MySQL数据库集群实战———MySQL高可用MHA
文章目录
- 一、MySQL高可用之MHA
- 1.1 数据库的工作原理
- 1.2 高可用
- 1.3 MHA
- 二、配置MHA
- 2.1 配置MHA
- 2.2 手动切换maste
- 2.3 手动切换VIP漂移
一、MySQL高可用之MHA
1.1 数据库的工作原理
数据库的内部具有缓冲区,在缓冲区中的数据是待处理的数据,数据库源源不断的从缓冲区中获取数据进行处理,但是如果高并发,会造成数据缓冲区数据溢出,最终导致数据库宕机,不能响应。这只能缓解,不能根治。
1.2 高可用
我认为,高可用就是尽可能缩短因日常维护和突然的系统崩溃所导致的停机时间。
- 数据库实现高可用需要解决如下的问题:
数据库的信息如何实现同步
用户如何选择连接哪个数据库
数据库宕机后如何实现高可用(尽可能不死,死后有替补)
如果数据库宕机,宕机后的数据库如何实现数据同步。
1.3 MHA
MHA(Master High Availability) 目前在MySQL高可用方面是一个相对成熟的解决方案,它由日本DeNA公司youshimaton(现就职于 Facebook公司)开发,是一套优秀的作为MySQL高可用性环境下故障切换和主从提升的高可用软件。在MySQL故障切换过程中,MHA能做到在 0~30秒之内自动完成数据库的故障切换操作,并且在进行故障切换的过程中,MHA能在最大程度上保证数据的一致性,以达到真正意义上的高可用。
该软件由两部分组成:MHA Manager(管理节点)和MHA Node(数据节点)。MHA Manager可以单独部署在一台独立的机器上管理多个master-slave集群,也可以部署在一台slave节点上。MHA Node运行在每台MySQL服务器上,MHA Manager会定时探测集群中的master节点,当master出现故障时,它可以自动将最新数据的slave提升为新的master,然后将所有其他的slave重新指向新的master。整个故障转移过程对应用程序完全透明。在MHA自动故障切换过程中,MHA试图从宕机的主服务器上保存二进制日志,最大程度的保证数据的不丢失,但这并不总是可行的。例如,如果主服务器 硬件故障或无法通过ssh访问,MHA没法保存二进制日志,只进行故障转移而丢失了最新的数据。使用MySQL 5.5的半同步复制,可以大大降低数据丢失的风险。MHA可以与半同步复制结合起来。如果只有一个slave已经收到了最新的二进制日志,MHA可以将最 新的二进制日志应用于其他所有的slave服务器上,因此可以保证所有节点的数据一致性。目前MHA主要支持一主多从的架构,要搭建MHA,要求一个复制集群中必须最少有三台数据库服务器,一主二从,即一台充当master,一台充当备用master,另外一台充当从库,因为至少需要三台服务器,出于机器成本的考虑,淘宝也在该基础上进行了改造,目前淘宝TMHA已经支持一主一从。
- MHA的要求和原理:
(1)需要奇数个节点。当一个master节点挂掉之后投票选出一个新的master,偶数个节点会出现票数相同的状况,但奇数个就不会。
(2)所有数据节点的数据一致时,每一台数据节点都有可能作为master
(3)每个节点都要安装master和slave插件;
(4)当master节点挂了之后,一般选出数据最近的slave节点作为新的master节点,数据最近指的是数据的差异性小
二、配置MHA
实验环境
| 主机名 | IP | 功用 |
|---|---|---|
| server1 | 172.25.2.51 | master |
| server2 | 172.25.2.52 | slave(备master) |
| server3 | 172.25.2.53 | slave |
| server4 | 172.25.2.54 | MHA |
2.1 配置MHA
1、配置 server1 mysql服务
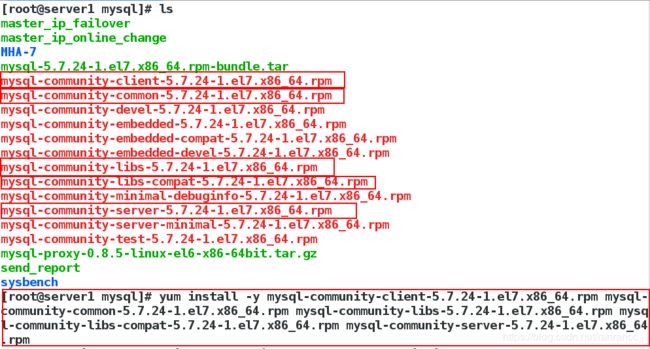
1) 安装mysql服务
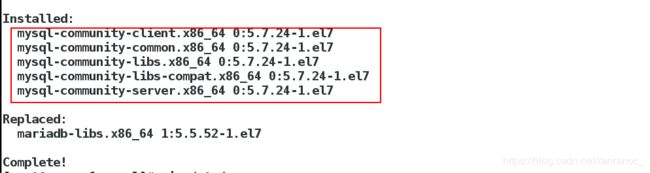
yum install -y mysql-community-client-5.7.24-1.el7.x86_64.rpm mysql-community-common-5.7.24-1.el7.x86_64.rpm mysql-community-libs-5.7.24-1.el7.x86_64.rpm mysql-community-libs-compat-5.7.24-1.el7.x86_64.rpm mysql-community-server-5.7.24-1.el7.x86_64.rpm

