环境:虚拟机下的ubuntu,所以就别想着什么CUDA了,折腾了半天才安装了了个opencv。
哦,不对,还是需要先说说怎么安装吧,虽然很简单。
YOLO: 是实现实时物体检测的系统,Darknet是基于YOLO的框架
darknet非常容易安装,它只有2个可选择的依赖:
Opencv: 能支持更多格式的图像,并且得到实时的显示,我安装了这个,但是自己电脑原因效果不好。
GPU: 利用GPU计算,能大大提升YOLO的识别帧率,画面更加流畅
安装这两个依赖都必须要
先安装基础版yolo
---安装基础版yolo---
首先将darknet从
github
上clone下来:
$ git clone https://github.com/pjreddie/darknet.git
$ cd darknet
$ make
如果正确执行的话,会看到以下内容:

运行以下命令:
$ ./darknet
看到以下效果,即为安装成功:

---基础版yolo测试---
完成上面的操作后,我们可以看到 cfg/目录下已经有了YOLO的配置文件了.
现在为了测试我们的yolo,需要下载官方训练完毕的权重(237MB),或者运行以下命令: 权重可以自己随便找
我们没有使用OpenCV编译Darknet,因此无法直接显示检测结果。相反,它将它们保存在/darknet/predictions.png中。您可以打开它来查看检测到的对象。由于我们在CPU上使用Darknet,每个图像需要大约6-12秒。如果我们使用GPU版本,速度会更快.
在data/目录下还有其他的测试图片,可以尝试一下
./darknet detect cfg/yolo.cfg yolo.weights data/dog.jpg

在我尝试利用摄像头进行实时检测的时候,发现识别的速度特别慢,因为此时的程序还是使用的CPU,一帧图像都得要处理6-7秒.所以我们需要给用CUDA+Opencv编译yolo,使之能通过GPU显卡运算,这样速度会提高很多很多.
到此,你就会明白了接下来为啥会安装opencv库了,不再废话了,cuda的安装请参考原文作者的帖子:
---安装opencv---
安装opencv过程也很简单,但是容易出错,因为安装完成后需要就行一些配置和测试
这是一篇不错的博客,照着敲下来基本就ok了。
https://blog.csdn.net/cocoaqin/article/details/78163171
另外你可能跑到 exemple 文件夹下的 python库中测试,但是这个时候你会发现 what?
不能导入 cv2,也就是在python中不能用,这个时候很简单,
pip install opencv-python
就可以用了。
哦,对了还有你想测试下您的摄像头能不能用,比如你可能测试了下边的方法。

然后出乎你意料的是,黑屏,黑屏啊,虽然有个 hello opencv!但显然笔记本的摄像头并没有亮啊。
但是你还是不死心的,那就去python中写个简单的脚本来打开摄像头测试
# -*- coding: utf-8 -*
import cv2
import numpy as np
import pickle
import matplotlib.pyplot as plt
cap = cv2.VideoCapture(0)
index = 0
while True:
ret,frame = cap.read()
# Our operations on the frame come here
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
# Display the resulting frame
cv2.imshow('frame',gray)
if cv2.waitKey(1) & 0xFF == ord('p'):
cv2.imwrite("kk.jpg",frame)
index = index + 1
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# When everything done, release the capture
cap.release()
cv2.destroyAllWindows()
写完之后你赶紧python下,,可是

