hive sql常用函数
1. MONTHS_BETWEEN函数
MONTHS_BETWEEN (x, y)用于计算x和y之间有几个月。如果x在日历中比y早,那么MONTHS_BETWEEN()就返回一个负数
SELECT MONTHS_BETWEEN('2008-05-05', '2008-04-05') FROM dual-----------------------------------------1
2. CASE WHEN THEN ELSE函数
Case具有两种格式。简单Case函数和Case搜索函数。
简单Case函数
--CASE sex
WHEN '1' THEN '男'
WHEN '2' THEN '女'
ELSE '其他' END
--Case搜索函数
CASE WHEN sex = '1' THEN '男'
WHEN sex = '2' THEN '女'
ELSE '其他' END
这两种方式,可以实现相同的功能。简单Case函数的写法相对比较简洁,但是和Case搜索 函数相比,功能方面会有些限制,比如写判断式。
还有一个需要注意的问题,Case函数只返回第一个符合条件的值,剩下的Case部分将会被 自动忽略。
3. CAST 函数
CAST函数语法规则是:Cast(字段名 as 转换的类型 ),其中类型可以为:
CHAR[(N)] 字符型
DATE 日期型
DATETIME 日期和时间型
DECIMAL float型
SIGNED int
TIME 时间型
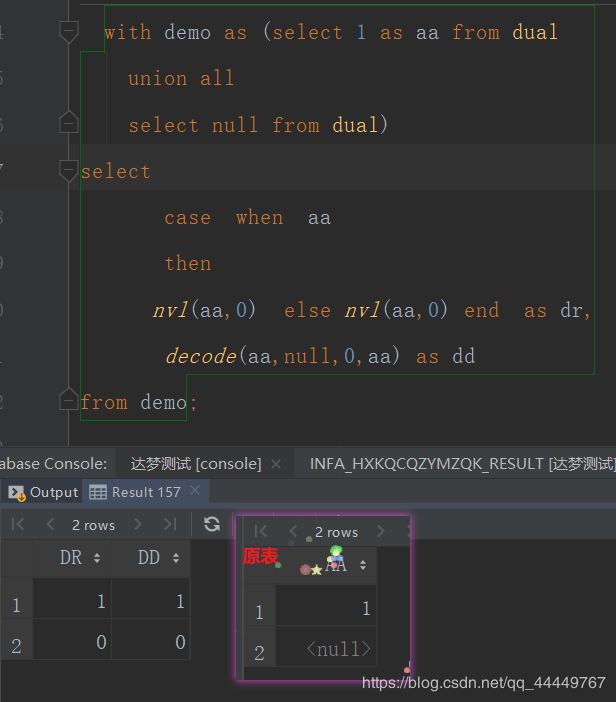
4. NVL()函数
1.NVL函数的格式如下:NVL(expr1,expr2)
含义是:如果oracle第一个参数为空那么显示第二个参数的值,如果第一个参数的值不为 空,则显示第一个参数本来的值。
2.NVL2函数的格式如下:NVL2(expr1,expr2, expr3)
含义是:如果该函数的第一个参数为空那么显示第二个参数的值,如果第一个参数的值不为空,则显示第三个参数的值。SQL> select ename,NVL2(comm,-1,1) from emp;
3.NULLIF(exp1,expr2)函数的作用是如果exp1和exp2相等则返回空(NULL),否则返回第一个值。
4.Coalesce(expr1, expr2, expr3….. exprn)
表示可以指定多个表达式的占位符。所有表达式必须是相同类型,或者可以隐性转换为相同的类型。
返回表达式中第一个非空表达式,如有以下语句: SELECT COALESCE(NULL,NULL,3,4,5) FROM dual 其返回结果为:3
如果所有自变量均为 NULL,则 COALESCE 返回 NULL 值。 COALESCE(expression1,...n) 与此 CASE 函数等价:
5. UNION函数
说明:union函数是行级连接,增加行数
例如:(不包括重复的)
select * from student_drb where bno=1
union
select * from student_drb where bno=4
此结果是将select * from student_drb where bno=4查出的结果合并到
select * from student_drb where bno=1结果下面
6. UNION ALL
insert overwrite table TABLE_NAME
select X from ...
