博客搬家系列(六)-爬取今日头条文章
博客搬家系列(六)-爬取今日头条文章
一.前情回顾
博客搬家系列(一)-简介:https://blog.csdn.net/rico_zhou/article/details/83619152
博客搬家系列(二)-爬取CSDN博客:https://blog.csdn.net/rico_zhou/article/details/83619509
博客搬家系列(三)-爬取博客园博客:https://blog.csdn.net/rico_zhou/article/details/83619525
博客搬家系列(四)-爬取简书文章:https://blog.csdn.net/rico_zhou/article/details/83619538
博客搬家系列(五)-爬取开源中国博客:https://blog.csdn.net/rico_zhou/article/details/83619561
博客搬家系列(七)-本地WORD文档转HTML:https://blog.csdn.net/rico_zhou/article/details/83619573
博客搬家系列(八)-总结:https://blog.csdn.net/rico_zhou/article/details/83619599
二.开干(获取文章URL集合)
爬取今日头条的文章算是本系列中比较难的,不像其他如CSDN等网站,基本信息可以直接使用htmlunit就能爬取,但是当用同样的方法爬取今日头条时,则不行,很简单,我们随便找一多文章的博主,如https://www.toutiao.com/c/user/101528687217/ 打开主页,右击查看源码,我们发现源码中并不包含文章列表等信息,说明文章列表是js动态加载的,于是还是老规矩,先审查元素,查看一下都进行了哪些请求再说
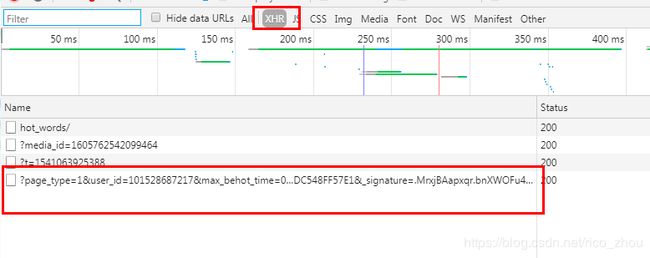
发现这个get请求正是我想要的,preview查看一下不难发现这里的数据即是文章列表,但是我却并没有在url中发现跟页数相关的参数,只是滚动会发现另一个请求,而且最后的三个参数as,cp,_signature是不一样的,当max_behot_time=0时,即第一页信息,随便更改这三个参数均能得到正确数据

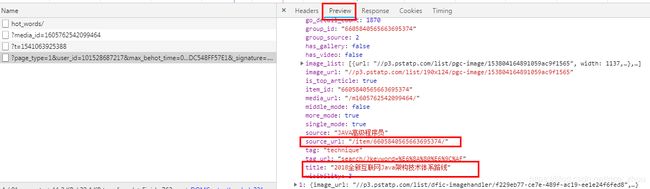
但是当不等于0的时候,即第2,3...页信息,则后面的三个参数就起了作用,不能随便了,其实想想也知道,这肯定是签名算法,防的就是我们现在的这个行为,哈哈,好吧,先说结果,目前我还没有找到有效的办法,但是可以将过程同大家分享一下,共同学习。
首先,这三个参数的加密算法是什么需要找到,然后才能破解,我们分析一下这条url
https://www.toutiao.com/c/user/article/?page_type=1&user_id=101528687217&max_behot_time=1539352612&count=20&as=A1851BCD7A2C7D8&cp=5BDADC373D48DE1&_signature=.MrxjBAapxqr.bnXWOFkBPzK8Z
前面的参数其实不用管如page_type,count,但是user_id和max_behot_time是变化的,user_id是已知的,那么max_behot_time是哪来的呢?
