1、建表导入json数据
建表:create table rating_json(json string);
导入数据:
load data local inpath'/home/hadoop/data/rating.json' into table rating_json;
2、取出数据
直接查询
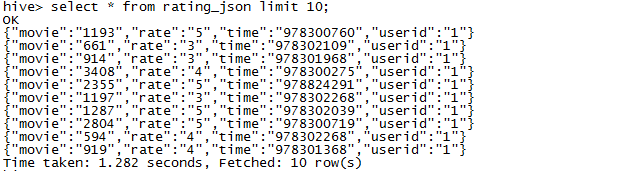
明显不符合我们要求
我们需要用到“json_tuple”函数来解析
首先看官网定义
--------------------------------------------------------------------------------------------------------------------------------------
json_tuple
A new json_tuple() UDTF is introduced in Hive 0.7. It takes a set of names (keys) and a JSON string, and returns a tuple of values using one function. This is much more efficient than calling GET_JSON_OBJECT to retrieve more than one key from a single JSON string. In any case where a single JSON string would be parsed more than once, your query will be more efficient if you parse it once, which is what JSON_TUPLE is for. As JSON_TUPLE is a UDTF, you will need to use the LATERAL VIEW syntax in order to achieve the same goal.
For example,
select a.timestamp, get_json_object(a.appevents, '$.eventid'), get_json_object(a.appenvets, '$.eventname') from log a;
should be changed to:
select a.timestamp, b.*
from log a lateral view json_tuple(a.appevent, 'eventid', 'eventname') b as f1, f2;
--------------------------------------------------------------------------------------------------------------------------------------
简单来说就是一转多
select json_tuple(json,"movie","rate","time","userid") as (movie,rate,time,userid) from rating_json limit 10;
这才是我们熟悉的格式

查出来的数据第三列是时间戳,我们把时间戳转化一下转化为年月日,查询出的meta变为,
userid,movie,rate,time, year,month,day,hour,minute, ts
语句:
select t.movie,t.rate,t.time,t.userid,from_unixtime(cast(t.time as bigint),'yyyy'),from_unixtime(cast(t.time as bigint),'MM'),from_unixtime(cast(t.time as bigint),'dd'),from_unixtime(cast(t.time as bigint),'HH'),from_unixtime(cast(t.time as bigint),'mm'),from_unixtime(cast(t.time as bigint),'ss')
from (select json_tuple(json,"movie","rate","time","userid") as (movie,rate,time,userid) from rating_json limit 10) t
查询结果:
Total MapReduce CPU Time Spent: 4 seconds 520 msec
OK
919 4 978301368 1 2001 01 01 06 22 48
594 4 978302268 1 2001 01 01 06 37 48
2804 5 978300719 1 2001 01 01 06 11 59
1287 5 978302039 1 2001 01 01 06 33 59
1197 3 978302268 1 2001 01 01 06 37 48
2355 5 978824291 1 2001 01 07 07 38 11
3408 4 978300275 1 2001 01 01 06 04 35
914 3 978301968 1 2001 01 01 06 32 48
661 3 978302109 1 2001 01 01 06 35 09
1193 5 978300760 1 2001 01 01 06 12 40
Time taken: 42.961 seconds, Fetched: 10 row(s)
查询性别相同的人,年龄最大的两个
数据:
1 18 ruoze M
2 19 jepson M
3 22 wangwu F
4 16 zhaoliu F
5 30 tianqi M
6 26 wangba F
使用分区函数:
row_number
select age,name,sex
from (select age,name,sex,row_number() over(PARTITION BY sex order by age desc)as rank from hive_rownumber) t
where rank < 3
自定义函数:
User-Defined Functions : UDF
UDF: 一进一出 upper lower substring
UDAF:Aggregation 多进一出 count max min sum ...
UDTF: Table-Generation 一进多出
自定义函数demo:
创建一个maven项目:
pom文件:

java文件:

导出jar包,传到服务器上;
添加jar包:
add jar /home/hadoop/lib/hive.jar;
创建临时函数:
CREATE TEMPORARY FUNCTION sayHello AS 'com.ruoze.data.hive.HelloUDF';
测试函数是否已经加到hive中:
select sayhello('eeeeee','kkkkkkkkk') from hive_wc;
这样创建的是临时函数,重新打开一个窗口就找不到了;
我们在创建一个永久函数:
首先将jar包传到hdfs中:
hadoop fs -mkdir /lib
hadoop fs -put hive.jar /lib/
CREATE FUNCTION sayHello22 AS 'com.ruoze.data.hive.HelloUDF' USING JAR 'hdfs://xx.xx.xx.7:9000/lib/hive.jar';
完成!!!!