union all
select X from ...;
-- 表示:将多个查询的结果合并,表中的数据都罗列出来(包括重复的)
-- 注:"X"的位置必须相同
7. 时间戳转化
在sql查询时将日期转为时间戳
NOW():当前日期时间
SELECT UNIX_TIMESTAMP(NOW());
将日期格式转成时间戳 1493016522
SELECT UNIX_TIMESTAMP(create_time);
在sql查询时将时间戳转为日期
SELECT FROM_UNIXTIME(1493016148);
将时间戳转成日期格式 2017-04-24 14:42:28
8. TIMESTAMP
1、current_date
-- 表示:当前日期,yyyy-MM-dd
2、current_time
-- 表示:当前时间,HH:mm:ss
3、current_timestamp
-- 表示:返回当前UTC时间(GMT+0)的时间戳,小于北京时间8小时,就是日期时间yyyy-MM-dd HH:mm:ss
4、unix_timestamp()
4.1、unix_timestamp()
-- 得到当前时间戳.
4.2、unix_timestamp(string date)
-- 如果参数date满足yyyy-MM-dd HH:mm:ss形式,则可以直接 得到参数对应的时间戳.
-- 如果参数date不满足yyyy-MM-dd HH:mm:ss形式,则我们需要指定date的形式,再进行转换
如:unix_timestamp(‘2009-03-20’, ‘yyyy-MM-dd’)=1237532400
5、from_unixtime(unix_timestamp,format)
-- 表示:返回表示 Unix 时间标记的一个字符串,根据format字符串格式化。
语法:from_unixtime(t1,’yyyy-MM-dd HH:mm:ss’)
其中t1是10位的时间戳值,即1970-1-1至今的秒,而13位的所谓毫秒的是不可以的。
对于13位时间戳,需要截取,然后转换成bigint类型,因为from_unixtime类第一个参数只接受bigint类型。 例如:
from_unixtime(cast(substring(tistmp,1,10) as bigint),’yyyy-MM-dd HH’)
9. IN函数
in 操作符:
SELECT * FROM table1 WHERE age1 IN(11,1);
查询来自表哥table1的数据,条件为age1 在(11,1)这两个数之中,其中in的意思就是说查询的数据在什么之中。那么我们这样使用in就可以查询age1为11和1的数据了。
注意:
(1)在使用IN 和 NOT IN 时要注意 IN范围中有NULL和空值的情况
(2)尽量不要用IN和NOT IN的方式而是转换为LEFT JOIN的形式
(3)在where语句中考虑NULL的同时要考虑空字符串的情况
10. SUBSTR和SUBSTRING区别
两者都是截取字符串。
1.相同点:如果只是写一个参数,两者的作用都一样:都是是截取字符串从当前下标以后直到 字符串最后的字符串片段
var str = '123456789';
console.log(str.substr(2)); // "3456789"
console.log(str.substring(2)) ;// "3456789"
2.不同点:第二个参数
substr(startIndex,lenth): 第二个参数是截取字符串的长度(从起始点截取某个长度的字符串);
substring(startIndex, endIndex): 第二个参数是截取字符串最终的下标 (截取2个位置之间的字符串,‘含头不含尾’)。
例子1:
console.log("123456789".substr(2,5)); // "34567"
console.log("123456789".substring(2,5)) ;// "345"
例子2:
var a="abcdefghiklmnopqrstuvwxyz";
var b=a.substr(3,5);
var c=a.substring(3,5);
打印输出的结果是:
defgh
de
注意最后5下标是不会取到的意思是只能截取a字符串的3,4下标
截取的时候是不会截取到最后一个[3,5)
String.substr(startIndex,lenth) 这个是我们常用的从指定的位置(startIndex)截取指定长度(lenth)的字符串; String.substring(startIndex, endIndex) 这个是startIndex,endIndex里找出一个较小的值,然后从字符串的开始位置算起,截取较小值位置和较大值位置之间的字符串,截取出来的字符串的长度为较大值与较小值之间的差。
11. WITH 连接词
with TABLE_NAME AS (
SELECT ... FROM ... WHERE ...