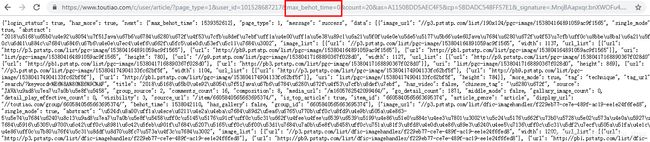
当我们首页信息时max_behot_time是0,下拉时变成了1539352612,这个过程中没有其他的请求发生,那么就是在第一次请求时返回的信息或者通过js计算的数据,首先检查一下首次返回的数据:

发现果然如此,这个参数我们是可以依次获取的,解决,那么as,cp,_signature这三个参数呢?刚刚分析,可能是js计算而来,那我们就把这几个关键字在所有的js文件中搜索一下,找到相关的js代码先
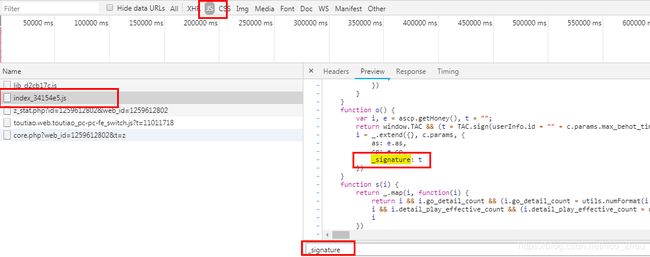
经搜索发现,我们找到了相关的js,即文件index_34154e5.js,将其下载下来分析,我们找到了as,cp这两个参数的算法
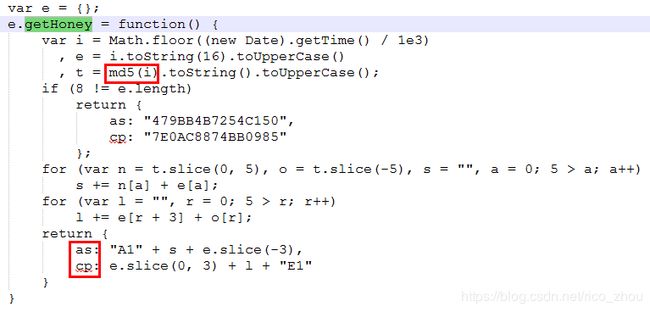
分析发现,这两个参数只是根据当前的时间经过md5加密生成的字符串,并没有用到user_id和max_behot_time参数,我们网上百度个md5算法或者引入md5js文件,简单写个html获取这两个参数试试看,

页面
。
。
经测试,这两个参数是可用的,那问题的关键就在于_signature这个参数了,同样搜索文件发现了算法

可以看出_signature这个值是需要参数user_id和max_behot_time作为参数经过方法TAC.sign签名之后获取的,那么现在就有两条路了
第一条路是破解这个_signature签名的算法,其实js中都有,我只要改成java实现,或者直接使用java执行js即可
第二条路是使用htmlunit动态的执行js方法TAC.sign()然后得到结果
先尝试第二种貌似比较简单的实现方法
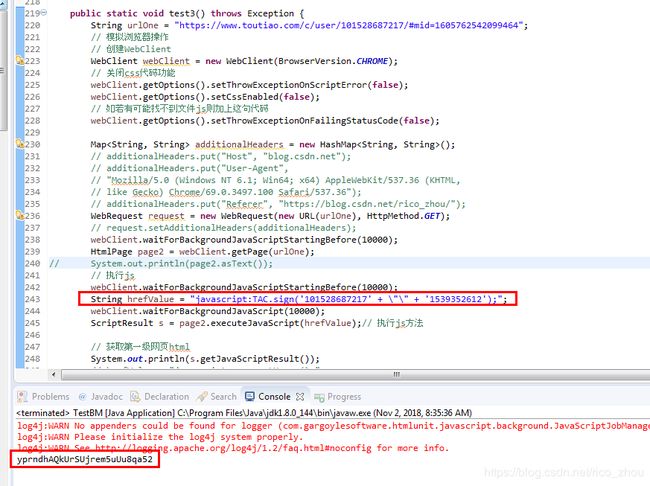
可是将其带入到url中依然无法得到正确结果,可能毕竟运行有差别吧,不做多想,再试试方案一!
