文,展示了全新手机操纵智能体框架Mobile-Agent,可以玩转10款应用,还能跨越APP完成用户交给的任务,而且即插即用无需训练。依托多模态大模型,整个操纵过程完全基于视觉能力实现,不再需要给APP编写XML操作文档。
代谢数据集上四项指标达94%~98%,西南交大团队开发多尺度图神经网络框架,助力药物研发
https://mp.weixin.qq.com/s/P3CXwUeuOdDDCEQKYIK5_w
药物研发过程中,了解分子与代谢路径之间的关系,对于合成新分子和优化药物代谢机制至关重要。西南交通大学杨燕/江永全团队开发了一种新型的多尺度图神经网络框架MSGNN,来将化合物与代谢路径联系起来。它包括特征编码器、子图编码器和全局特征处理器三部分,分别学习了原子特征、子结构特征和额外的全局分子特征,这三个尺度的特征可赋予模型更全面的信息。该框架在 KEGG 代谢路径数据集上的表现优于现有方法,Accuracy、Precision、Recall、F1分别达到98.17%、94.18%、94.43%、94.30%。并且,团队还采用了图增强策略将训练集中的数据量扩充了十倍,使模型训练更加充分。
A16Z 最新 AI 洞察|2023 年是 AI 视频元年,2024 年还有这些难题需要解决

https://mp.weixin.qq.com/s/_WdPoPfptK8zch7C4dh1iQ
这是 A16Z 合伙人 Justine Moore 最新发布的 2024 年 AI 视频展望。Justine 提到,2023 年对于 AI 视频领域来说,是突破性的一年。2023 年初时,公开的文本转视频模型尚不存在。仅仅 12 个月后,数十种视频生成产品已被积极使用,全球有数百万用户通过文本或图像提示创建短片。这些产品仍然有相对的局限性——大多数生成的视频时长为 3~4 秒,输出的质量参差不齐,像角色一致性这样的问题还未得到解决。我们距离用单一文本提示(或甚至多个提示!)创造出皮克斯级别的短片还有很长的路要走。然而,过去一年在视频生成领域所见证的进步表明,我们正处于一场巨大变革的初期阶段,这与 A16Z 在图像生成领域所见到的相似。我们正在见证文本转视频模型的持续改进,以及像图像转视频和视频转视频这样的衍生技术正在获得动力。为了帮助理解这场创新的爆炸,A16Z 追踪了到目前为止最重要的发展、值得关注的公司,以及这个领域中剩余的基本问题。
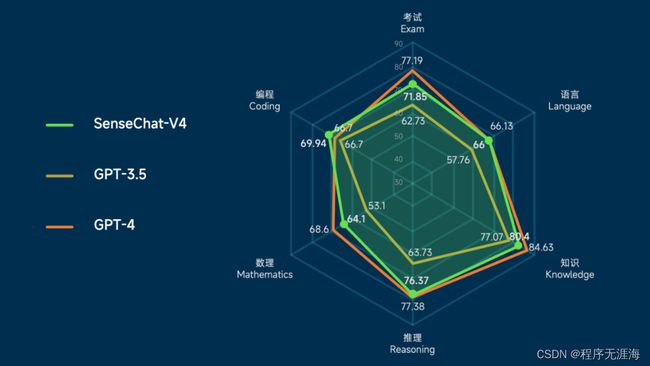
比肩GPT-4,商汤日日新大幅升级4.0,多模态能力领先一步
https://mp.weixin.qq.com/s/Z7sx4a6B77gauPhotdwb2g