于是,有点崩溃的感觉!!!!!!!!!!
百度,可是这个问题的人好少。寻思着自己的机子是在虚拟机下安装的,难不成是虚拟机没办法打开摄像头。
果然,发现了真想,于是设置代开 camera,网上有人是
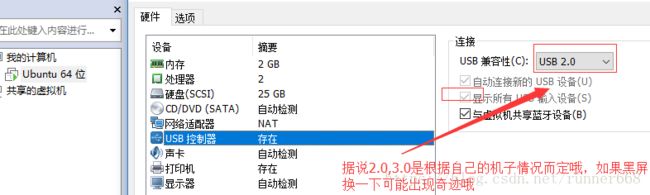
找了半天没找到camera,在ubuntu右下角的usb中,找知道了这个,打开了。
在终端输入 cheese,打开摄像头试试,奇迹发生了。但是画面质量很差,以至于之后在yolo中调用摄像头的出现花屏,花屏,我找了半天暂时没找到解决办法,哪位大佬知道的话求指教?????????!
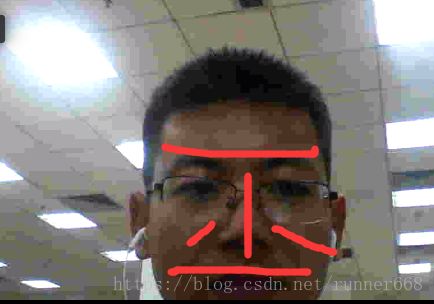
测试模型的视频识别:实时抓取人脸图像进行检测识别,执行如下命令,可是我的到这里花屏了,这不是关键时候掉链子
嘛,只能怪自己的的电脑台渣吧,我还作,还装个虚拟机。
./darknet detector demo cfg/coco.data cfg/yolov3.cfg yolov3.weights
我想着要想在摄像头正确的显示,需要改动V4L2底层开发库。但是目前我还没有想好怎么设置。
------voc数据集测试------
Download the training, validation, test data and VOCdevkit
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtrainval_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCtest_06-Nov-2007.tar
wget http://host.robots.ox.ac.uk/pascal/VOC/voc2007/VOCdevkit_08-Jun-2007.tar
Extract all of these tars into one directory named VOCdevkit
tar xvf VOCtrainval_06-Nov-2007.tar
tar xvf VOCtest_06-Nov-2007.tar
tar xvf VOCdevkit_08-Jun-2007.tar
一.制作数据集
运行以下代码,将.xml 文件转换成.txt 文件,以备YOLO训练时数据解析:
1.数据集准备
(1)将数据集VOCdevkit2007拷贝到darknet\scripts下 (2)VOCdevkit2007修改名称为VOCdevkit
2.修改darknet\scripts\voc_label.py //自带的脚本,但是可能有点小偏差,我使用了下面的。
sets=[('2007', 'train'), ('2007', 'val'), ('2007', 'test')] //这里自行添加
classes = ["comp"]
//注释掉
#os.system("cat 2007_train.txt 2007_val.txt 2012_train.txt 2012_val.txt > train.txt")
#os.system("cat 2007_train.txt 2007_val.txt 2007_test.txt 2012_train.txt 2012_val.txt > train.all.txt")
3.终端进入darknet\scripts,执行:
python voc_label.py
此后可以看到:
VOCdevkit\VOC2007里多了一个labels文件夹(如下)
darknet\scripts下多了2007_train.txt、2007_val.txt和2007_test.txt三个文件
///////////////////////////////////////////
voc_label.py
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets=[('2007', 'train'), ('2007', 'val')]
classes = ["aeroplane", "bicycle", "bird", "boat", "bottle", "bus", "car", "cat", "chair", "cow", "diningtable", "dog", "horse", "motorbike", "person", "pottedplant", "sheep", "sofa", "train", "tvmonitor"]
def convert(size, box):
dw = 1./size[0]
dh = 1./size[1]
x = (box[0] + box[1])/2.0
y = (box[2] + box[3])/2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
return (x,y,w,h)
def convert_annotation(year, image_id):
in_file = open('VOCdevkit/VOC%s/Annotations/%s.xml'%(year, image_id))
out_file = open('VOCdevkit/VOC%s/labels/%s.txt'%(year, image_id), 'w')
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
for year, image_set in sets:
if not os.path.exists('VOCdevkit/VOC%s/labels/'%(year)):
os.makedirs('VOCdevkit/VOC%s/labels/'%(year))
image_ids = open('VOCdevkit/VOC%s/ImageSets/Main/%s.txt'%(year, image_set)).read().strip().split()
list_file = open('%s_%s.txt'%(year, image_set), 'w')
for image_id in image_ids:
list_file.write('%s/VOCdevkit/VOC%s/JPEGImages/%s.jpg\n'%(wd, year, image_id))
convert_annotation(year, image_id)
list_file.close()
二.修改配置文件
(1)修改data/my_voc.names文件:comp
(2)修改cfg/voc.data文件。
classes= 1
train = /home/ming/darknet/darknet/scripts/2007_train.txt //训练集
valid = /home/ming/darknet/darknet/scripts/2007_train.txt //测试机,前边没制作,就和训练集一样了哈。。
names = data/my_voc.names
backup = backup //在darknet新建一个backup目录,存储.weight
(3) 修改×××.cfg(以yolo-voc.cfg为例),修改2个参数(filters,class),见下:yolo2为例
① 【region】层中 classes 改成1。
② 【region】层上方第一个【convolution】层,其中的filters值要进行
修改,改成(classes+ coords+ 1)* (NUM) ,我的情况中:(1+4+1)* 5=30
③ learning_rate:学习率
④ max_batches:最大迭代次数