加密算法在这

显然含有特殊字符,暂时不管,先复制到本地html中试试看,经测试发现是可以用的,但由于特殊字符的原因不太好改成java版,偶然间在网上搜索竟然发现有人对这个算法研究了,结果也很失望,主要是大多是Python版的且多失效或者是使用selenium需要浏览器,并不是我想要的,不过倒是这篇管用一点,链接忘了,找到了会在尾部贴出。主要是将带有特殊字符的加密算法去除,重点如下:
function e(e, a, r) {
return (b[e] || (b[e] = t("x,y", "return x " + e + " y")))(r, a)
}
function a(e, a, r) {
return (k[r] || (k[r] = t("x,y", "return new x[y](" + Array(r + 1).join(",x[++y]").substr(1) + ")")))(e, a)
}
function r(e, a, r) {
var n, t, s = {},
b = s.d = r ? r.d + 1 : 0;
for (s["$" + b] = s,
t = 0; t < b; t++)
s[n = "$" + t] = r[n];
for (t = 0,
b = s.length = a.length; t < b; t++)
s[t] = a[t];
return c(e, 0, s)
}
function c(t, b, k) {
function u(e) {
v[x++] = e
}
function f() {
return g = t.charCodeAt(b++) - 32,
t.substring(b, b += g)
}
function l() {
try {
y = c(t, b, k)
} catch (e) {
h = e,
y = l
}
}
for (var h, y, d, g, v = [], x = 0;;)
switch (g = t.charCodeAt(b++) - 32) {
case 1:
u(!v[--x]);
break;
case 4:
v[x++] = f();
break;
case 5:
u(function (e) {
var a = 0,
r = e.length;
return function () {
var c = a < r;
return c && u(e[a++]),
c
}
}(v[--x]));
break;
case 6:
y = v[--x],
u(v[--x](y));
break;
case 8:
if (g = t.charCodeAt(b++) - 32,
l(),
b += g,
g = t.charCodeAt(b++) - 32,
y === c)
b += g;
else if (y !== l)
return y;
break;
case 9:
v[x++] = c;
break;
case 10:
u(s(v[--x]));
break;
case 11:
y = v[--x],
u(v[--x] + y);
break;
case 12:
for (y = f(),
d = [],
g = 0; g < y.length; g++)
d[g] = y.charCodeAt(g) ^ g + y.length;
u(String.fromCharCode.apply(null, d));
break;
case 13:
y = v[--x],
h = delete v[--x][y];
break;
case 14:
v[x++] = t.charCodeAt(b++) - 32;
break;
case 59:
u((g = t.charCodeAt(b++) - 32) ? (y = x,
v.slice(x -= g, y)) : []);
break;
case 61:
u(v[--x][t.charCodeAt(b++) - 32]);
break;
case 62:
g = v[--x],
k[0] = 65599 * k[0] + k[1].charCodeAt(g) >>> 0;
break;
case 65:
h = v[--x],
y = v[--x],
v[--x][y] = h;
break;
case 66:
u(e(t.substr(b++, 1), v[--x], v[--x]));
break;
case 67:
y = v[--x];
d = v[--x];
g = v[--x];
u(g.x === c ? r(g.y, y, k) : g.apply(d, y));
break;
case 68:
u(e((g = t.substr(b++, 1)) < "<" ? (b--,
f()) : g + g, v[--x], v[--x]));
break;
case 70:
u(!1);
break;
case 71:
v[x++] = n;
break;
case 72:
v[x++] = +f();
break;
case 73:
u(parseInt(f(), 36));
break;
case 75:
if (v[--x]) {
b++;
break
}
case 74:
g = t.charCodeAt(b++) - 32 << 16 >> 16,
b += g;
break;
case 76:
u(k[t.charCodeAt(b++) - 32]);
break;
case 77:
y = v[--x],
u(v[--x][y]);
break;
case 78:
g = t.charCodeAt(b++) - 32,
u(a(v, x -= g + 1, g));
break;
case 79:
g = t.charCodeAt(b++) - 32,
u(k["$" + g]);
break;
case 81:
h = v[--x],
v[--x][f()] = h;
break;
case 82:
u(v[--x][f()]);
break;
case 83:
h = v[--x],
k[t.charCodeAt(b++) - 32] = h;
break;
case 84:
v[x++] = !0;
break;
case 85:
v[x++] = void 0;
break;
case 86:
u(v[x - 1]);
break;
case 88:
h = v[--x],
y = v[--x],
v[x++] = h,
v[x++] = y;
break;
case 89:
u(function () {
function e() {
return r(e.y, arguments, k)
}
return e.y = f(),
e.x = c,
e
}());
break;
case 90:
v[x++] = null;
break;
case 91:
v[x++] = h;
break;
case 93:
h = v[--x];
break;
case 0:
return v[--x];
default:
u((g << 16 >> 16) - 16)
}
}
var n = window;
var t = n.Function,
s = Object.keys || function (e) {
var a = {},
r = 0;
for (var c in e)
a[r++] = c;
return a.length = r,
a
},
b = {},
k = {};
console.log(t('x','return x+1'))
r(decodeURIComponent("gr%24Daten%20%D0%98b%2Fs!l%20y%CD%92y%C4%B9g%2C(lfi~ah%60%7Bmv%2C-n%7CjqewVxp%7Brvmmx%2C%26eff%7Fkx%5B!cs%22l%22.Pq%25widthl%22%40q%26heightl%22vr*getContextx%24%222d%5B!cs%23l%23%2C*%3B%3F%7Cu.%7Cuc%7Buq%24fontl%23vr(fillTextx%24%24%E9%BE%98%E0%B8%91%E0%B8%A0%EA%B2%BD2%3C%5B%23c%7Dl%232q*shadowBlurl%231q-shadowOffsetXl%23%24%24limeq%2BshadowColorl%23vr%23arcx88802%5B%25c%7Dl%23vr%26strokex%5B%20c%7Dl%22v%2C)%7DeOmyoZB%5Dmx%5B%20cs!0s%24l%24Pb%3Ck7l%20l!r%26lengthb%25%5El%241%2Bs%24j%02l%20%20s%23i%241ek1s%24gr%23tack4)zgr%23tac%24!%20%2B0o!%5B%23cj%3Fo%20%5D!l%24b%25s%22o%20%5D!l%22l%24b*b%5E0d%23%3E%3E%3Es!0s%25yA0s%22l%22l!r%26lengthb%3Ck%2Bl%22%5El%221%2Bs%22j%05l%20%20s%26l%26z0l!%24%20%2B%5B%22cs'(0l%23i'1ps9wxb%26s()%20%26%7Bs)%2Fs(gr%26Stringr%2CfromCharCodes)0s*yWl%20._b%26s%20o!%5D)l%20l%20Jb%3Ck%24.aj%3Bl%20.Tb%3Ck%24.gj%2Fl%20.%5Eb%3Ck%26i%22-4j!%1F%2B%26%20s%2ByPo!%5D%2Bs!l!l%20Hd%3E%26l!l%20Bd%3E%26%2Bl!l%20%3Cd%3E%26%2Bl!l%206d%3E%26%2Bl!l%20%26%2B%20s%2Cy%3Do!o!%5D%2Fq%2213o!l%20q%2210o!%5D%2Cl%202d%3E%26%20s.%7Bs-yMo!o!%5D0q%2213o!%5D*Ld%3Cl%204d%23%3E%3E%3Eb%7Cs!o!l%20q%2210o!%5D%2Cl!%26%20s%2FyIo!o!%5D.q%2213o!%5D%2Co!%5D*Jd%3Cl%206d%23%3E%3E%3Eb%7C%26o!%5D%2Bl%20%26%2B%20s0l-l!%26l-l!i'1z141z4b%2F%40d%3Cl%22b%7C%26%2Bl-l(l!b%5E%26%2Bl-l%26zl'g%2C)gk%7Dejo%7B%7Fcm%2C)%7Cyn~Lij~em%5B%22cl%24b%25%40d%3Cl%26zl'l%20%24%20%2B%5B%22cl%24b%25b%7C%26%2Bl-l%258d%3C%40b%7Cl!b%5E%26%2B%20q%24sign%20"), [TAC = {}]);