)
-- 首个连接需要with,后续不要with:
TABLE_NAME AS (
SELECT ... FROM ... WHERE ...
12. ROW_NUMBER() over(partition by A order by B asc/desc)
row_number() over(partition by A order by B asc/desc)
-- 将查询结果按照A字段分组(partition),
-- 然后组内按照B字段排序,至于asc还是desc,可自行选择,
-- 然后为每行记录返回一个row_number用于标记顺序(编号)
特色功能:给 已有hive表(dm.official_accounts_funscount_w) 添加一列序号(sample_key),例:
select
row_number() over(
partition by case when t.source is not null then 1 end
order by t.source asc,t.funCounts desc
) as sample_key,
t.source,
t.cityName,
t.weight,
t.strArea,
t.end_date,
t.funCounts
from dm.official_accounts_funscount_w t;
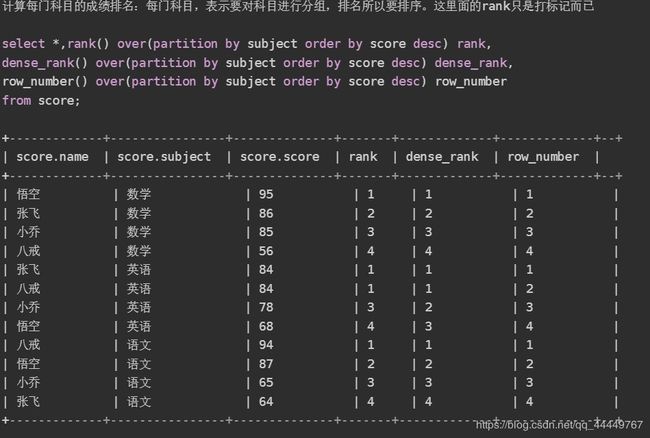
13. Row number 和RANK 和DENSE区别
RANK() 排序相同时会重复,总数不会变
DENSE_RANK() 排序相同时会重复,总数会减少
ROW_NUMBER() 会根据顺序计算
14. CONCAT(a,b) 和concat_ws
1.concat('hello_','world')
-- 将a字符串与b字符串拼接 ==>('hello_world')
concat函数在连接字符串的时候,只要其中一个是NULL,那么将返回NULL
hive> select concat('a','b');
OK
ab
Time taken: 0.477 seconds, Fetched: 1 row(s)
hive> select concat('a','b',null);
OK
NULL
Time taken: 0.181 seconds, Fetched: 1 row(s)
2.concat_ws函数在连接字符串的时候,只要有一个字符串不是NULL,就不会返回NULL。concat_ws函数需要指定分隔符。
hive> select concat_ws('-','a','b');
OK
a-b
Time taken: 0.245 seconds, Fetched: 1 row(s)
hive> select concat_ws('-','a','b',null);
OK
a-b
Time taken: 0.177 seconds, Fetched: 1 row(s)
hive> select concat_ws('','a','b',null);
OK
ab
Time taken: 0.184 seconds, Fetched: 1 row(s)
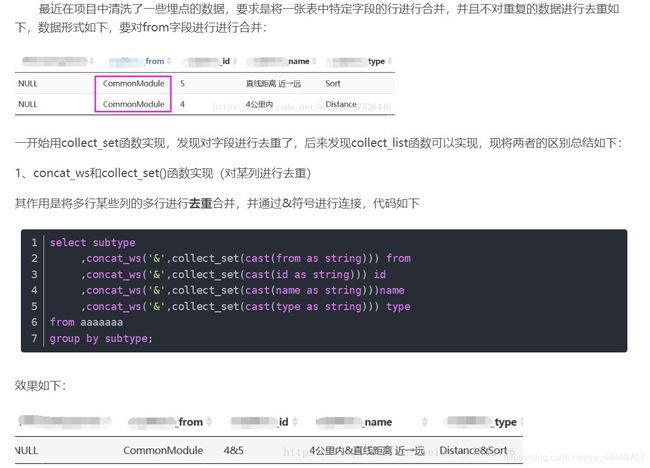
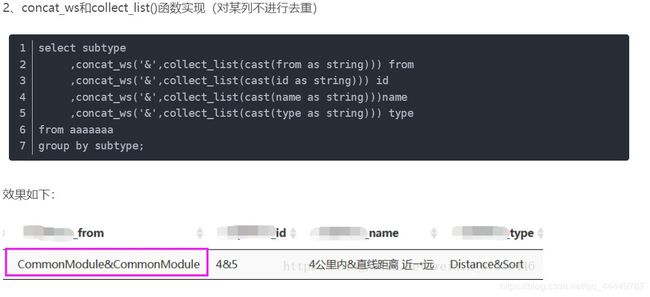
15. Collect_set和Collect_list函数
16. OVERWRITE与INTO
insert overwrite table TABLE_NAME;
-- 表示:删除原有数据然后在新增数据,如果有分区那么只会删除指定分区数据,其他分区数据不受影响。
insert into table TABLE_NAME;
-- 表示:在原有数据的基础上增加数据
17. DECIMAL
decimal(38,2)
-- 表示:计算结果保留有效位38位,小数位2位
18. IF()
if("表达式",true,null)