2)更改配置文件/etc/my.cnf,添加以下内容后,启动数据库:
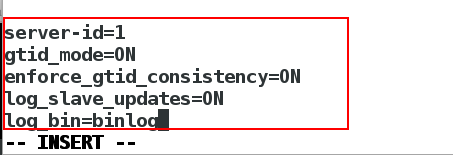
29 server-id=1
30 gtid_mode=ON
31 enforce_gtid_consistency=ON
32 log_bin=binlog
33 log_slave_updates=ON

3)查看临时密码,安全初始化
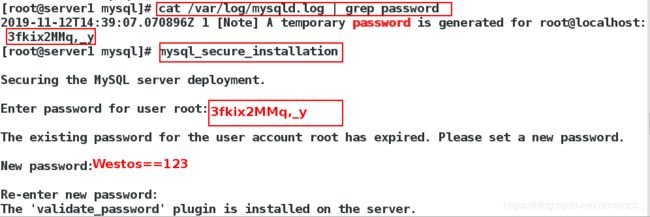
4)登录数据库,创建并授权用来做复制的用户,查看master状态
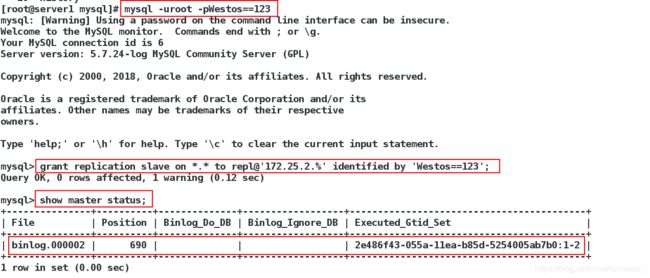
2、在server2和server3上,执行以下操作:
1 | yum install -y mysql-community-client-5.7.24-1.el7.x86_64.rpm \
mysql-community-common-5.7.24-1.el7.x86_64.rpm \
mysql-community-libs-5.7.24-1.el7.x86_64.rpm \
mysql-community-libs-compat-5.7.24-1.el7.x86_64.rpm \
mysql-community-server-5.7.24-1.el7.x86_64.rpm
2 | vim /etc/my.cnf
server-id=2(3)
gtid_mode=ON
enforce_gtid_consistency=ON
log_bin=binlog
log_slave_updates=ON
3 | systemctl start mysqld
4 | cat /var/log/mysqld.log | grep password
5 | mysql_secure_installation
6 | mysql -uroot -pWestos==123
3、在server2上,登录数据库,修改master信息,查看slave状态。
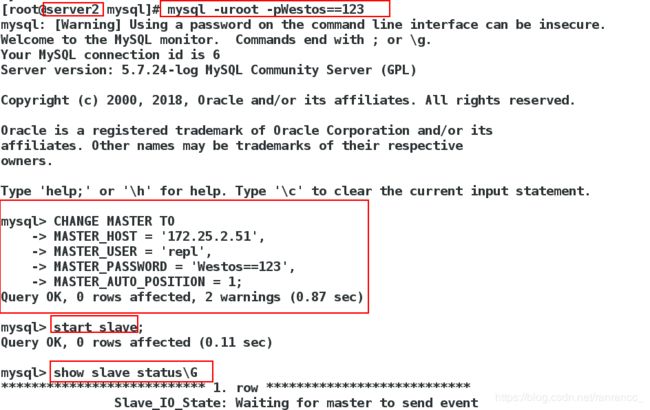
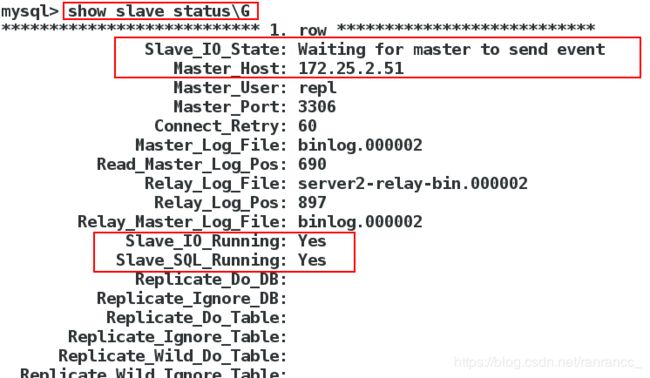
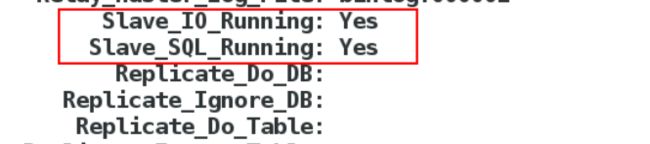
4、在server3上,登录数据库,修改master信息,查看slave状态。