tt = TAC.sign(user_id+"" + max_behot_time);惊喜发现,将其嵌入到html中浏览器打开得到的参数是可以使用的,这是个好消息,接着就是冷水,当我使用htmlunit读取本地html时,也能得到参数,但是参数不可用,与方案二一样,然后我又将此网页嵌入到自己的网站,使用htmlunit模拟爬取自己的这个网页,同样,得到的参数也是不能使用。至此,陷入了困境!结果不重要(其实也很重要),享受的是过程!暂时先这样吧。
虽然不能获取后续加载的文章列表,但是首次加载的文章还是可以获取的,下面分析一下吧,文章列表都在那个json中
/**
* @date Oct 17, 2018 12:30:46 PM
* @Desc
* @param blogMove
* @param oneUrl
* @return
* @throws IOException
* @throws MalformedURLException
* @throws FailingHttpStatusCodeException
*/
public String getTouTiaoArticleUrlList(Blogmove blogMove, String oneUrl, List urlList)
throws FailingHttpStatusCodeException, MalformedURLException, IOException {
String max_behot_time = "0";
// 模拟浏览器操作
// 创建WebClient
WebClient webClient = new WebClient(BrowserVersion.CHROME);
// 关闭css代码功能
webClient.getOptions().setThrowExceptionOnScriptError(false);
webClient.getOptions().setCssEnabled(false);
// 如若有可能找不到文件js则加上这句代码
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
Map additionalHeaders = new HashMap();
additionalHeaders.put("user-agent",
"Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36");
WebRequest request = new WebRequest(new URL(oneUrl), HttpMethod.GET);
request.setAdditionalHeaders(additionalHeaders);
UnexpectedPage page2 = webClient.getPage(request);
String result = IOUtils.toString(page2.getInputStream(), StandardCharsets.UTF_8);
JSONObject json = JSON.parseObject(result);
JSONArray jsonarray = (JSONArray) json.get("data");
JSONObject json2 = (JSONObject) json.get("next");
// 用于返回留下一页使用
max_behot_time = json2.getString("max_behot_time");
// 读取url
JSONObject jsonObject;
String url;
for (Object obj : jsonarray) {
jsonObject = (JSONObject) obj;
url = jsonObject.getString("source_url");
if (url != null) {
url = url.substring(6, url.length() - 1);
if (urlList.size() < blogMove.getMoveNum()) {
urlList.add("https://www.toutiao.com/i" + url);
} else {
break;
}
} else {
url = "";
continue;
}
}
return max_behot_time;
}
三.开干(获取文章具体信息)
接下来直接找一篇文章分析一下:https://www.toutiao.com/i6616645307906130435/
分析发现,数据在script标签中的变量BASE_DATA 中,解析即可得
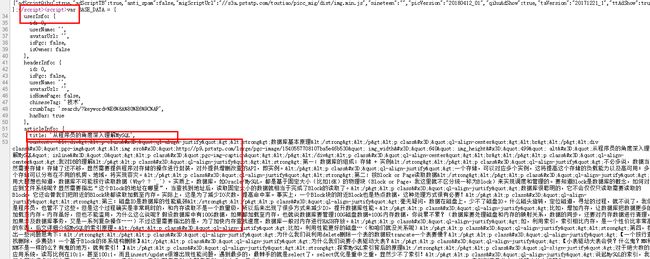

代码
/**
* @date Oct 17, 2018 12:46:52 PM
* @Desc 获取详细信息
* @param blogMove
* @param url
* @return
* @throws IOException
* @throws MalformedURLException
* @throws FailingHttpStatusCodeException
*/
public Blogcontent getTouTiaoArticleMsg(Blogmove blogMove, String url, List bList)
throws FailingHttpStatusCodeException, MalformedURLException, IOException {
