从GNN到GCN(1)--传统GCN和基于空域的MPNN及GraphSage
1. 前言
图神经网络的最大优势在于可以处理传统神经网络比如RNN和CNN无法处理的具有复杂结构的数据类型,诸如分子结构化合物特性判断或物理模型模型构建的子任务。同时因为图数据包含十分丰富的关系型信息,可以从文本,图像这些非结构化数据中进行推理学习。
卷积操作作为非常高效的局部特征提取手段如果可以作用于图神经网络可以高效的处理大量关系型信息
2.图卷积的缘起
应用传统卷积的欧氏空间和非欧氏空间的区别
首先从一张图来直观的感受传统卷积的作用
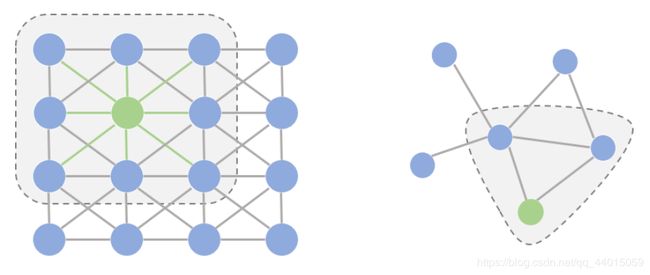
从图中我们可以发现两者的区别
- 在图像为代表的欧式空间中,结点的邻居数量都是固定的。比如说绿色结点的邻居始终是8个(边缘上的点可以做Padding填充)。但在图这种非欧空间中,结点有多少邻居并不固定。目前绿色结点的邻居结点有2个,但其他结点也会有5个邻居的情况。
- 欧式空间中的卷积操作实际上是用固定大小可学习的卷积核来抽取像素的特征,比如这里就是抽取绿色结点对应像素及其相邻像素点的特征。但是因为图里的邻居结点不固定,所以传统的卷积核不能直接用于抽取图上结点的特征。
因此从GNN到GCN转换的真正难点聚焦于邻居节点数量不固定上。目前主流的研究从2条路来解决:
- 提出一种方式把非欧空间的图转换成欧式空间
- 找出一种可处理变长邻居结点的卷积核在图上抽取特征。
图卷积的本质就是想找到适用于图数据结构特征的可学习的卷积核
3.图卷积框架
如下图所示,输入的是整张图,在Convolution Layer 1里,对每个结点的邻居都进行一次卷积操作,并用卷积的结果更新该结点;然后经过激活函数如ReLU,然后再过一层卷积层Convolution Layer 2与一层激活函数;反复上述过程,直到层数达到预期深度。与GNN类似,图卷积神经网络也有一个局部输出函数,用于将结点的状态(包括隐藏状态与结点特征)转换成任务相关的标签,比如水军账号分类,本文中笔者称这种任务为Node-Level的任务;也有一些任务是对整张图进行分类的,比如化合物分类,本文中笔者称这种任务为Graph-Level的任务。卷积操作关心每个结点的隐藏状态如何更新,而对于Graph-Level的任务,它们会在卷积层后加入更多操作。
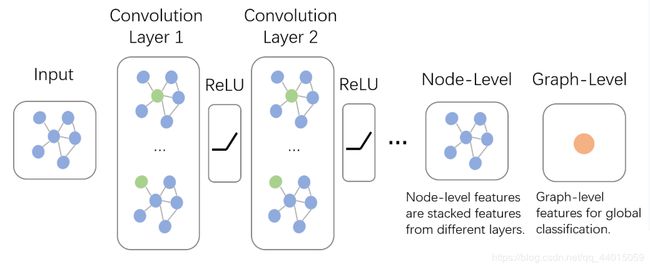
GCN与GNN乍看好像还挺像的。但是本质上是完全不同的:GCN是多层堆叠,比如上图中的Layer 1和Layer 2的参数是不同的;GNN是迭代求解,可以看作每一层Layer参数是共享的。
4.卷积(Convolution)
图卷积神经网络主要有两类,一类是基于空域的,另一类则是基于频域的。通俗点解释,空域可以类比到直接在图片的像素点上进行卷积,而频域可以类比到对图片进行傅里叶变换后,再进行卷积。
-
基于空域卷积的方法直接将卷积操作定义在每个结点的连接关系上,它跟传统的卷积神经网络中的卷积更相似一些。在这个类别中比较有代表性的方法有
Message Passing Neural Networks(MPNN), GraphSage, Diffusion
Convolution Neural Networks(DCNN), PATCHY-SAN等。 -
基于频域卷积的方法则从图信号处理起家,包括 Spectral CNN, Cheybyshev Spectral
CNN(ChebNet), 和 First order of ChebNet(1stChebNet)等。
此篇文章主要介绍基于空域的前两种代表性方法MPNN和GraphSage
5.空域卷积(Spatial Convolution)
空域卷积(Spatial Convolution)。从设计理念上看,空域卷积与深度学习中的卷积的应用方式类似,其核心在于聚合邻居结点的信息。比如说,一种最简单的无参卷积方式可以是:将所有直连邻居结点的隐藏状态加和,来更新当前结点的隐藏状态。

这里非参式的卷积只是为了举一个简单易懂的例子,实际上图卷积在建模时需要的都是带参数、可学习的卷积核。
