分布式存储与分布式计算
一、高性能计算
目前自己知道的高性能计算工具,如下所示:
- Hadoop:Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
- Spark:Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用的并行,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的map reduce的算法。
- CUDA:CUDA(Compute Unified Device Architecture),是显卡厂商NVIDIA推出的运算平台。 CUDA是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。 它包含了CUDA指令集架构(ISA)以及GPU内部的并行计算引擎。 开发人员现在可以使用C语言来为CUDA架构编写程序,C语言是应用最广泛的一种高级编程语言。所编写出的程序于是就可以在支持CUDA的处理器上以超高性能运行。CUDA3.0已经开始支持C++和FORTRAN。
- OpenCL:OpenCL(全称Open Computing Language,开放运算语言)是第一个面向异构系统通用目的并行编程的开放式、免费标准,也是一个统一的编程环境,便于软件开发人员为高性能计算服务器、桌面计算系统、手持设备编写高效轻便的代码,而且广泛适用于多核心处理器(CPU)、图形处理器(GPU)、Cell类型架构以及数字信号处理器(DSP)等其他并行处理器,在游戏、娱乐、科研、医疗等各种领域都有广阔的发展前景。
- MPICH:通过安装MPICH构建MPI编程环境,从而进行并行程序的开发。MPICH是MPI(Message-Passing Interface)的一个应用实现,支持最新的MPI-2接口标准,是用于并行运算的工具。
- MPI:MPI是一个跨语言的通讯协议,用于编写并行计算机。支持点对点和广播。MPI是一个信息传递应用程序接口,包括协议和和语义说明,他们指明其如何在各种实现中发挥其特性。MPI的目标是高性能,大规模性,和可移植性。MPI在今天仍为高性能计算的主要模型。主要的MPI-1模型不包括共享内存概念,MPI-2只有有限的分布共享内存概念。 但是MPI程序经常在共享内存的机器上运行。在MPI模型周边设计程序比在NUMA架构下设计要好因为MPI鼓励内存本地化。尽管MPI属于OSI参考模型的第五层或者更高,他的实现可能通过传输层的sockets和Transmission Control Protocol (TCP)覆盖大部分的层。大部分的MPI实现由一些指定惯例集(API)组成,可由C,C++,Fortran或者有此类库的语言比如C#,Java或者Python直接调用。MPI优于老式信息传递库是因为他的可移植性和速度。
- OpenMPI:OpenMPI是一种高性能消息传递库,最初是作为融合的技术和资源从其他几个项目(FT-MPI,LA-MPI,LAM/MPI以及PACX-MPI),它是MPI-2标准的一个开源实现,由一些科研机构和企业一起开发和维护。因此,OpenMPI能够从高性能社区中获得专业技术、工业技术和资源支持,来创建最好的MPI库。OpenMPI提供给系统和软件供应商、程序开发者和研究人员很多便利。易于使用,并运行本身在各种各样的操作系统,网络互连,以及一批/调度系统。
- OpenMP:OpenMp是由OpenMP Architecture Review Board牵头提出的,并已被广泛接受的,用于共享内存并行系统的多线程程序设计的一套指导性的编译处理方案(Compiler Directive)。OpenMP支持的编程语言包括C语言、C++和Fortran;而支持OpenMp的编译器包括Sun Compiler,GNU Compiler和Intel Compiler等。OpenMp提供了对并行算法的高层的抽象描述,程序员通过在源代码中加入专用的pragma来指明自己的意图,由此编译器可以自动将程序进行并行化,并在必要之处加入同步互斥以及通信。当选择忽略这些pragma,或者编译器不支持OpenMp时,程序又可退化为通常的程序(一般为串行),代码仍然可以正常运作,只是不能利用多线程来加速程序执行。