商汤的大模型体系「日日新 SenseNova」今天刚刚发布了 4.0 版,不论语言能力还是文生图能力都有全面升级,还自带低门槛的落地工具。新一代 SenseNova 不仅在大语言模型、文生图模型等方面进行了重大升级,部分垂直领域能力超越 GPT-4,还发布了全新多模态大模型,并面向数据分析、医疗等场景提供了全新版本,让大模型通用能力适配到了更多领域。
年龄两岁,教龄一年半:婴儿AI训练师登上Science

https://mp.weixin.qq.com/s/myOn710RfkNPBhjSaYuxlw
在公开采访中,图灵奖得主 Yann LeCun 多次提到,现在的 AI 模型和人类婴儿相比,学习效率实在是太低了。那么,如果让一个 AI 模型去学习婴儿头戴摄像头拍到的东西,它能学到什么?最近,Science 杂志上的一篇论文进行了初步尝试。研究发现,即使数据有限,AI 模型也能从 10 到 100 个例子中学到单词 - 视觉所指对象之间的映射,而且能够零样本地泛化到新的视觉数据集,并实现多模态对齐。这说明,利用当今的人工智能工具,从婴儿的视角进行真正的语言学习是可能的。
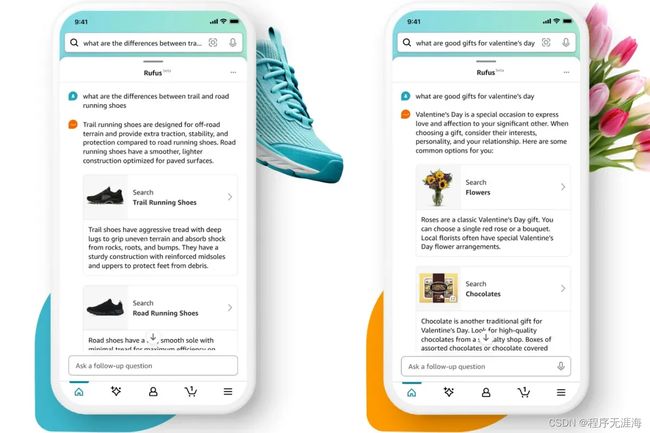
亚马逊推出人工智能购物助手 TRufusJ
https://www.theverge.com/2024/2/1/24058381/amazon-ai-shopping-assistant-rufus
亚马逊推出名为 Rufus 的人工智能购物助手,与该公司的柯基吉祥物同名。该聊天机器人接受了亚马逊产品库、客户评论以及网络信息的训练,使其能够回答有关产品的问题、进行比较、提供建议等。Rufus 仍处于测试阶段,只会出现在“特定客户“中,然后在未来几周内向更多用户推出。
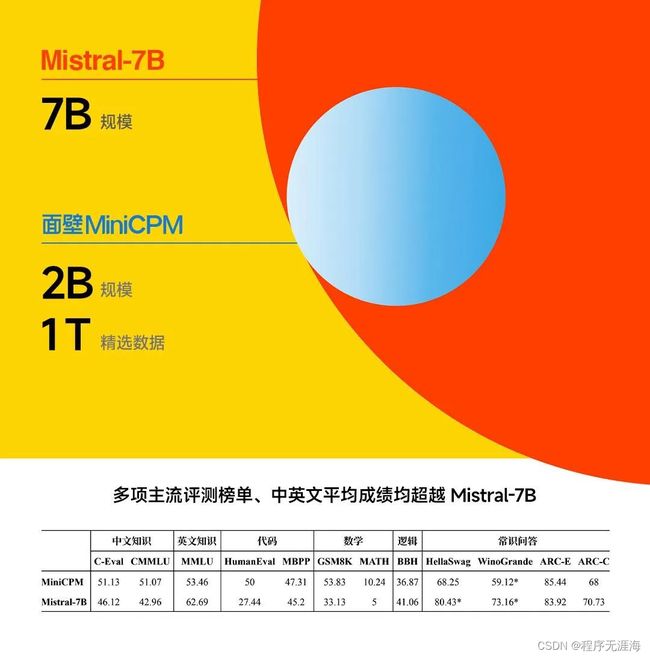
2B参数性能超Mistral-7B:面壁智能多模态端侧模型开源
https://mp.weixin.qq.com/s/DiI_n75fmhEjUVN60qVJxQ
在大模型不断向着大体量方向前进的同时,最近一段时间,人们在优化和部署方面也取得了成果。2 月 1 日,面壁智能联合清华 NLP 实验室在北京正式发布了旗舰端侧大模型「面壁 MiniCPM」。新一代大模型被称为「性能小钢炮」,直接拥抱终端部署,同时也具有同量级最强的多模态能力。面壁智能本次提出的 MiniCPM 2B 参数量仅有 20 亿,使用 1T token 的精选数据训练。这是一个参数量上与 2018 年 BERT 同级的模型,面壁智能在其之上实现了极致的性能优化与成本控制,让该模型可以「越级打怪」。面壁智能联合创始人、CEO 李大海将新模型与业内知名开源大模型 Mistral-7B 进行了对比,在多项主流评测榜单上,MiniCPM 2B 的性能全面超越了后者。