-- 如果表达式成立,取参数true,否则取参数null
19. COALESCE
Coalesce(expr1, expr2, expr3….. exprn)
-- 表示:返回第一个非空参数(所有参数必须是相同类型,或可隐性转换为相同的类型)。
20. LEFT REGHT INNER join
sql的left join 、right join 、inner join之间的区别
-left join(左联接) 返回包括左表中的所有记录和右表中联结字段相等的记录
-right join(右联接) 返回包括右表中的所有记录和左表中联结字段相等的记录
-inner join(等值连接) 只返回两个表中联结字段相等的行
左连接:
select u.UserID,u.UserName,c.id,c.name
from t_user u left join t_class c on c.id = u.UserID
三表关联:
select table a left join table b(left join table c on b.id = c.tb_id) on a.id = b_ta.id
21. GROUP_CONCAT
使用GROUP_CONCAT合并列,使用distinct会去掉列里面重复的数据
SELECT GROUP_CONCAT(distinct main.relator_name SEPARATOR ';') AS relator_name,
GROUP_CONCAT(distinct main.law_investigation_situ SEPARATOR ';') AS law_investigation_situ,main.relator_type,
main.asset_id
from amc.
22. GROUP BY
group by语法可以根据给定数据列的每个成员对查询结果进行分组统计,最终得到一个分组汇总表。
SELECT子句中的列名必须为分组列或列函数。列函数对于GROUP BY子句定义的每个组各返回一个结果。
Group by 一般和聚合函数一起使用才有意义,比如 count sum avg等,使用group by的两个要素:
(1) 出现在select后面的字段 要么是聚合函数中的,要么是group by 中的.
(2) 要筛选结果 可以先使用where 再用group by 或者先用group by 再用having(having对group by进行条件帅选分组)
23. DISTINCT 去重
如何用distinct消除重复记录的同时又能选取多个字段值?
需求是:我要消除name字段值重复的记录,同时又要得到id字段的值,其中id是自增字段。
select distinct name from t1 能消除重复记录,但只能取一个字段,现在要同时 取id,name这2个字段的值。
select distinct id,name from t1 可以取多个字段,但只能消除这2个字段值全部相同的记录
最后解决方法:
SELECT id,name FROM t1 WHERE id IN(SELECT MAX(id) FROM t1 GROUP BY name) order by id desc
注意开头的 id 的 一定要,后面的order by 里有的字段一定要加进select 结果,要不然排序无效
注意:
1 .Distinct 位置
单独的distinct只能放在开头,否则报错,语法错误
2.与其他函数使用时候,没有位置限制如下
Select player_id,count(distinct(task_id))from task;
这种情况下是正确的,可以使用
24. WMSYS.WM_CONCAT()
函数可以实现行转列的效果

25. default SYS_GUID()
不重复字符设置函数

26. unpivot(透视,行专列)

值的数来自于id的字段,将id和zhi的行转化为id和“zhi”的两列;
27. nvl 和decode 函数