- GraphLab:GraphLab 是另一种有趣的MapReduce抽象实现,侧重机器学习算法的并行实现。GraphLab中,Map阶段定义了可以独立执行(在独立的主机上)的计算,Reduce阶段合并这些计算结果。
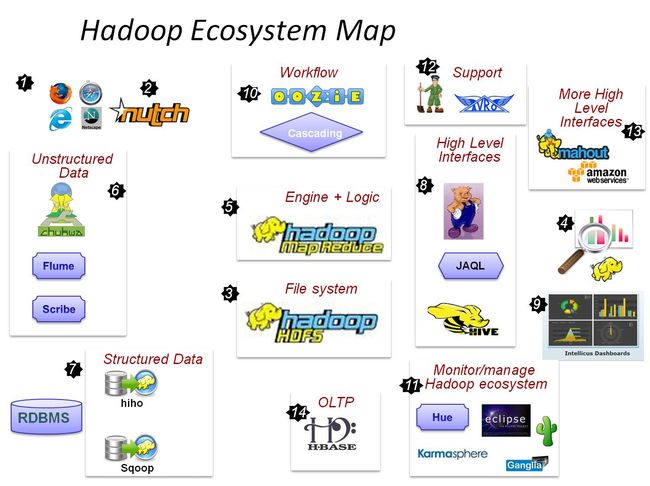
1、Hadoop生态系统的功能以及对应的开源工具,如下所示:
(1)海量数据怎么存,当然是用分布式文件系统——HDFS。
(2)数据怎么用呢,分析、处理MapReduce框架,让你通过编写代码来实现对大数据的分析工作。
(3)非结构化数据(日志)收集处理——Fuse、WebDAV、Chukwa、Flume和Scribe。
(4)数据导入HDFS中,RDBMS也可以加入HDFS的狂欢了——HIHO、Sqoop。
(5)MaoReduce太麻烦,用熟悉的方式操作Hadoop里的数据——Pig、Hive、Jaql。
(6)让你的数据可见——Drilldown、Intellicus。
(7)用高级语言管理你的任务流——Oozie、Cascading。
(8)Hadoop自己的监控管理工具——Hue、Karmasphere、Eclipse Plugin、Cacti、Ganglia。
(9)数据序列化处理与任务调度——Avro、ZooKeeper。
(10)更多构建在Hadoop上层的服务——Mahout、Elastic Map Reduce。
(11)OLTP存储系统——HBase。
(12)基于Hadoop的实时分析——Impala。
2、Hadoop常用项目介绍
(1)Apache Hadoop
Hadoop是一个大数据处理框架,它可用于从单台到数以千计的服务器集群的存储和计算服务。HadoopDistributed File System (HDFS) 提供了能够跨越多台计算机的大数据存储服务,而MapReduce则提供了一个并行处理的框架。它们的思想源自Google的MapReduce和Google File System(GFS)论文。详细参见:http://hadoop.apache.org/
(2)Apache Ambari
Ambari是一个对Hadoop集群进行监控和管理的基于Web的系统。目前已经支持HDFS,MapReduce,Hive,HCatalog,HBase,ZooKeeper,Oozie,Pig和Sqoop等组件。详细参见:http://ambari.apache.org/
(3)Apache Cassandra
Cassandra是一个分布式的NoSQL数据库。它基于multi-master模式,无单点失败,具有可扩展性。最早由Facebook开发用于存储收件箱等简单格式数据,后开源,被用于Twitter等知名网站。详细参见:http://cassandra.apache.org/
(4)Apache Hive
Hive是 一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类似SQL一样的查询语言HiveQL来管理这些数据。详细参见:http://hive.apache.org/
(5)Apache Pig
Pig是一个基于Hadoop的大数据分析平台,它提供了一个叫PigLatin的高级语言来表达大数据分析程序。详细参见:http://pig.apache.org/
(6)Apache Avro
Avro是一个数据序列化系统。它提供了丰富的数据结构类型,快读可压缩的二进制数据格式,存储持久数据的文件容器,远程过程调用等。详细参见:http://avro.apache.org/
(7)Apache Chukwa
Chukwa是一个用于监控大型分布式系统的的数据采集系统。它构建于Hadoop的HDFS和Map/Reduce框架之上,包含了一系列用于数据监控,分析和展示的灵活的强大工具集。它为日志系统提供了一整套解决方案。详细参见:http://chukwa.apache.org/
(8)Apache Drill
Drill是一个对大规模数据集进行交互式分析的分布式系统。它是Google的Gremel的开源实现。详细参见:http://incubator.apache.org/drill/
(9)Apache Flume
Flume是一个高可靠的分布式海量日志采集,聚合和传输系统。它来源于Cloudera开发的日志收集系统。详细参见:http://flume.apache.org/
(10)Apache HBase
