Spark SQL从入门到精通
本文主要是帮助大家从入门到精通掌握spark sql。篇幅较长,内容较丰富建议大家收藏,仔细阅读。
更多大数据,spark教程,请点击 阅读原文 加入浪尖知识星球获取。
微信群可以加浪尖微信 158570986 。
发家史熟悉spark sql的都知道,spark sql是从shark发展而来。Shark为了实现Hive兼容,在HQL方面重用了Hive中HQL的解析、逻辑执行计划翻译、执行计划优化等逻辑,可以近似认为仅将物理执行计划从MR作业替换成了Spark作业(辅以内存列式存储等各种和Hive关系不大的优化);
同时还依赖Hive Metastore和Hive SerDe(用于兼容现有的各种Hive存储格式)。
Spark SQL在Hive兼容层面仅依赖HQL parser、Hive Metastore和Hive SerDe。也就是说,从HQL被解析成抽象语法树(AST)起,就全部由Spark SQL接管了。执行计划生成和优化都由Catalyst负责。借助Scala的模式匹配等函数式语言特性,利用Catalyst开发执行计划优化策略比Hive要简洁得多。
Spark SQL
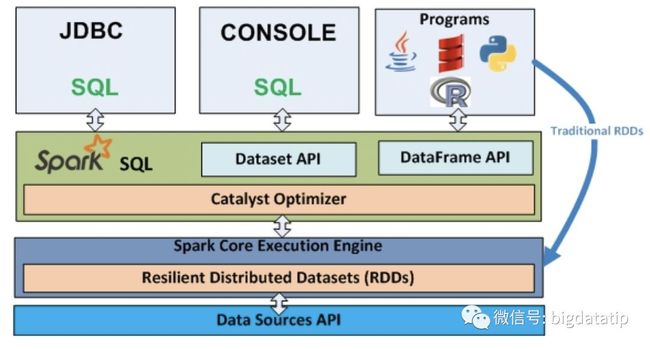
spark sql提供了多种接口:
1. 纯Sql 文本
2. dataset/dataframe api
当然,相应的,也会有各种客户端:
sql文本,可以用thriftserver/spark-sql
编码,Dataframe/dataset/sql
Dataframe/Dataset API简介
Dataframe/Dataset也是分布式数据集,但与RDD不同的是其带有schema信息,类似一张表。
可以用下面一张图详细对比Dataset/dataframe和rdd的区别:

Dataset是在spark1.6引入的,目的是提供像RDD一样的强类型、使用强大的lambda函数,同时使用spark sql的优化执行引擎。到spark2.0以后,DataFrame变成类型为Row的Dataset,即为:
type DataFrame = Dataset[Row]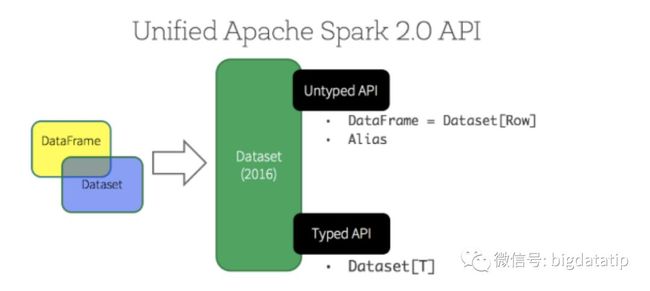
所以,很多移植spark1.6及之前的代码到spark2+的都会报错误,找不到dataframe类。
基本操作
val df = spark.read.json(“file:///opt/meitu/bigdata/src/main/data/people.json”)
df.show()
import spark.implicits._
df.printSchema()
df.select("name").show()
df.select($"name", $"age" + 1).show()
df.filter($"age" > 21).show()
df.groupBy("age").count().show()
spark.stop()分区分桶 排序
分桶排序保存hive表
df.write.bucketBy(42,“name”).sortBy(“age”).saveAsTable(“people_bucketed”)
分区以parquet输出到指定目录
df.write.partitionBy("favorite_color").format("parquet").save("namesPartByColor.parquet")
分区分桶保存到hive表
df.write .partitionBy("favorite_color").bucketBy(42,"name").saveAsTable("users_partitioned_bucketed")cube rullup pivot
cube
sales.cube("city", "year”).agg(sum("amount")as "amount”) .show()
rull up
sales.rollup("city", "year”).agg(sum("amount")as "amount”).show()
pivot 只能跟在groupby之后
sales.groupBy("year").pivot("city",Seq("Warsaw","Boston","Toronto")).agg(sum("amount")as "amount”).show()SQL编程
Spark SQL允许用户提交SQL文本,支持一下三种手段编写sql文本:
1. spark 代码
2. spark-sql的shell
3. thriftserver
支持Spark SQL自身的语法,同时也兼容HSQL。
1. 编码
要先声明构建SQLContext或者SparkSession,这个是SparkSQL的编码入口。早起的版本使用的是SQLContext或者HiveContext,spark2以后,建议使用的是SparkSession。
1. SQLContext
new SQLContext(SparkContext)
2. HiveContext
new HiveContext(spark.sparkContext)
3. SparkSession