6.消息传递网络(Message Passing Neural Network)
消息传递网络(MPNN)是由Google科学家提出的一种模型。严格意义上讲,MPNN不是一种具体的模型,而是一种空域卷积的形式化框架。它将空域卷积分解为两个过程:消息传递与状态更新操作,分别由 M l ( ⋅ ) M_l(⋅) Ml(⋅)和 U l ( ⋅ ) U_l(⋅) Ul(⋅)函数完成。将结点 v v v的特征 x v x_v xv作为其隐藏状态的初始态 h v 0 h^0_v hv0后,空域卷积对隐藏状态的更新由如下公式表示:
 其中 l l l代表图卷积的第 l l l层,上式的物理意义是:收到来自每个邻居的的消息 M l + 1 M_{l+1} Ml+1后,每个结点如何更新自己的状态。
其中 l l l代表图卷积的第 l l l层,上式的物理意义是:收到来自每个邻居的的消息 M l + 1 M_{l+1} Ml+1后,每个结点如何更新自己的状态。
该公式可能与GGNN的公式很想,实际上,它们是两种截然不同的方式:GCN中通过级联的层捕捉邻居的消息,GNN通过级联的时间来捕捉邻居的消息;前者层与层之间的参数不同,后者可以视作层与层之间共享参数。MPNN的示意图如下

7.图采样与聚合(Graph Sample and Aggregate)
MPNN很好地概括了空域卷积的过程,但定义在这个框架下的所有模型都有一个共同的缺陷:卷积操作针对的对象是整张图,也就意味着要将所有结点放入内存/显存中,才能进行卷积操作。但对实际场景中的大规模图而言,整个图上的卷积操作并不现实。GraphSage[2]提出的动机之一就是解决这个问题。从该方法的名字我们也能看出,区别于传统的全图卷积,GraphSage利用采样(Sample)部分结点的方式进行学习。当然,即使不需要整张图同时卷积,GraphSage仍然需要聚合邻居结点的信息,即论文中定义的aggregate的操作。这种操作类似于MPNN中的消息传递过程。
GraphSAGE的核心:GraphSAGE不是试图学习一个图上所有node的embedding,而是学习一个为每个node产生embedding的映射
文中不是对每个顶点都训练一个单独的embeddding向量,而是训练了一组aggregator functions,这些函数学习如何从一个顶点的局部邻居聚合特征信息。每个聚合函数从一个顶点的不同的hops或者说不同的搜索深度聚合信息。测试或是推断的时候,使用训练好的系统,通过学习到的聚合函数来对完全未见过的顶点生成embedding。

GraphSAGE是Graph Sample and aggreGatE的缩写,其运行流程如上图所示,可以分为三个步骤
- 对图中每个顶点的邻居节点进行采样,因为每个结点的度是不一样的,为了计算高效,为每个结点采样固定数量的邻居
- 根据聚合函数聚合邻居节点所蕴含的信息
- 得到图中参考了邻居节点信息的顶点向量表示供下游任务使用
文中设计了无监督的损失函数,使得GraphSAGE可以在没有任务监督的情况下训练。实验中也展示了使用完全监督的方法如何训练GraphSAGE。
7.1Embedding generationalgorithm (生成节点embedding的前向传播算法)
GraphSAGE的前向传播算法如下,前向传播描述了如何使用聚合函数对节点的邻居信息进行聚合,从而生成节点embedding:
伪代码中存在一个问题就是第四行聚合后应该得到的是 k − 1 k-1 k−1层的邻居结点的特征表示
 在每次迭代的过程中,顶点从它们的局部邻居聚合信息,并且随着这个过程的迭代,顶点会从越来越远的地方获得信息
在每次迭代的过程中,顶点从它们的局部邻居聚合信息,并且随着这个过程的迭代,顶点会从越来越远的地方获得信息
算法描述了在整个图上生成embedding的过程,其中
- G = ( V , E ) G=(V,E) G=(V,E)表示一个图
- K K K是网络的层数,也代表着每个顶点能够聚合的邻接点的层数,每增加一层,可以聚合更远的一层邻居的信息
- x v , ∀ v ∈ V x_v,∀v∈V xv,∀v∈V表示结点 v v v的特征向量作为输入(注意这里是全部的结点)