HBase是一个分布式的,面向列的数据库。它基于Hadoop之上提供了类似BigTable的功能。详细参见:http://hbase.apache.org/
(11)Apache HCatalog
HCatalog是基于Hadoop的数据表和存储管理服务,提供了更好的数据存储抽象和元数据服务。详细参见:https://hive.apache.org/hcatalog/
(12)Apache Mahout
Mahout是一个机器学习领域的经典算法库,提供包括聚类,分类,推荐过滤,频繁子项挖掘等。详细参见:http://mahout.apache.org/
(13)Apache Oozie
Oozie是一个工作流调度系统,用于管理Hadoop里的job。它可以把多个Map/Reduce作业组合到一个逻辑工作单元来完成指定目标。详细参见:http://oozie.apache.org/
(14)Apache Sqoop
Sqoop是一个Hadoop和关系型数据库之间的数据转移工具。可将关系型数据库中的数据导入到Hadoop的HDFS中,也可将HDFS中的数据导进到关系型数据库中。详细参见:http://sqoop.apache.org/
(15)Apache ZooKeeper
ZooKeeper是一个针对大型分布式系统的可靠协调系统,提供包括配置维护,名字服务,分布式同步和组服务等功能。Hadoop的管理就是用的ZooKeeper。详细参见:http://zookeeper.apache.org
(16)Apache Giraph
Giraph是一个高可伸缩的迭代式图处理系统。它现在用于分析Facebook中的用户的社交关系。Giraph相当于Google图处理架构Pregel的开源版本。详细参见:http://giraph.apache.org/
(17)Apache Accumulo
Accumulo是一个可靠的,可伸缩的,高性能排序分布式的Key-Value存储解决方案。它基于Google的BigTable设计思路。详细参见:http://accumulo.apache.org/
(18)Apache S4
S4是一个可扩展的,分布式的流数据实时处理框架,最早由Yahoo开发并开源。与Twitter的Storm类似。详细参见:http://incubator.apache.org/s4/
(19)Apache Thrift
Thrift是一个跨语言的服务开发框架。用它可让你的服务支持多种语言的开发,并可用代码生成器对它所定义的IDL定义文件自动生成服务代码框架。它最早由Facebook开发并开源出来。 详细参见:http://thrift.apache.org/
(20)Impala
Impala采用与Hive相同的元数据、SQL语法、ODBC驱动程序和用户接口(Hue Beeswax),这样在使用CDH产品时,批处理和实时查询的平台是统一的。目前支持的文件格式是文本文件和Sequence Files(可以压缩为Snappy、GZIP和BZIP,前者性能最好)。其他格式如Avro、RCFile、LZO文本和Doug Cutting的Trevni将在正式版中支持,官方测试速度是Hive的3~90倍。详细参见:http://www.cloudera.com/content/cloudera/en/products-and-services/cdh/impala.html
(21)Nutch
最后,得提一下Apache Nutch开源网络爬虫系统。Hadoop最早是为Nutch服务而诞生的,即为大规模的网络爬虫系统提供分布式存储和计算服务。详细参见:https://nutch.apache.org/
说明:
开源的搜索引擎工具:Lucene,Nutch,Solr。
3、Hadoop应用场景
美国著名科技博客GigaOM的专栏作家Derrick Harris跟踪云计算和Hadoop技术已有多年时间,他也在最近的一篇文章中总结了10个Hadoop的应用场景,如下所示:
(1)在线旅游
你知道吗,目前全球范围内80%的在线旅游网站都是在使用Cloudera公司提供的Hadoop发行版,其中SearchBI网站曾经报道过的Expedia也在其中。
(2)移动数据
Cloudera运营总监称,美国有70%的智能手机数据服务背后都是由Hadoop来支撑的,也就是说,包括数据的存储以及无线运营商的数据处理等,都是在利用Hadoop技术。
