大话文本识别经典模型:CRNN
在前一篇文章中(详见本博客文章:大话文本检测经典模型 CTPN),介绍了文字识别在现实生活中的广泛应用,以及文字识别的简单流程:

其中“文本检测”、“文本识别”是其中两个关键环节,“文本检测”已经在前一篇文章中介绍了详细的介绍,本文主要介绍“文本识别”的经典模型CRNN及其原理。
在介绍CRNN之前,先来梳理一下要实现“文本识别”的模型,需要具备哪些要素:
(1)首先是要读取输入的图像,提取图像特征,因此,需要有个卷积层用于读取图像和提取特征。具体原理可详见本公众号的文章:白话卷积神经网络(CNN);
(2)由于文本序列是不定长的,因此在模型中需要引入RNN(循环神经网络),一般是使用双向LSTM来处理不定长序列预测的问题。具体原理可详见本公众号的文章:白话循环神经网络(RNN);
(3)为了提升模型的适用性,最好不要要求对输入字符进行分割,直接可进行端到端的训练,这样可减少大量的分割标注工作,这时就要引入CTC模型(Connectionist temporal classification, 联接时间分类),来解决样本的分割对齐的问题。
(4)最后根据一定的规则,对模型输出结果进行纠正处理,输出正确结果。
以上就是“文本识别”模型的几个必须具备的要素。
接下来要介绍的CRNN模型,也是基本由这几部分组成的。
1、什么是CRNN
CRNN(Convolutional Recurrent Neural Network,卷积循环神经网络),是华中科技大学在发表的论文《An End-to-End Trainable Neural Network for Image-based Sequence Recognition and ItsApplication to Scene Text Recognition》提出的一个识别文本的方法,该模型主要用于解决基于图像的序列识别问题,特别是场景文字识别问题。
CRNN的主要特点是:
(1)可以进行端到端的训练;
(2)不需要对样本数据进行字符分割,可识别任意长度的文本序列
(3)模型速度快、性能好,并且模型很小(参数少)
2、CRNN模型结构
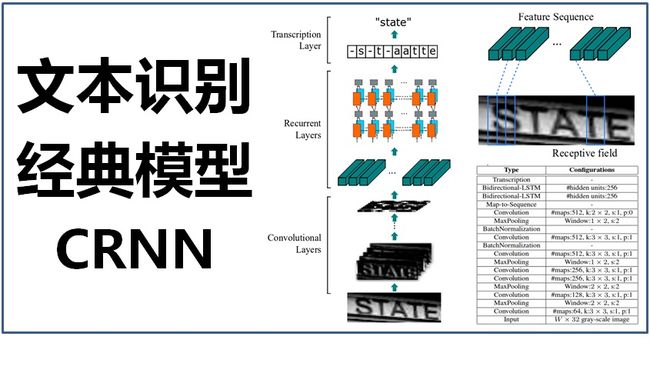
CRNN模型的结构如下:
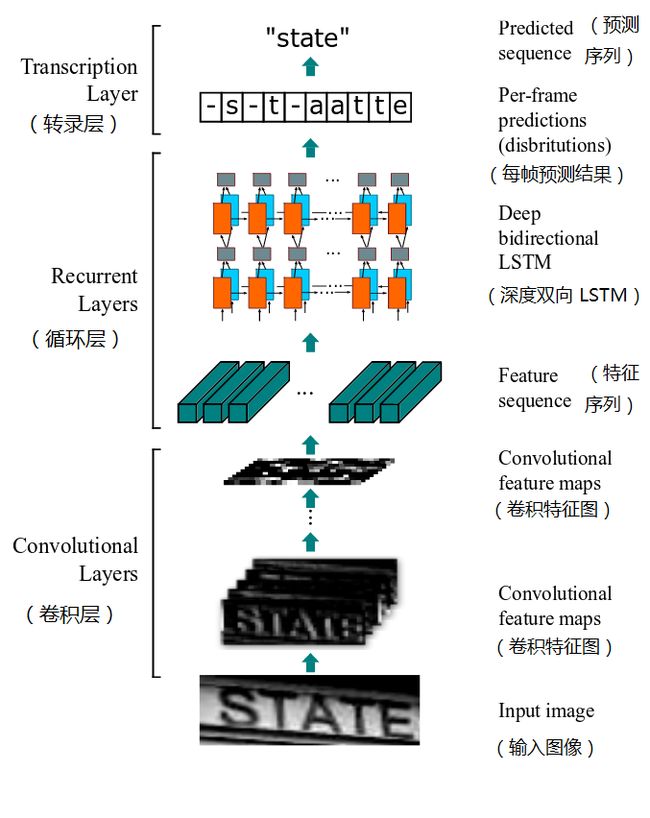
正如前面梳理的“文本识别”模型必须具备的要素,CRNN模型主要由以下三部分组成:
(1)卷积层:从输入图像中提取出特征序列;
(2)循环层:预测从卷积层获取的特征序列的标签分布;
(3)转录层:把从循环层获取的标签分布通过去重、整合等操作转换成最终的识别结果。
下面将展开对这三个层进行介绍:
(1)卷积层
① 预处理
CRNN对输入图像先做了缩放处理,把所有输入图像缩放到相同高度,默认是32,宽度可任意长。
② 卷积运算
由标准的CNN模型中的卷积层和最大池化层组成,结构类似于VGG,如下图:

从上图可以看出,卷积层是由一系列的卷积、最大池化、批量归一化等操作组成。
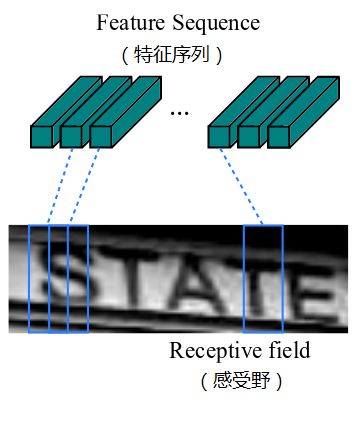
③ 提取序列特征
提取的特征序列中的向量是在特征图上从左到右按照顺序生成的,用于作为循环层的输入,每个特征向量表示了图像上一定宽度上的特征,默认的宽度是1,也就是单个像素。由于CRNN已将输入图像缩放到同样高度了,因此只需按照一定的宽度提取特征即可。如下图所示:
(2)循环层
循环层由一个双向LSTM循环神经网络构成,预测特征序列中的每一个特征向量的标签分布。
由于LSTM需要有个时间维度,在本模型中把序列的 width 当作LSTM 的时间 time steps。
其中,“Map-to-Sequence”自定义网络层主要是做循环层误差反馈,与特征序列的转换,作为卷积层和循环层之间连接的桥梁,从而将误差从循环层反馈到卷积层。
(3)转录层
转录层是将LSTM网络预测的特征序列的结果进行整合,转换为最终输出的结果。
在CRNN模型中双向LSTM网络层的最后连接上一个CTC模型,从而做到了端对端的识别。所谓CTC模型(Connectionist Temporal Classification,联接时间分类),主要用于解决输入数据与给定标签的对齐问题,可用于执行端到端的训练,输出不定长的序列结果。
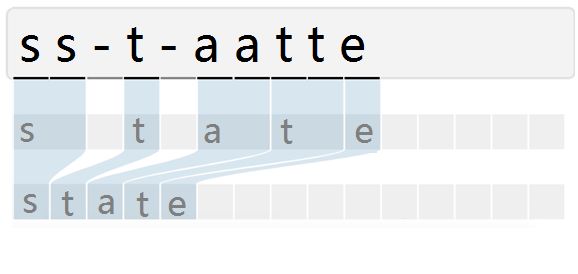
由于输入的自然场景的文字图像,由于字符间隔、图像变形等问题,导致同个文字有不同的表现形式,但实际上都是同一个词,如下图:

而引入CTC就是主要解决这个问题,通过CTC模型训练后,对结果中去掉间隔字符、去掉重复字符(如果同个字符连续出现,则表示只有1个字符,如果中间有间隔字符,则表示该字符出现多次),如下图所示:
以上就是文本识别模型CRNN的介绍,该模型既可用于识别英文、数字,也可用于识别中文。一般是跟CTPN结合一起使用,使用CTPN进行文字的检测,使用CRNN进行文字的识别。
本人使用CTPN+CRNN对中文识别出来的效果如下(隐去私密信息):
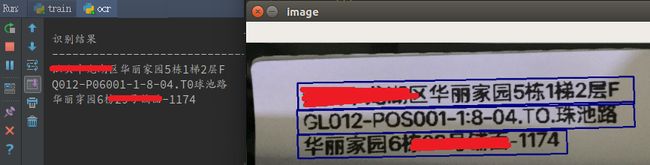
墙裂建议
2015年,Baoguang Shi 等人发表了关于CRNN的经典论文《 An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition 》,在论文中详细介绍了CRNN的思想和技术原理,建议阅读该论文以进一步了解该模型。
关注本人公众号“大数据与人工智能Lab”(BigdataAILab),然后回复“论文”关键字可在线阅读经典论文的内容。

推荐相关阅读
- 【AI实战】快速掌握TensorFlow(一):基本操作
- 【AI实战】快速掌握TensorFlow(二):计算图、会话
- 【AI实战】快速掌握TensorFlow(三):激励函数
- 【AI实战】快速掌握TensorFlow(四):损失函数
- 【AI实战】搭建基础环境
- 【AI实战】训练第一个模型
- 【AI实战】编写人脸识别程序
- 【AI实战】动手训练目标检测模型(SSD篇)
- 【AI实战】动手训练目标检测模型(YOLO篇)
- 【精华整理】CNN进化史
- 大话文本识别经典模型(CRNN)
- 大话文本检测经典模型(CTPN)
- 大话卷积神经网络(CNN)
- 大话循环神经网络(RNN)
- 大话深度残差网络(DRN)
- 大话深度信念网络(DBN)
- 大话CNN经典模型:LeNet
- 大话CNN经典模型:AlexNet
- 大话CNN经典模型:VGGNet
- 大话CNN经典模型:GoogLeNet
- 大话目标检测经典模型:RCNN、Fast RCNN、Faster RCNN
- 大话目标检测经典模型:Mask R-CNN
- 27种深度学习经典模型
- 浅说“迁移学习”
- 什么是“强化学习”
- AlphaGo算法原理浅析
- 大数据究竟有多少个V
- Apache Hadoop 2.8 完全分布式集群搭建超详细教程
- Apache Hive 2.1.1 安装配置超详细教程
- Apache HBase 1.2.6 完全分布式集群搭建超详细教程
- 离线安装Cloudera Manager 5和CDH5(最新版5.13.0)超详细教程