- h u k − 1 , ∀ u ∈ N ( v ) {h_u^{k−1} ,∀u∈N(v)} huk−1,∀u∈N(v)表示在 k − 1 k-1 k−1层中结点 v v v的邻居结点 u u u的embedding
- h N ( v ) k h_{N(v)}^k hN(v)k表示在第 k k k层,结点 v v v的所有邻居节点的特征表示
- h v k , ∀ v ∈ V h_v^k,∀v∈V hvk,∀v∈V表示在第 k k k层,结点 v v v的特征表示
- N ( v ) N(v) N(v)定义为从集合 u ∈ v : ( u , V ) ∈ E u ∈ v : ( u , V ) ∈ E u ∈ v : ( u , V ) ∈ E {u∈v:(u,V)∈Eu \in v: (u, \mathcal{V}) \in \mathcal{E}u∈v:(u,V)∈E} u∈v:(u,V)∈Eu∈v:(u,V)∈Eu∈v:(u,V)∈E中的固定size的均匀取出
即GraphSAGE中每一层的节点邻居都是是从上一层网络采样的,并不是所有邻居参与,并且采样的后的邻居的size是固定的
在解释完符号信息,具体看一下算法的流程是什么。
Neighborhood definition - 采样邻居顶点
出于对计算效率的考虑,对每个顶点采样一定数量的邻居顶点作为待聚合信息的顶点。设需要的邻居数量,即采样数量为 S S S,若顶点邻居数少于 S S S,则采用有放回的抽样方法,直到采样出 S S S个顶点。若顶点邻居数大于 S S S,则采用无放回的抽样。(即采用有放回的重采样/负采样方法达到 S S S)
当然,若不考虑计算效率,完全可以对每个顶点利用其所有的邻居顶点进行信息聚合,这样是信息无损的。
统一采样一个固定大小的邻域集,以保持每个batch的计算占用空间是固定的(即 graphSAGE并不是使用全部的相邻节点,而是做了固定size的采样)。
这样固定size的采样,每个节点和采样后的邻居的个数都相同,可以把每个节点和它们的邻居拼成一个batch送到GPU中进行批训练。
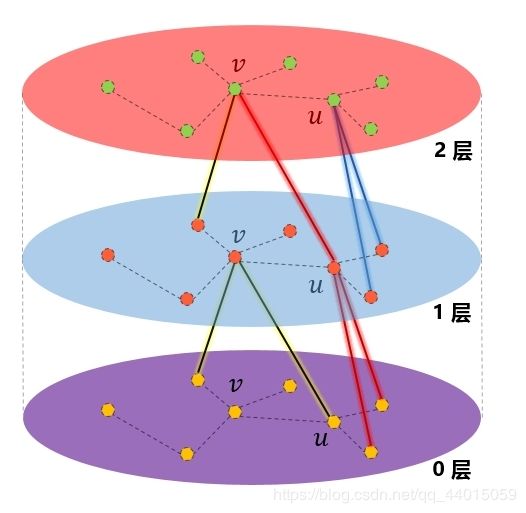
- 算法中 k k k从1开始循环,因此看第一层。 v v v是我们选取的顶点,在这里我们设置采样邻居节点的数量为2和采样邻居的阶数也为2.根据算法流程,我们可以获得第一层的 h N ( v ) 0 h_{N(v)}^0 hN(v)0(由第0层随机选取的顶点 v v v的两个邻居获得)。与此同时 v v v的邻居 u u u根据分布特征也聚合了第0层的两个邻居信息
- 因此我们可以分别获取第一层中 v v v和 u u u的特征信息(由第0层 v v v和 u u u的两个邻居特征信息和第0层的 v v v和 u u u的特征信息之和所得到)
实际上我们可以看出第 k k k层目标顶点的特征向量就是由第 k − 1 k-1 k−1层的目标顶点和邻居顶点的特征向拼接后经过某种操作生成的 - 到了第2层,可以看到节点 v v v通过“1层”的节点u和另一邻居得到了第1层 v v v的邻居节点信息,其中借助 u u u扩展到了“0层”的二阶邻居节点。因此,在聚合时,聚合K次,就可以扩展到K阶邻居。
第二层仍然满足我们总结的规律,只是在此时 k − 1 k-1 k−1层的邻居顶点包含了 k − 2 k-2 k−2层的邻居顶点,也就达到了扩展到 k k k阶邻居的目的 - 实验发现,K不必取很大的值,当K=2时,效果就很好了。至于邻居的个数,文中提到 S 1 ⋅ S 2 ≤ 500 S1⋅S2≤500 S1⋅S2≤500即两次扩展的邻居数之际小于500,大约每次只需要扩展20来个邻居时获得较高的性能。
- 论文里说固定长度的随机游走其实就是随机选择了固定数量的邻居
7.2聚合函数的选取
在图中顶点的邻居是无序的,所以希望构造出的聚合函数是对称的(即也就是对它输入的各种排列,函数的输出结果不变),同时具有较高的表达能力。 聚合函数的对称性(symmetry property)确保了神经网络模型可以被训练且可以应用于任意顺序的顶点邻居特征集合上。