5、此时,再开一台虚拟机server4,安装所需软件
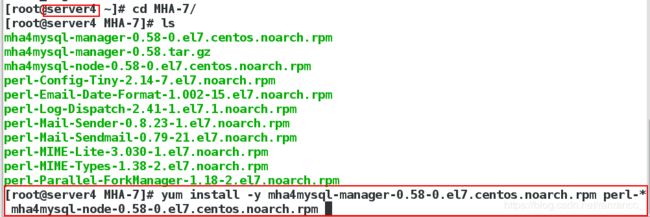
6、生成ssh密钥,管理节点是不需要输入密码,将生成的公钥和私钥传给数据节点

[root@server4 ~]# ssh-keygen
[root@server4 ~]# ssh-copy-id server1
[root@server4 ~]# ssh-copy-id server2
[root@server4 ~]# ssh-copy-id server3

[root@server4 ~]# scp -r .ssh server1:
[root@server4 ~]# scp -r .ssh server2:
[root@server4 ~]# scp -r .ssh server3:

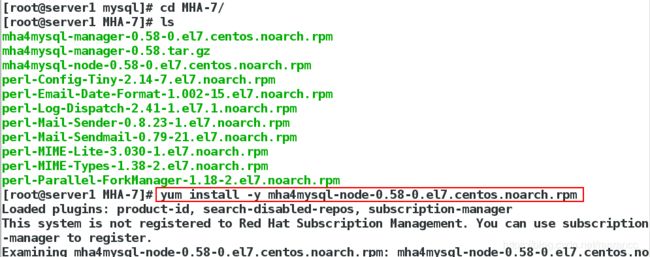
6、在server1、server2和server3上,安装节点数据包
yum install -y mha4mysql-node-0.58-0.el7.centos.noarch.rpm
7、管理节点server4上创建一个目录,编辑配置文件
[root@server4 ~]# mkdir -p /etc/masterha
[root@server4 ~]# cd /etc/masterha/
[root@server4 masterha]# ls
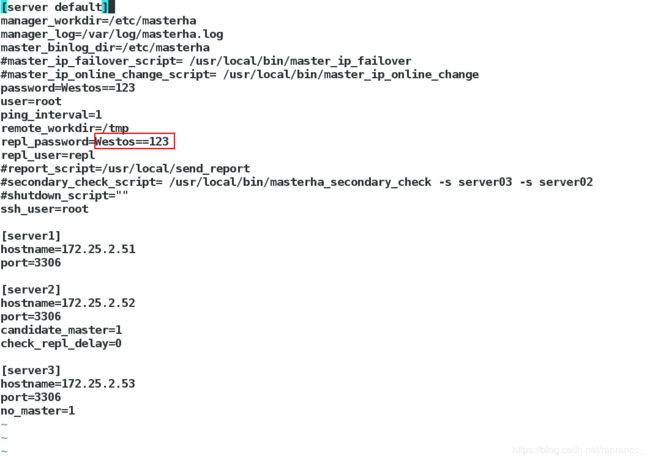
[root@server4 masterha]# vim app1.cnf
写入:
[server default]
manager_workdir=/etc/masterha
manager_log=/var/log/masterha.log # manager 日志文件
master_binlog_dir=/etc/masterha
password=Westos==123 #MySQL管理帐号和密码
user=root
ping_interval=1
remote_workdir=/tmp
repl_password=Westos==123
repl_user=repl # 复制帐号和密码
ssh_user=root # 系统ssh用户
[server1]
hostname=172.25.2.51
port=3306
[server2]
hostname=172.25.2.52
port=3306
candidate_master=1
check_repl_delay=0
[server3]
hostname=172.25.2.53
port=3306
no_master=1 ##no_master表示这个节点不能作为master

