zero-copy 原理
1. 传统模型
要想了解zero-copy 我们需要知道该技术的应用场景,网络传输中一个基本的场景是:通过网络传输一个文件。代码如下
read(file,tmp_buf,len);
write(socket,tmp_buf,len);
在这个场景中,至少出现4次数据拷贝和3次的内核态和用户态的切换。看下图,上面的部分显示的是上下文切换的过程,下部分展示的是数据拷贝的过程。
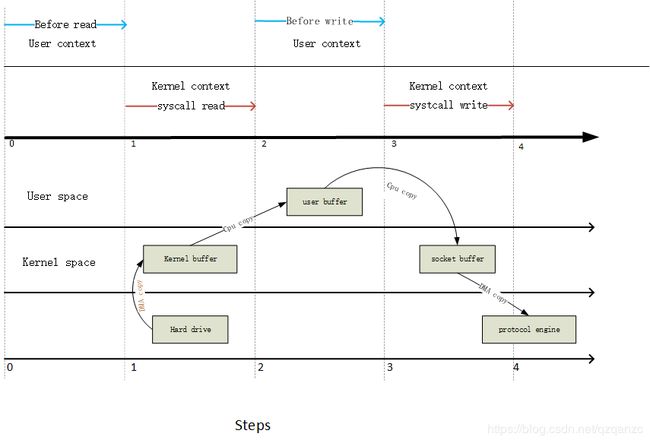
第一步: 读取文件的时候会引起一次用户态到内核态的切换。第一次copy 是通过DMA(Data Memory Access)引擎直接从硬盘文件系统读取文件内容存储在内核缓存空间。
第二步:数据从内核缓存区拷贝到用户缓存区后返回系统读取调用,这个过程会引起内核态到用户态的切换。现在数据存储在用户缓存区中。
第三步:往socket 写数据的时候,引起一次用户态到内核态的切换。第三次copy 是从用户buffer 数据Copy到socket Buffer 中。
第四步:系统syswrite 完成,导致第四次上下文切换,第四次拷贝是DMA引擎将数据从与socketbuffer(与socket关联的内核buffer) 拷贝到协议栈中。
2. mmap(优化一:用户态和内核态共享内存空间)
从上图可以看出有很多重复的不必要的数据copy,可以通过减少不必要的数据Copy 来提高性能。
可以通过调用mmap来减少一次copy 过程。
tmp_buf = mmap(file,len);
write(socket,tmp_buf,len);

第一步:DMA 引擎读取硬盘中文件到内核缓存,此缓存被用户进程和内核进程共享。
第二步:syswrite() 将内核中的数据copy 到socketbuffer(与socket 相关的内核缓存)
第三步:DMA 从socketbuffer 拷贝到 protocol栈
通过mmap 读取数据可以将Kernel Buffer->UserBuffer–> socketBuffer 过程变为sharedBuffer->socketBuffer,减少一次数据copy
sendFile V2.1
sendfile(socket,file,len)
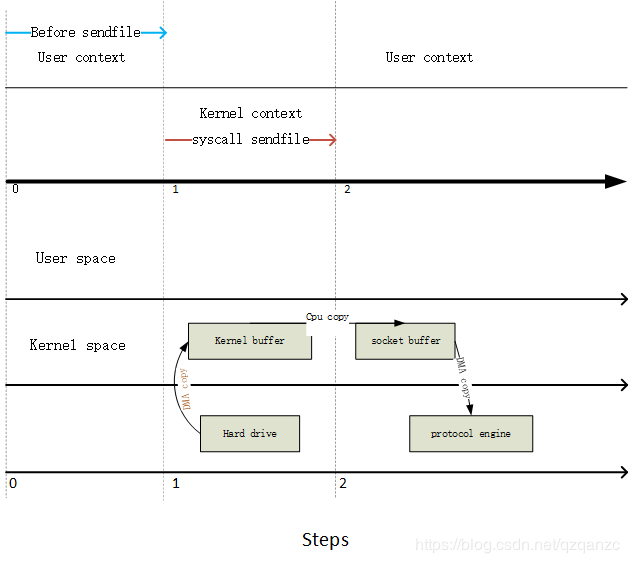
在Linux内核2.1引入了sendfile用于通过网络交换俩个本地文件。不仅能够减少文件拷贝还能减少线程上下文切换。
第一步:通过DMA 引擎将数据从文件拷贝kernel buffer。然后将内核数据拷贝到socketbuffer;
第二步:第三次copy 发生在DMA 将 socketbuffer数据拷贝到协议栈
sendFile >V2.1

step one: the sendfile system call causes the file contents to be copied into a kernel buffer by the DMA engine.
step two: no data is copied into the socket buffer. Instead, only descriptors with information about the whereabouts and length of the data are appended to the socket buffer. The DMA engine passes data directly from the kernel buffer to the protocol engine, thus eliminating the remaining final copy.
Because data still is actually copied from the disk to the memory and from the memory to the wire, some might argue this is not a true zero copy. This is zero copy from the operating system standpoint, though, because the data is not duplicated between kernel buffers. When using zero copy, other performance benefits can be had besides copy avoidance, such as fewer context switches, less CPU data cache pollution and no CPU checksum calculations.