不使用hive元数据:
val spark = SparkSession.builder()
.config(sparkConf) .getOrCreate()
使用hive元数据
val spark = SparkSession.builder()
.config(sparkConf) .enableHiveSupport().getOrCreate()使用
val df =spark.read.json("examples/src/main/resources/people.json")
df.createOrReplaceTempView("people")
spark.sql("SELECT * FROM people").show()2. spark-sql脚本
spark-sql 启动的时候类似于spark-submit 可以设置部署模式资源等,可以使用
bin/spark-sql –help 查看配置参数。
需要将hive-site.xml放到${SPARK_HOME}/conf/目录下,然后就可以测试
show tables;
select count(*) from student;3. thriftserver
thriftserver jdbc/odbc的实现类似于hive1.2.1的hiveserver2,可以使用spark的beeline命令来测试jdbc server。
安装部署
1). 开启hive的metastore
bin/hive --service metastore
2). 将配置文件复制到spark/conf/目录下
3). thriftserver
sbin/start-thriftserver.sh --masteryarn --deploy-mode client
对于yarn只支持client模式
4). 启动bin/beeline
5). 连接到thriftserver
!connect jdbc:hive2://localhost:10001用户自定义函数
1. UDF
定义一个udf很简单,例如我们自定义一个求字符串长度的udf。
val len = udf{(str:String) => str.length}
spark.udf.register("len",len)
val ds =spark.read.json("file:///opt/meitu/bigdata/src/main/data/employees.json")
ds.createOrReplaceTempView("employees")
ds.show()
spark.sql("select len(name) from employees").show()2. UserDefinedAggregateFunction
定义一个UDAF
import org.apache.spark.sql.{Row, SparkSession}
import org.apache.spark.sql.expressions.MutableAggregationBuffer
import org.apache.spark.sql.expressions.UserDefinedAggregateFunction
import org.apache.spark.sql.types._
object MyAverageUDAF extends UserDefinedAggregateFunction {
//Data types of input arguments of this aggregate function
definputSchema:StructType = StructType(StructField("inputColumn", LongType) :: Nil)
//Data types of values in the aggregation buffer
defbufferSchema:StructType = {
StructType(StructField("sum", LongType):: StructField("count", LongType) :: Nil)
}
//The data type of the returned value
defdataType:DataType = DoubleType
//Whether this function always returns the same output on the identical input
defdeterministic: Boolean = true
//Initializes the given aggregation buffer. The buffer itself is a `Row` that inaddition to
// standard methods like retrieving avalue at an index (e.g., get(), getBoolean()), provides
// the opportunity to update itsvalues. Note that arrays and maps inside the buffer are still
// immutable.