三.训练
用的是yolo2网络,yolo3和yolo2网络结构不一样,暂时没有尝试。
./darknet detector train cfg/voc.data cfg/yolov2-voc.cfg darknet19_448.conv.23

可以看到提示,有的照片没有打开,我去2007_train.txt中看了一下,有路径但是没有对应的照片,说明我资源下载的不全!
------voc输出参数解读------

以上截图显示了所有训练图片的一个批次(batch),批次大小的划分根据我们在 .cfg 文件中设置的subdivisions参数。在我使用的 .cfg 文件中 batch = 64 ,subdivision = 8,所以在训练输出中,训练迭代包含了8组,每组又包含了8张图片,跟设定的batch和subdivision的值一致。
(注: 也就是说每轮迭代会从所有训练集里随机抽取 batch = 64 个样本参与训练,所有这些 batch 个样本又被均分为 subdivision = 8 次送入网络参与训练,以减轻内存占用的压力)
批输出
针对上图中最后一行中的信息,我们来一步一步的分析。如下的输出是由 detector.c 生成的,具体代码见:点击打开链接
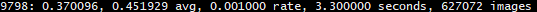
- 0.451929 avg: 是平均Loss,这个数值应该越低越好,一般来说,一旦这个数值低于0.060730 avg就可以终止训练了。
- 0.001000 rate: 代表当前的学习率,是在.cfg文件中定义的。
- 3.300000 seconds: 表示当前批次训练花费的总时间。
- 627072 images: 这一行最后的这个数值是9798*64的大小,表示到目前为止,参与训练的图片的总量。
分块输出
在分析分块输出之前,我们得了解一下IOU(Intersection over Union,也被称为交并集之比:点击打开链接),这样就能理解为什么分块输出中的参数是一些重要且必须要输出的参数了。

可以看到,IOU(交集比并集)是一个衡量我们的模型检测特定的目标好坏的重要指标。100%表示我们拥有了一个完美的检测,即我们的矩形框跟目标完美重合。很明显,我们需要优化这个参数。
回归正题,我们来分析一下这些用来描述训练图集中的一个批次的训练结果的输出。那些想自己深入源代码验证我所说的内容的同学注意了,这段代码:点击打开链接 执行了以下的输出:

- Region Avg IOU: 0.326577: 表示在当前subdivision内的图片的平均IOU,代表预测的矩形框和真实目标的交集与并集之比,这里是32.66%,这个模型需要进一步的训练。
- Class: 0.742537: 标注物体分类的正确率,期望该值趋近于1。
- No Obj: 0.000793: 期望该值越来越小,但不为零。
- Avg Recall: 0.12500: 是在recall/count中定义的,是当前模型在所有subdivision图片中检测出的正样本与实际的正样本的比值。在本例中,只有八分之一的正样本被正确的检测到。
- count: 8:count后的值是所有的当前subdivision图片(本例中一共8张)中包含正样本的图片的数量。在输出log中的其他行中,可以看到其他subdivision也有的只含有6或7个正样本,说明在subdivision中含有不含检测对象的图片。
总结
在这篇短文里,我们回顾了一下YOLOv2在终端输出的不同的参数的含义,这些参数也在告诉我们YOLOv2的训练过程是怎样进行的。这个能在一定程度上解答大家关于YOLOv2的训练输出的大部分问题,但请记住,对YOLOv2的探索决不应该到此为止。
跟以往一样,欢迎大家在评论区留言,进一步讨论关于YOLOv2的相关问题,我也会不断优化改进这篇文章,所以,别忘了留言评论哦!
原英文地址: https://timebutt.github.io/static/understanding-yolov2-training-output/