Blogcontent blogcontent = new Blogcontent();
blogcontent.setArticleSource(blogMove.getMoveWebsiteId());
// 模拟浏览器操作
// 创建WebClient
WebClient webClient = new WebClient(BrowserVersion.CHROME);
// 关闭css代码功能
webClient.getOptions().setThrowExceptionOnScriptError(false);
webClient.getOptions().setCssEnabled(false);
// 如若有可能找不到文件js则加上这句代码
webClient.getOptions().setThrowExceptionOnFailingStatusCode(false);
// 获取第一级网页html
HtmlPage page = webClient.getPage(url);
Document doc = Jsoup.parse(page.asXml());
Elements pageMsg22 = doc.body().getElementsByTag("script");
String msgJsonString = BlogMoveTouTiaoUtils.getTouTiaoArticleMsgJsonString(pageMsg22);
String content = null;
String title = null;
String author = null;
Date date = null;
if (msgJsonString != null && !"".equals(msgJsonString)) {
// 解析
JSONObject json = JSON.parseObject(msgJsonString);
json = (JSONObject) json.get("articleInfo");
content = json.getString("content");
// 转义
content = StringEscapeUtils.unescapeHtml3(content);
title = json.getString("title");
json = (JSONObject) json.get("subInfo");
author = json.getString("source");
date = DateUtils.formatStringDate(json.getString("time"), DateUtils.YYYY_MM_DD_HH_MM_SS);
date = date == null ? new Date() : date;
}
// 是否重复去掉
if (blogMove.getMoveRemoveRepeat() == 0) {
// 判断是否重复
if (BlogMoveCommonUtils.articleRepeat(bList, title)) {
return null;
}
}
blogcontent.setTitle(title);
// 获取作者
blogcontent.setAuthor(author);
// 获取时间
if (blogMove.getMoveUseOriginalTime() == 0) {
blogcontent.setGtmCreate(date);
} else {
blogcontent.setGtmCreate(new Date());
}
blogcontent.setGtmModified(new Date());
// 获取类型
blogcontent.setType("原创");
// 获取正文
blogcontent.setContent(BlogMoveTouTiaoUtils.getTouTiaoArticleContent(content, blogMove, blogcontent));
// 设置其他
blogcontent.setStatus(blogMove.getMoveBlogStatus());
blogcontent.setBlogColumnName(blogMove.getMoveColumn());
// 特殊处理
blogcontent.setArticleEditor(blogMove.getMoveArticleEditor());
blogcontent.setShowId(DateUtils.format(new Date(), DateUtils.YYYYMMDDHHMMSSSSS));
blogcontent.setAllowComment(0);
blogcontent.setAllowPing(0);
blogcontent.setAllowDownload(0);
blogcontent.setShowIntroduction(1);
blogcontent.setIntroduction("");
blogcontent.setPrivateArticle(1);
return blogcontent;
}
幸运的是,图片下载没有遇到困难,效果:
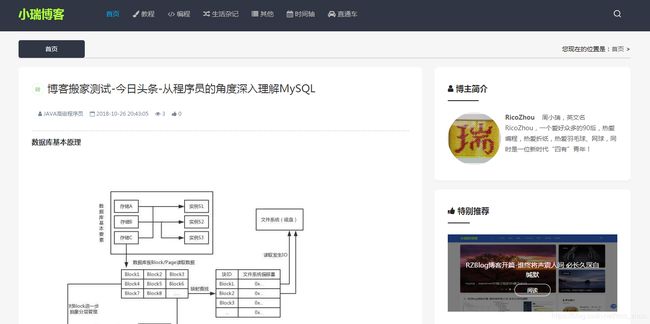
欢迎交流学习!
完整源码请见github:https://github.com/ricozhou/blogmove