definitialize(buffer:MutableAggregationBuffer): Unit = {
buffer(0) = 0L
buffer(1) = 0L
}
//Updates the given aggregation buffer `buffer` with new input data from `input`
defupdate(buffer:MutableAggregationBuffer, input: Row): Unit ={
if(!input.isNullAt(0)) {
buffer(0) = buffer.getLong(0)+ input.getLong(0)
buffer(1) = buffer.getLong(1)+ 1
}
}
// Mergestwo aggregation buffers and stores the updated buffer values back to `buffer1`
defmerge(buffer1:MutableAggregationBuffer, buffer2: Row): Unit ={
buffer1(0) = buffer1.getLong(0)+ buffer2.getLong(0)
buffer1(1) = buffer1.getLong(1)+ buffer2.getLong(1)
}
//Calculates the final result
defevaluate(buffer:Row): Double =buffer.getLong(0).toDouble /buffer.getLong(1)
}使用UDAF
val ds = spark.read.json("file:///opt/meitu/bigdata/src/main/data/employees.json")
ds.createOrReplaceTempView("employees")
ds.show()
spark.udf.register("myAverage", MyAverageUDAF)
val result = spark.sql("SELECT myAverage(salary) as average_salary FROM employees")
result.show()3. Aggregator
定义一个Aggregator
import org.apache.spark.sql.{Encoder, Encoders, SparkSession}
import org.apache.spark.sql.expressions.Aggregator
case class Employee(name: String, salary: Long)
case class Average(var sum: Long, var count: Long)
object MyAverageAggregator extends Aggregator[Employee, Average, Double] {
// A zero value for this aggregation. Should satisfy the property that any b + zero = b
def zero: Average = Average(0L, 0L)
// Combine two values to produce a new value. For performance, the function may modify `buffer`
// and return it instead of constructing a new object
def reduce(buffer: Average, employee: Employee): Average = {
buffer.sum += employee.salary
buffer.count += 1
buffer
}
// Merge two intermediate values
def merge(b1: Average, b2: Average): Average = {
b1.sum += b2.sum
b1.count += b2.count
b1
}
// Transform the output of the reduction
def finish(reduction: Average): Double = reduction.sum.toDouble / reduction.count
// Specifies the Encoder for the intermediate value type
def bufferEncoder: Encoder[Average] = Encoders.product
// Specifies the Encoder for the final output value type
def outputEncoder: Encoder[Double] = Encoders.scalaDouble
}使用
spark.udf.register("myAverage2", MyAverageAggregator)
import spark.implicits._
val ds = spark.read.json("file:///opt/meitu/bigdata/src/main/data/employees.json").as[Employee]
ds.show()
val averageSalary = MyAverageAggregator.toColumn.name("average_salary")
val result = ds.select(averageSalary)
result.show() 数据源
1. 通用的laod/save函数
可支持多种数据格式:json, parquet, jdbc, orc, libsvm, csv, text
val peopleDF = spark.read.format("json").load("examples/src/main/resources/people.json")
peopleDF.select("name", "age").write.format("parquet").save("namesAndAges.parquet")
默认的是parquet,可以通过spark.sql.sources.default,修改默认配置。
2. Parquet 文件
val parquetFileDF =spark.read.parquet("people.parquet")
peopleDF.write.parquet("people.parquet")3. ORC 文件
val ds = spark.read.json("file:///opt/meitu/bigdata/src/main/data/employees.json")
