DTW 算法的实时语音识别——命令词识别(Python 实现)
介绍
这是我们计算机视听觉的第三个实验,也是本学期语音部分的最后一个实验,大概花了两天才写完。上个实验做的是语音编码问题,这个实验是语音识别的事,感觉处理语音还是比较有意思的。
附上实验代码地址:实验三
注意:运行的时候,需要更改我代码中的地址路径,虽然没几个路径,但有些是绝对路径,不更改是运行不了的。
实验要求
-
设计命令词识别任务
- 设想一个任务,如智能家居、或车辆控制等
- 确定词表,要求词表中不少于10个词
- 录制语料。采集特定人(自己)语料,每个词不少于五遍。取其中一遍为模板,其它四遍用来测试。可以用采集工具(如cooledit)或编程实现语音采集。
- 检查语料。通过听辩检查保证语料质量。
- 去除静音。可以用端点检测算法实现,也可以手工实现
-
特征提取
- 每帧提取39维MFCC特征,帧长25ms,帧移10ms
- 可以采用HTK工具包中的hcopy命令实现(要求语料是WAV格式)
hcopy -A -D -T 1 -C tr_wav.cfg -S .\data\list.scp
-
识别测试
- N个模板,M个待测命令词语料,进行NM次DTW计算,得到NM个DTW距离
- 分别载入模板和待测语料的MFCC特征矢量序列
- 计算两个特征序列的 DTW 距离
- N个模板,M个待测命令词语料,进行NM次DTW计算,得到NM个DTW距离
-
计算测试结果
- 每个测试语料都有一个类别标签 l i l_i li
- 每个测试语料都有一个识别结果 r i r_i ri
- r i = m a x D i j r_i = maxD_{ij} ri=maxDij 其中, D i j D_{ij} Dij 为第 i 个测试语料和第 j 个模板间的DTW距离(规整后)
- 若 r i = l i r_i = l_i ri=li 表示识别结果正确
- 计算正确率=识别结果正确的语料数/总测试语料数
-
扩展尝试
- 开集扩展:采集一批集外命令词,重新计算正确率?
- 实用扩展:将经过实验验证的算法,转化为能实时采集,在线检测的命令词识别系统?(这里我做的就是这个扩展)
- 算法扩展:尝试基于HMM的识别算法?
提取 MFCC 特征
对于 39 维的 MFCC 特征,这里直接使用老师给的 HTK 中的 Hcopy 工具进行提取。即使是对实时录取的语音,也是在代码中动态对其进行特征提取。对于特征的提取这里就不详细描述了。
DTW 算法
一共录制十组特定人的命令词,每组 5 个,一共 50 个。每组的第一个取出,作为模板。剩余的 40 个语音命令作为测试样例,测试 DTW 算法。
算法简介
由于即使同一个人不同时间发出同一个声音,也不可能具有相同的长度,因此就需要用到动态时间归正(DTW)算法。把时间归正和距离测度计算结合起来的一种非线性归正技术。
DTW 本质上是一个简单的动态规划算法,是用来计算两个维数不同的向量之间的相似度的问题,即计算向量 M1 和 M2 的最短距离。是一种非常常用的语音匹配算法,算法如下。
算法思想
对两个不同维数的语音向量 m1 和 m2进行匹配(m1 和 m2 的每一维也是一个向量,是语音每一帧的特征值,这里利用的是 MFCC 特征)。设两个向量的长度为 M1 和 M2,则距离可以表示为:
D ( X 1 , X 2 ) = ∑ i = 1 M d ( x 1 i , x 2 i ) D(X_1, X_2) = \sum_{i = 1}^Md(x_{1i}, x_{2i}) D(X1,X2)=i=1∑Md(x1i,x2i)
那么,就可以这样进行匹配:

- 每一条从(1,1)倒(M1,M2)路径都有一个累计距离称为路径的代价.
- 每一条路径都代表一种对齐情况
- 代价最小的路径就是所求的对准路径。
这样就可以将对准问题,或者说将求两个语音段的相似度问题,转化成了搜索代价最小的最优路径问题。
在搜索过程中,往往要进行路径的限制:

在此限制条件下,可以将全局最优化问题转化为许多局部最优化问题一步一步地来求解,这就动态规划(Dynamic Programming,简称DP )的思想。
算法步骤
- 初始化:

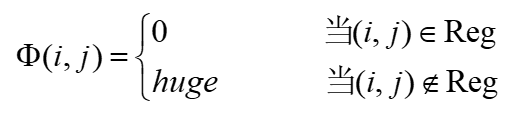
其中约束区域Reg可以假定是这样一个平行四边形,它有两个顶点位于(1,1)和(M1,M2),相邻两条边的斜率分别为2和1/2。
- 递推求累计距离 并记录回溯信息:
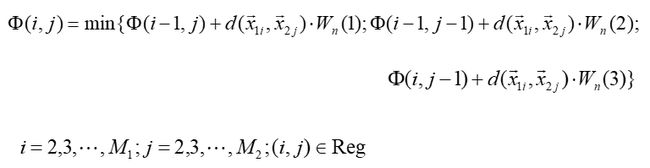
一般取距离加权值为:

- 计算出的值就是 m1 和 m2 之间的距离。(有时还需要进行归正,不过这里并没有写)
代码——Python 实现
# DTW 算法...
def dtw(M1, M2) :
# 初始化数组 大小为 M1 * M2
M1_len = len(M1)
M2_len = len(M2)
cost = [[0 for i in range(M2_len)] for i in range(M1_len)]
# 初始化 dis 数组
dis = []
for i in range(M1_len) :
dis_row = []
for j in range(M2_len) :
dis_row.append(distance(M1[i], M2[j]))
dis.append(dis_row)
# 初始化 cost 的第 0 行和第 0 列
cost[0][0] = dis[0][0]
for i in range(1, M1_len) :
cost[i][0] = cost[i - 1][0] + dis[i][0]
for j in range(1, M2_len) :
cost[0][j] = cost[0][j - 1] + dis[0][j]
# 开始动态规划
for i in range(1, M1_len) :
for j in range(1, M2_len) :
cost[i][j] = min(cost[i - 1][j] + dis[i][j] * 1, \
cost[i- 1][j - 1] + dis[i][j] * 2, \
cost[i][j - 1] + dis[i][j] * 1)
return cost[M1_len - 1][M2_len - 1]
# 两个维数相等的向量之间的距离
def distance(x1, x2) :
sum = 0
for i in range(len(x1)) :
sum = sum + abs(x1[i] - x2[i])
return sum
语音实时录取
这里调用的是 Python 的库,还是比较简单的,不详细介绍这个库了,直接附上代码:
# 将语音文件存储成 wav 格式
def save_wave_file(filename, data):
'''save the date to the wavfile'''
wf = wave.open(filename,'wb')
wf.setnchannels(channels) # 声道
wf.setsampwidth(sampwidth) # 采样字节 1 or 2
wf.setframerate(framerate) # 采样频率 8000 or 16000
wf.writeframes(b"".join(data))
wf.close()
# 录音
pa = pyaudio.PyAudio()
stream = pa.open(format = pyaudio.paInt16, channels = 1, \
rate = framerate , input = True, \
frames_per_buffer = CHUNK)
print("开始录音,请说话......")
frames = []
for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)):
data = stream.read(CHUNK)
frames.append(data)
print("录音结束,请停止说话!!!")
# 存储刚录制的语音文件
save_wave_file("./RecordedVoice-RealTime/recordedVoice_before.wav", frames)
端点检测
这里需要对识别的语音进行端点检测,否则正确率会很低。我就直接使用了实验一的代码了,只不过将它改成了一个类,在该代码中导入了该类,并且修改了存储文件的格式,效果都是一样的,算是一个进化版吧。具体代码请看我的链接,此处就不粘贴了。
动态提取 MFCC 特征
# 利用 HCopy 工具对录取的语音进行 MFCC 特征提取
os.chdir("C:\\Users\\13144\\Desktop\\Computer-VisionandAudio-Lab\\lab3\HTK-RealTimeRecordedVoice")
os.system("hcopy -A -D -T 1 -C tr_wav.cfg -S .\list.scp")
os.chdir("C:\\Users\\13144\\Desktop\\Computer-VisionandAudio-Lab\\lab3")
进行匹配
# 对录好的语音进行匹配
MFCC_recorded = getMFCCRecorded()
# 进行匹配
flag = 0
min_dis = dtw(MFCC_recorded, MFCC_models[0])
for j in range(1, len(MFCC_models)) :
dis = dtw(MFCC_recorded, MFCC_models[j])
if dis < min_dis :
min_dis = dis
flag = j
print( "\t" + str(flag + 1) + "\n")
总结
本次实验的重点在于 DTW 算法的书写,其他部分都比较简单。这里粘贴的代码并不完全,只是挑最主要的粘贴了一部分,完整的代码在我的代码仓库里,再粘贴一下链接:实验三。写得比较基础,欢迎各位给出改进意见。