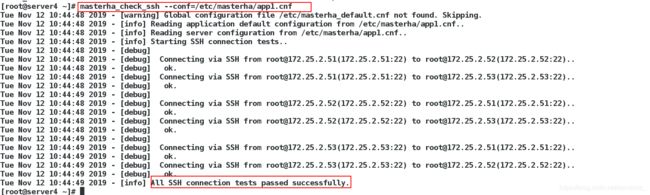
8、管理节点ssh检查管理节点ssh检查
[root@server4 ~]# masterha_check_ssh --conf=/etc/masterha/app1.cnf
- 如果报错的话,是因为server1、server2、server3之间相互不免密。
拷贝server4上的密钥给server1 2 3
[root@server4 ~]# scp -r .ssh server1:
[root@server4 ~]# scp -r .ssh server2:
[root@server4 ~]# scp -r .ssh server3:
再检测ssh,成功
9、检测复制功能
[root@server4 ~]# masterha_check_repl --conf=/etc/masterha/app1.cnf

此时发现报错,这是因为没有给节点授权:
server1: 所有权限;

server2 和 server3: 只读

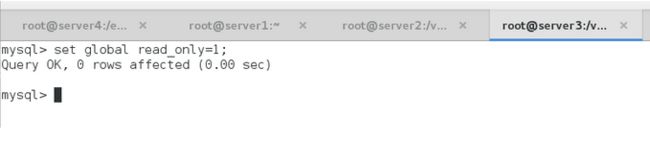
此时,再次检查复制功能:masterha_check_repl --conf=/etc/masterha/app1.cnf

2.2 手动切换maste
10、手动替换master
先关闭当前节点的manager,不关的话切不了,manager就是自动切换的工具
[root@server4 masterha]# masterha_stop --conf=/etc/masterha/app1.cnf
![]()
手动替换master节点
- 手动切换之前,需要保证主从同步正常,repl复制用户能够远程连接
masterha_master_switch --master_state=dead --conf=/etc/masterha/app1.cnf
--dead_master_host=172.25.2.51 --dead_master_ip=172.25.2.51 --dead_master_port=3306
--new_master_host=172.25.2.52 --new_master_port=3306
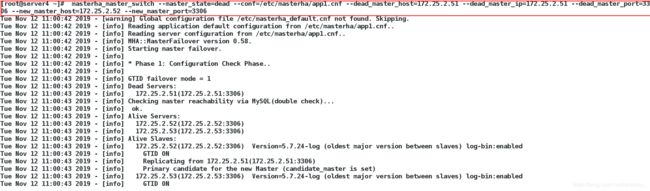
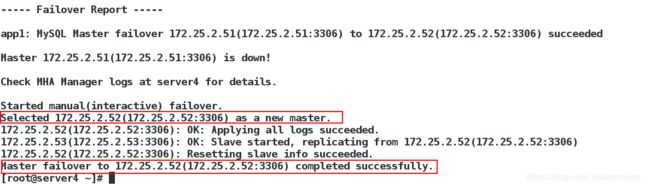
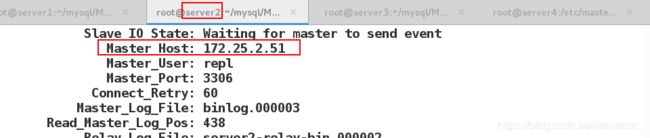
切换成功后,可以在server3上看到它的master已经变成了server2,而server2已经是master了
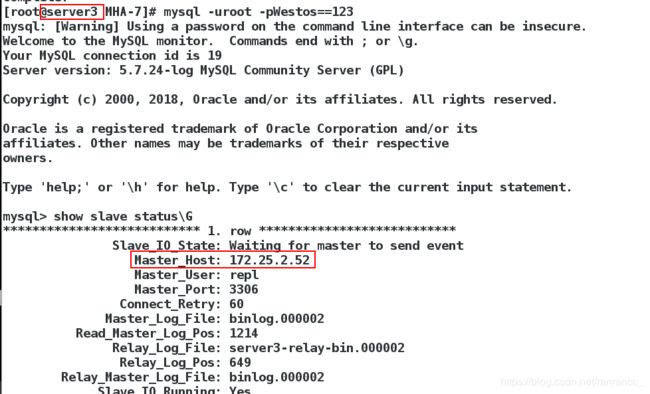
11、开启server1的mysqld服务,作为slave加入集群,将他的master改为server2
![]()