ds.write.mode("append").orc("/opt/outputorc/")
spark.read.orc("/opt/outputorc/*").show(1)
4. JSON
ds.write.mode("overwrite").json("/opt/outputjson/")
spark.read.json("/opt/outputjson/*").show()
5. Hive 表
spark 1.6及以前的版本使用hive表需要hivecontext。
Spark2开始只需要创建sparksession增加enableHiveSupport()即可。
val spark = SparkSession
.builder()
.config(sparkConf)
.enableHiveSupport()
.getOrCreate()
spark.sql("select count(*) from student").show()6. JDBC
写入mysql
wcdf.repartition(1).write.mode("append").option("user", "root")
.option("password", "mdh2018@#").jdbc("jdbc:mysql://localhost:3306/test","alluxio",new Properties())
从mysql里读
val fromMysql = spark.read.option("user", "root")
.option("password", "mdh2018@#").jdbc("jdbc:mysql://localhost:3306/test","alluxio",new Properties())
7. 自定义数据源
自定义source比较简单,首先我们要看看source加载的方式
指定的目录下,定义一个DefaultSource类,在类里面实现自定义source。就可以实现我们的目标。
import org.apache.spark.sql.sources.v2.{DataSourceOptions, DataSourceV2, ReadSupport}
class DefaultSource extends DataSourceV2 with ReadSupport {
def createReader(options: DataSourceOptions) = new SimpleDataSourceReader()
}
import org.apache.spark.sql.Row
import org.apache.spark.sql.sources.v2.reader.{DataReaderFactory, DataSourceReader}
import org.apache.spark.sql.types.{StringType, StructField, StructType}
class SimpleDataSourceReader extends DataSourceReader {
def readSchema() = StructType(Array(StructField("value", StringType)))
def createDataReaderFactories = {
val factoryList = new java.util.ArrayList[DataReaderFactory[Row]]
factoryList.add(new SimpleDataSourceReaderFactory())
factoryList
}
}
import org.apache.spark.sql.Row
import org.apache.spark.sql.sources.v2.reader.{DataReader, DataReaderFactory}
class SimpleDataSourceReaderFactory extends
DataReaderFactory[Row] with DataReader[Row] {
def createDataReader = new SimpleDataSourceReaderFactory()
val values = Array("1", "2", "3", "4", "5")
var index = 0
def next = index < values.length
def get = {
val row = Row(values(index))
index = index + 1
row
}
def close() = Unit
}
使用
val simpleDf = spark.read
.format("bigdata.spark.SparkSQL.DataSources")
.load()
simpleDf.show()
1. 流程简介
整体流程如下:
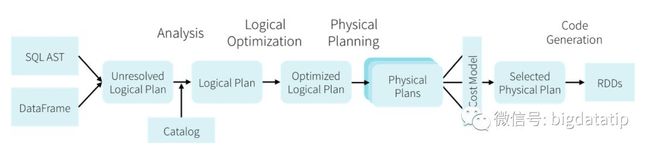
总体执行流程如下:从提供的输入API(SQL,Dataset, dataframe)开始,依次经过unresolved逻辑计划,解析的逻辑计划,优化的逻辑计划,物理计划,然后根据cost based优化,选取一条物理计划进行执行.
简单化成四个部分:
1). analysis
Spark 2.0 以后语法树生成使用的是antlr4,之前是scalaparse。
2). logical optimization
常量合并,谓词下推,列裁剪,boolean表达式简化,和其它的规则
3). physical planning
eg:SortExec
4). Codegen
codegen技术是用scala的字符串插值特性生成源码,然后使用Janino,编译成java字节码。Eg: SortExec2. 自定义优化器
1). 实现
继承Rule[LogicalPlan]
2). 注册
spark.experimental.extraOptimizations= Seq(MultiplyOptimizationRule)3). 使用
selectExpr("amountPaid* 1")3. 自定义执行计划
主要是实现重载count函数的功能
1). 物理计划:
继承SparkLan实现doExecute方法
2). 逻辑计划
继承SparkStrategy实现apply
3). 注册到Spark执行策略:
spark.experimental.extraStrategies =Seq(countStrategy)4). 使用
spark.sql("select count(*) fromtest")推荐阅读:
必读|spark的重分区及排序
Spark的PIDController源码赏析及backpressure详解
