Python爬虫之正则的基础应用
- 1. 正则表达式基础
- 2. 正则表达式实战
- 2.1 实战任务
- 2.2 实战准备
- 2.3 校花网实战
1. 正则表达式基础
正则基础入门学习笔记,补充:
- 贪婪模式:.*
- 非贪婪(惰性)模式:.*?
2. 正则表达式实战
2.1 实战任务
使用正则进行图片数据的批量解析,从而获取图片链接,然后爬取图片
2.2 实战准备
浏览器:火狐浏览器 ;编程软件:Jupyter notebook
爬取图片数据的方法
- requests方法
- urllib方法
搜索【风景】,任意选择一张图片,复制其链接
import requests,urllib
url = "https://ss3.bdstatic.com/70cFv8Sh_Q1YnxGkpoWK1HF6hhy/it/u=3776743316,693392609&fm=26&gp=0.jpg"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:77.0) Gecko/20100101 Firefox/77.0"}
# requests方法爬取图片
response = requests.get(url=url,headers=headers)
img_data = response.content # content返回二进制的响应数据,即bytes数据
with open("1.jpg",'wb') as fp:
fp.write(img_data)
print("程序执行完毕")
程序执行完毕
# 查看获取的图片
import matplotlib.pyplot as plt
# 如果不添加该行,则每次显示图片都需要加上plt.show
%matplotlib inline
plt.imshow(plt.imread("1.jpg"))

# urllib方法爬取图片
urllib.request.urlretrieve(url,filename="2.jpg")
print("程序执行完毕")
程序执行完毕
plt.imshow(plt.imread("2.jpg"))

urllib与requests的不同之处:
- urllib无法进行UA伪装,但是比较简单
- requests可以UA伪装,过程较为复杂
分析浏览器开发工具中的Elements和Network这两个对应页面的数据有何不同之处:
- Elements中包含的显示的页面源数据为当前页面所有的数据加载完毕后所对应的的完整网页源码数据(其中包含了动态加载数据)
- Network中显示的页面源码数据仅仅为某一个单独得的请求所对应的响应数据(不包含动态加载数据)
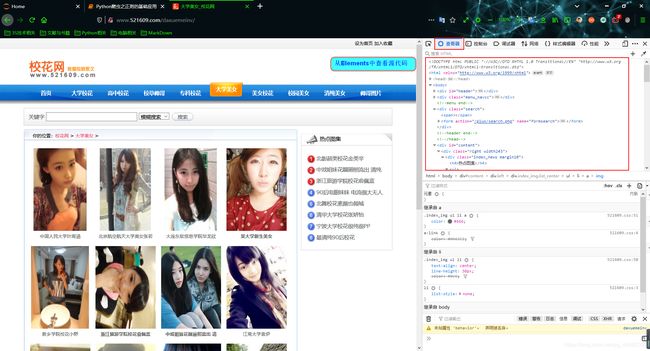
因此,我们在进行数据解析时,需要对页面进行布局分析,如果当前网站没有动态加载的数据就可以直接视同Elements对页面布局进行分析,否则只可以使用network对页面数据进行分析。
2.3 校花网实战
- 目标:爬取校花网中的图片数据
- 目标网站:http://www.521609.com/daxuemeinv/
- 流程:获取每一张图片的地址,然后对图片地址发起请求
import requests
url = "http://www.521609.com/daxuemeinv/"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:77.0) Gecko/20100101 Firefox/77.0"}
# 1.获取网页源代码,这里由于是静态的,Network与Elements获取的网页一样的
page_text = requests.get(url=url,headers=headers).text
分析源代码数据,从而得到正则表达式
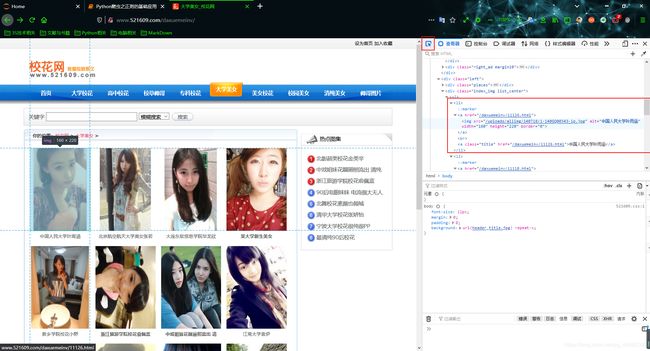
# 2. 从获取的网页源代码通过正则
import re