Stutz分享在谷歌DeepMind的经历和反思:人工智能领域的发展速度令人难以置信
https://x.com/davidstutz92/status/1753112541835001899?s=20
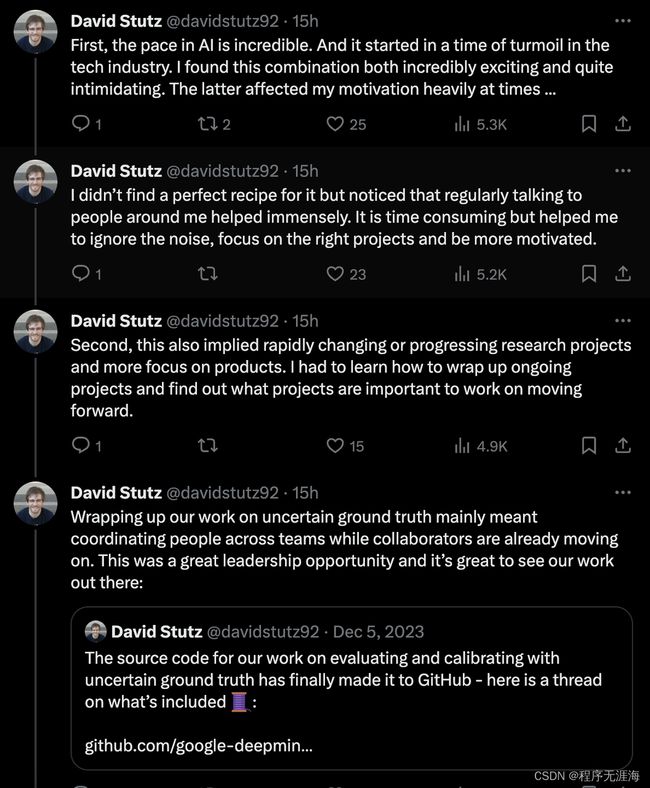
我加入@GoogleDeepMind全职已经近2年了。大约一年前,在@NeurIPS 2022期间,事情以难以置信的速度开始改变。随着我们进入2024年,我想分享一些反思:
首先,人工智能领域的发展速度令人难以置信。并且它是在科技行业动荡的时期开始的。我发现这种组合既令人兴奋又相当令人畏惧。后者有时严重影响了我的动力。我没有找到完美的解决方案,但我注意到,定期与周围的人交谈极大地帮助了我。这虽然耗时,但帮助我忽略了噪音,专注于正确的项目,并更有动力。
其次,这也意味着研究项目的快速变化或进步以及对产品的更多关注。我必须学会如何总结正在进行的项目,并找出向前迈进时哪些项目是重要的。总结我们在不确定的真实性基础上的工作主要意味着在团队间协调人员,而合作者已经在继续前进。这是一个很好的领导机会,能看到我们的工作成果出现真的很棒。决定接下来要从事哪个项目也很有挑战性,因为它需要弄清楚未来哪些是重要的。幸运的是,我们的团队负责了SynthID。这是一个在负责任的AI领域的伟大的大规模项目。
然而,SynthID需要不同的工程和沟通技能。首先,我们在(健壮的)评估上投入了难以置信的努力——比我在博士期间习惯的多得多。这需要大量的工具,思考可重复性和文档记录。沟通也从更高层次的研究导向的谈话和会议,变成了更技术和工程重的讨论,有时专注于特定的代码更改。
最后,我更加重视社区,成为GDM奖学金导师,对学生和其他联系我的人更加容易接近,并且查看@londonai、@weights_biases和@StabilityAI在伦敦举办的一些与AI相关的活动。例如,在@NeurIPSConf期间,我安排了大量的一对一时间段,并在一周内遇到了很多了不起的人。
OpenBMB发布一系列边缘模型,包括接近Mistral 7B的2.4B基础模型

https://x.com/osanseviero/status/1753174397995626904?s=20
OpenBMB,UltraFeedback的创造者,悄然发布了一系列非常强大的边缘模型!