(3)电子商务
这一场景应该是非常确定的,eBay就是最大的实践者之一。国内的电商在Hadoop技术上也是储备颇为雄厚的。
(4)能源开采
美国Chevron公司是全美第二大石油公司,他们的IT部门主管介绍了Chevron使用Hadoop的经验,他们利用Hadoop进行数据的收集和处理,其中这些数据是海洋的地震数据,以便于他们找到油矿的位置。
(5)节能
另外一家能源服务商Opower也在使用Hadoop,为消费者提供节约电费的服务,其中对用户电费单进行了预测分析。
(6)基础架构管理
这是一个非常基础的应用场景,用户可以用Hadoop从服务器、交换机以及其他的设备中收集并分析数据。
(7)图像处理
创业公司Skybox Imaging 使用Hadoop来存储并处理图片数据,从卫星中拍摄的高清图像中探测地理变化。
(8)诈骗检测
这个场景用户接触的比较少,一般金融服务或者政府机构会用到。利用Hadoop来存储所有的客户交易数据,包括一些非结构化的数据,能够帮助机构发现客户的异常活动,预防欺诈行为。
(9)IT安全
除企业IT基础机构的管理之外,Hadoop还可以用来处理机器生成数据以便甄别来自恶意软件或者网络中的攻击。
(10)医疗保健
医疗行业也会用到Hadoop,像IBM的Watson就会使用Hadoop集群作为其服务的基础,包括语义分析等高级分析技术等。医疗机构可以利用语义分析为患者提供医护人员,并协助医生更好地为患者进行诊断。
三、YARN
记得1.5年前的时候,首次接触Hadoop,那个时候Hadoop 2.X版本还没有出来,Spark也没有现在这么热。现在,Hadoop 2.X都出来快一年了,开源软件的发展速度之快,令人惊叹。以前Hadoop的学习都是比较零散的,不够系统,现在决定系统地、深入地学习Hadoop。掌握其精髓所在,即软件的工作原理和设计理念,而不忙于跟风,要深入地学习开发和运维,而不是盲目地追新,做安装卸载这样的重复性工作。总之,打牢HDFS和MapReduce基础,根据需要,逐步学习Hadoop的整个生态系统。
Hadoop 2.X最大的变化当然是YARN这个资源管理器了,或者说Hadoop操作系统了。YARN是Hadoop 2.0及以上版本的下一代集群资源管理和调度平台,支持多种计算框架,不仅支持MapReduce计算框架,还可以支持流式计算框架、图计算框架、实时/内存计算框架等,极大地扩展了Hadoop的使用场景,提高了Hadoop集群的利用效率。
说明:
集群资源管理和调度平台,除了YARN之外,还有Corona和Mesos等。
四、DRCP(Distributed Recommend Computing Platform)
1. Introduction
DRCP is a Distributed Machine Learning Platform based on Mahout,the functions are Distributed Storage and Distributed Computing, which is usedto scientific research and learning.
2. Topology 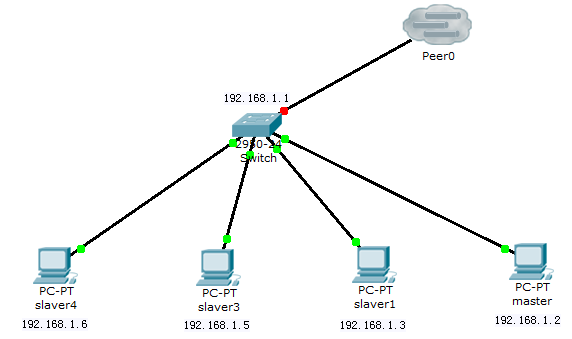
3. Software
(1)jdk-1.7.0
(2)hadoop-0.20.2
(3) mahout-0.5.0
(4)ubuntu-12.04
五、开发运维
最近在实验室搭建了一个4台Hadoop集群,在上面部署了分布式机器学习Mahout这个软件,我们的目的主要是为了做大数据推荐算法,提供一个生产平台。当然,4台Hadoop集群是远远不够的,以后会考虑升级的。通过这个真实的生产平台,提高MapReduce应用开发的能力,Hadoop和Mahout二次开发的能力,以及Hadoop运维的能力(调优)。打算在DRCP上开发我们的大数据推荐算法类库——Conquer,把一些经典的推荐算法,机器学习算法等,还有我们的研究成果MapReduce化之后融入到Conquer之中,到时候会开源的。
1、DRCP的升级
- 添加结点
- 删除结点
- 系统升级
- 软件安装
- 软件卸载
2、DRCP的运维
- 系统优化
[11] Hadoop应用场景: http://www.ciotimes.com/infrastructure/syjq/67136.html