Mean aggregator
mean aggregator将目标顶点和邻居顶点的第 k − 1 k−1 k−1层向量拼接起来,然后对向量的每个维度进行求均值的操作,将得到的结果做一次非线性变换产生目标顶点的第 k k k层表示向量。
文中用下面的式子替换算法1中的4行和5行得到GCN的inductive变形
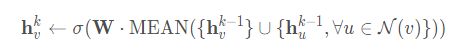 原始第4,5行是
原始第4,5行是
 文中称这个修改后的基于均值的聚合器是convolutional的,这个卷积聚合器和文中的其他聚合器的重要不同在于它没有算法1中第5行的CONCAT操作可以看到替换后,是对 h v k − 1 h^{k−1}_v hvk−1和集合 { h u k − 1 , ∀ u ∈ N ( v ) } \left\{\mathbf{h}_{u}^{k-1}, \forall u \in \mathcal{N}(v)\right\} {huk−1,∀u∈N(v)}取并集,然后一起算均值,再乘上权重
文中称这个修改后的基于均值的聚合器是convolutional的,这个卷积聚合器和文中的其他聚合器的重要不同在于它没有算法1中第5行的CONCAT操作可以看到替换后,是对 h v k − 1 h^{k−1}_v hvk−1和集合 { h u k − 1 , ∀ u ∈ N ( v ) } \left\{\mathbf{h}_{u}^{k-1}, \forall u \in \mathcal{N}(v)\right\} {huk−1,∀u∈N(v)}取并集,然后一起算均值,再乘上权重
LSTM aggregator
文中也测试了一个基于LSTM的复杂的聚合器[Long short-term memory]。和均值聚合器相比,LSTMs有更强的表达能力。但是,LSTMs不是symmetric的,也就是说不具有排列不变性(permutation invariant),因为它们以一个序列的方式处理输入。因此,需要先对邻居节点随机顺序,然后将邻居序列的embedding作为LSTM的输入。
Pooling aggregator
pooling聚合器,它既是对称的,又是可训练的。Pooling aggregator 先对目标顶点的邻居顶点的embedding向量进行一次非线性变换,之后进行一次pooling操作(max pooling or mean pooling),将得到结果与目标顶点的表示向量拼接,最后再经过一次非线性变换得到目标顶点的第k层表示向量。
一个element-wise max pooling操作应用在邻居集合上来聚合信息:
 其中
其中
- max表示element-wise最大值操作,取每个特征的最大值
- σ σ σ是非线性激活函数
- 所有相邻节点的向量共享权重,先经过一个非线性全连接层,然后做max-pooling
- 按维度应用 max/mean pooling,可以捕获邻居集上在某一个维度的突出的/综合的表现。
7.3Learning the parameters of GraphSAGE (有监督和无监督)参数学习
在定义好聚合函数之后,接下来就是对函数中的参数进行学习。文章分别介绍了无监督学习和监督学习两种方式。
基于图的无监督损失
无监督损失函数的设定来学习结点embedding可以供下游多个任务使用。监督学习形式根据任务的不同直接设置目标函数即可,如最常用的节点分类任务使用交叉熵损失函数
参数学习
通过前向传播得到节点 u u u的embedding z u z_u zu,然后梯度下降(实现使用Adam优化器) 进行反向传播优化参数 W k W^k Wk和聚合函数内的参数
新节点embedding的生成
这个 W k W^k Wk就是所谓的dynamic embedding的核心,因为保存下来了从节点原始的高维特征生成低维embedding的方式。现在,如果想得到一个点的embedding,只需要输入节点的特征向量,经过卷积(利用已经训练好的 W k W^k Wk 以及特定聚合函数聚合neighbor的属性信息),就产生了节点的embedding。