•接近Mistral 7B的2.4B基础模型
•在MT Bench上表现超越Llama 70B的2.4 DPO
•一个3B双语VLLM(+12B版本RLHF VLLM)
在https://huggingface.co/openbmb查看模型
Jim Fan:机器人学是一个负担重重的领域,有太多设计不良的软件、算法补丁和过时的思维模式
https://x.com/DrJimFan/status/1753115179989217778?s=20
机器人学是一个负担重重的领域。有太多设计不良的软件、算法补丁和过时的思维模式。
基础模型的发展将会是缓慢的,然后在你意识到之前一下子全面到来,一劳永逸地埋葬这些遗留问题。就像ChatGPT用一次干净的切割,削减了数十年的自然语言处理技术栈一样。
SwarmBrain: 通过大语言模型在实时战略游戏《星际争霸II》中实现具身智能体

链接:http://arxiv.org/abs/2401.17749v1
大语言模型(LLM)在各种探索性任务中取得了显著进展,甚至超过了历史上主导智能体领域的传统强化学习方法的表现。本文旨在研究LLM在StarCraft II游戏环境中执行实时战略任务的效果。在本文中,我们介绍了SwarmBrain,这是一个利用LLM实现StarCraft II游戏环境中实时战略的具体体现智能体。SwarmBrain包括两个关键组件:1)Overmind Intelligence Matrix,由最先进的LLM驱动,旨在从高层次的角度协调宏观策略。该矩阵模拟Zerg智能大脑的整体意识,将战略远见与资源分配、扩张指导和协调多方进攻进行综合。2)Swarm ReflexNet是Overmind Intelligence Matrix计算思考的敏捷对应体。由于LLM推理的固有延迟,Swarm ReflexNet采用了条件-响应状态机框架,实现对基本Zerg单位操作的迅速战术响应。在实验设置中,SwarmBrain控制着与电脑控制的Terran对手对抗的Zerg种族。实验结果显示SwarmBrain实现了经济增长、领土扩张和战术制定的能力,并且能够在不同难度级别下击败电脑玩家取得胜利。
GPTGuard

https://www.gptguard.ai/
GPTGuard是一个保护数据隐私和安全的 AI 工具。它的作用类似于一个虚拟盾牌,可以在将数据发送到人工智能模型之前,自动擦除其中的敏感信息,从而确保数据的隐私和安全性。该工具的目标是通过更智能、更自动化的方式来处理数据隐私和安全问题,为用户提供保护。
Flipner AI
https://www.flipner.com/?ref=producthunt
Flipner 是一款 AI 写作工具,帮助社交媒体、频道内容创作者以及博客或媒体专栏作者撰写原创文章。它可以通过收集用户的笔记(语音或文本形式)并以所需的风格、格式和语气生成文章、帖子或其他文本。设计这款工具的初衷是为了解决传统生成式 AI 写作工具存在的问题,即缺乏意义和逻辑性。Flipner 试图将人类的想法和意义与人工智能的快速写作能力结合起来,以提供更加有意义和实用的文本输出。
MoE-LLaVA
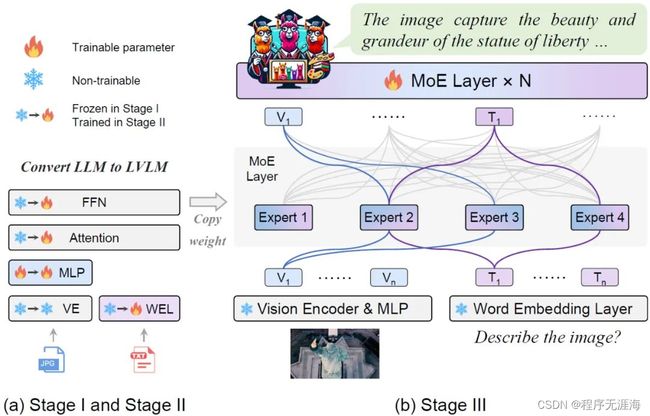
https://github.com/PKU-YuanGroup/MoE-LLaVA
来自北京大学、中山大学等机构的研究者联合提出了一种新颖的 LVLM 训练策略 ——MoE-Tuning。该研究还提出了一种基于 MoE 的新型稀疏 LVLM 架构 ——MoE-LLaVA 框架。该框架独特地在部署过程中通过路由算法仅激活 top-k 专家(expert),其余专家保持非活动(inactive)状态。MoE-LLaVA 的 GitHub 更新了,大家可以从代码层进一步研究。