Python金融大数据分析-PCA分析
1.pandas的一个技巧
apply() 和applymap()是DataFrame数据类型的函数,map()是Series数据类型的函数。apply()的操作对象DataFrame的一列或者一行数据, applymap()是element-wise的,作用于每个DataFrame的每个数据。 map()也是element-wise的,对Series中的每个数据调用一次函数。
2.PCA分解德国DAX30指数
DAX30指数有三十个股票,听起来不多的样子,其实还是挺多的,我们很有必要对其进行主成分分析,然后找出最重要的几个股票。想必PCA的原理大家应该都是知道,说白了就是在一个回归中找到影响最大的那几个,当然,数学原理就涉及矩阵分解,什么SVD呀。
先上点代码
import pandas as pd
import pandas.io.data as web
import numpy as np
np.random.seed(1000)
import scipy.stats as scs
import statsmodels.api as sm
import matplotlib as mpl
import matplotlib.pyplot as plt
from sklearn.decomposition import KernelPCA#导入机器学习的PCA包
symbols = ['ADS.DE','ALV.DE','BAS.DE','BAYN.DE','BEI.DE','BMW.DE','CBK.DE','CON.DE','DAI.DE',
'DB1.DE','DBK.DE','DPW.DE','DTE.DE','EOAN.DE','FME.DE','FRE.DE','HEI.DE','HEN3.DE',
'IFX.DE','LHA.DE','LIN.DE','LXS.DE','MRK.DE','MUV2.DE','RWE.DE','SAP.DE','SDF.DE',
'SIE.DE','TKA.DE','VOW3.DE','^GDAXI']#DAX30指数各个股票的代码以及德国30指数代码,共31个数据列
data = pd.DataFrame()
for sym in symbols:#获取数据
data[sym] = web.DataReader(sym,data_source = 'yahoo')['Close']
data = data.dropna()#丢弃缺失数据
dax = pd.DataFrame(data.pop('^GDAXI'))#将指数数据单独拿出来,采用pop在获取的时候已经从原来的地方删除了这一列数据了
scale_function = lambda x:(x-x.mean())/x.std()
pca = KernelPCA().fit(data.apply(scale_function))#这里用到了apply函数。做PCA前,我们要对数据做标准化
get_we = lambda x:x/x.sum()
print get_we(pca.lambdas_)[:10]
pca = KernelPCA(n_components = 1).fit(data.apply(scale_function))
dax['PCA_1'] =pca.transform(data)
dax.apply(scale_function).plot(figsize = (8,4))
pca = KernelPCA(n_components = 5).fit(data.apply(scale_function))
weights = get_we(pca.lambdas_)
dax['PCA_5'] =np.dot(pca.transform(data),weights)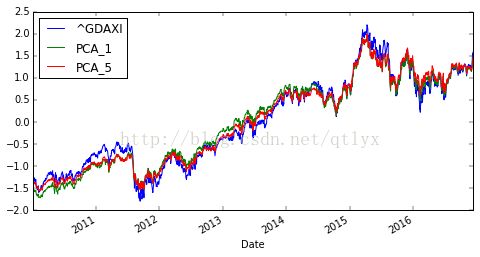
这里,我们采用只用第一个成分去拟合以及前五个成分去拟合,发现效果好的出奇。这样我们就做到了降维的工作了。我们再来展开看一下PCA的效果。
plt.figure(figsize = (8,4))
plt.scatter(dax['PCA_5'],dax['^GDAXI'],color = 'r')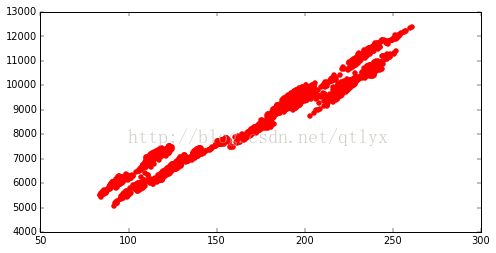
我们看到,整体效果还是不错的,但是很显然,两边和中间总是有点问题,所以,如果我们要提高,我们可以在中间分段进行PCA,这样的话,效果应该会更加好。