ex = '.*?) '
img_src_list = re.findall(ex,page_text,re.S) # re.S 处理需要换行的数据
'
img_src_list = re.findall(ex,page_text,re.S) # re.S 处理需要换行的数据
# 查看获取的图片地址
img_src_list
['/uploads/allimg/140718/1-140GQ00343-lp.jpg',
'/uploads/allimg/130416/1-130416102350-lp.jpg',
'/uploads/allimg/130412/1-130412094244-lp.jpg',
'/uploads/allimg/130410/1-130410112118.jpg',
'/uploads/allimg/130403/1-130403100226-lp.jpg',
'/uploads/allimg/130402/1-130402164H6.jpg',
'/uploads/120308/1_140619600.jpg',
'/uploads/allimg/120105/11254364X4-1-lp.jpg',
'/uploads/allimg/111115/11010324Z7-1-lp.jpg',
'/uploads/allimg/111111/112001N394-1.jpg',
'/uploads/allimg/111104/11033324a1-1-lp.jpg',
'/uploads/allimg/111101/1110S62124-1-lp.jpg',
'/uploads/allimg/111009/1100GNI4-5.jpg',
'/uploads/allimg/111006/1103953J43-1.jpg',
'/uploads/allimg/110914/1003ZQ3E-1-lp.jpg',
'/uploads/allimg/110812/122045aJ0-1-lp.jpg']
# 3. 获取并保存数据
import os
dirName = "IMG" # 用于创建文件夹名
if not os.path.exists(dirName):
os.mkdir(dirName)
# 上述图片地址并没有加上域名,因此需要加上域名
for i in img_src_list:
src = "http://www.521609.com" + i
# 保存的地址及图名
img_path = dirName + "/" + src.split("/")[-1]
urllib.request.urlretrieve(src,img_path)
print(img_path,"下载成功")
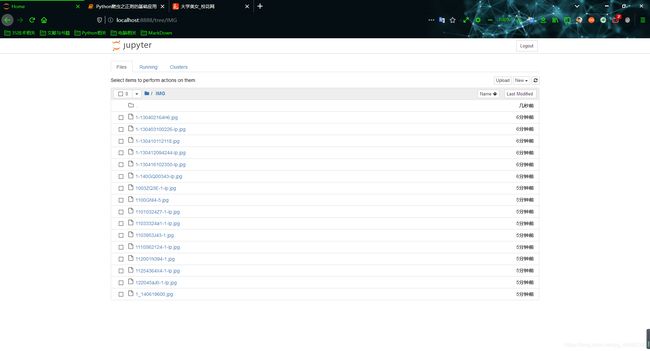
print("执行完毕")
IMG/1-140GQ00343-lp.jpg 下载成功
IMG/1-130416102350-lp.jpg 下载成功
IMG/1-130412094244-lp.jpg 下载成功
IMG/1-130410112118.jpg 下载成功
IMG/1-130403100226-lp.jpg 下载成功
IMG/1-130402164H6.jpg 下载成功
IMG/1_140619600.jpg 下载成功
IMG/11254364X4-1-lp.jpg 下载成功
IMG/11010324Z7-1-lp.jpg 下载成功
IMG/112001N394-1.jpg 下载成功
IMG/11033324a1-1-lp.jpg 下载成功
IMG/1110S62124-1-lp.jpg 下载成功
IMG/1100GNI4-5.jpg 下载成功
IMG/1103953J43-1.jpg 下载成功
IMG/1003ZQ3E-1-lp.jpg 下载成功
IMG/122045aJ0-1-lp.jpg 下载成功
查看保存的结果:
 【学习参考链接(这个爬虫教程真心不错)】
【学习参考链接(这个爬虫教程真心不错)】