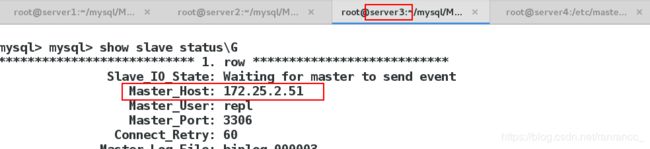
现在就完成了一次手动切换,这时会在/etc/masterha目录下生成一个app1.failover.complete文件,是来记录failover情况的,再进行failover时必须先把这个文件删除,不然不会failover
切换回172.25.2.51为master

![]()
测试:
2.3 手动切换VIP漂移
(1)首先清理app1.failover.complete

(2)server4创建一个检测进程
[root@server4 masterha]# nohup masterha_manager --conf=/etc/masterha/app1.cnf &>/dev/null &
(3)在server1上查看,将此进程关闭,发现他又开启了。
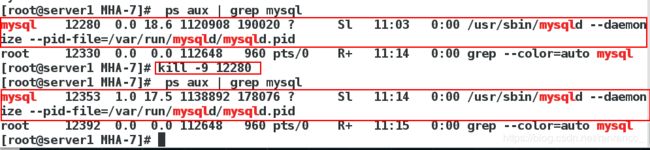
(4)在server1上(当前master),关闭myslq服务
[root@server1 ~]# systemctl stop mysqld
此时,发现已经切换,同时manager进程退出,所以全自动需要脚本
(5)先把server1加回集群
mysql> CHANGE MASTER TO MASTER_HOST = '172.25.0.2', MASTER_USER = 'repl',
MASTER_PASSWORD = 'Westos==123', MASTER_AUTO_POSITION = 1;
mysql> start slave;

(6)配置脚本和vip漂移,编辑master_ip_failover 和 master_ip_online_change 两个脚本
- 因为用户访问入口只能有一个,所以需要配置vip
修改内容:
my $ssh_start_vip = "/sbin/ip addr add $vip dev eth0";
my $ssh_stop_vip = "/sbin/ip addr del $vip dev eth0";

cp master_ip_failover master_ip_online_change /usr/local/bin
cd /usr/local/
cd bin/
chmod +x master_ip_failover master_ip_online_change

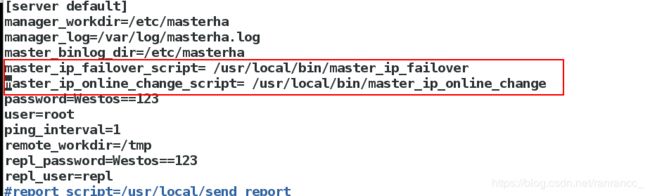
(7)在server4的配置文件中添加以下两行
master_ip_failover_script= /usr/local/bin/master_ip_failover
master_ip_online_change_script= /usr/local/bin/master_ip_online_change
(8)给server2(当前master)上添加一个vip
- 目前server2是master,所以先给server2添加vip
![]()
(9) 测试:vip漂移
[root@server4 bin]# masterha_master_switch --conf=/etc/masterha/app1.cnf
--master_state=alive --new_master_host=172.25.2.51 --new_master_port=3306
--orig_master_is_new_slave --running_updates_limit=10000
我们可以看到vip的切换
***************************************************************
Disabling the VIP - 172.25.2.100/24 on old master: 172.25.2.52
***************************************************************
***************************************************************
Enabling the VIP - 172.25.2.100/24 on new master: 172.25.2.51
***************************************************************
(10)测试 :全自动切换
在server4上先删除app1.failover.complete,开启manager
nohup masterha_manager --conf=/etc/masterha/app1.cnf &>/dev/null &
然后在master(server1)上关闭mysql,模拟故障,再在server4上查看日志
cat /var/log/masterha.log,可以看到切换成功,vip也成功漂移