JVM OOM & JAVA finalizer 引发的OOM & Thread.stop
背景
本文绝对干货.
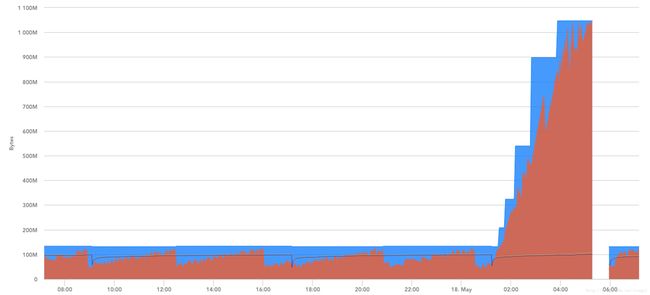
某天发现客户环境一直有OOM发生,而且是阶梯状的内存增长. 比较郁闷.
Abstract
这个文章里面会描述以下几件事情:
1. 在java中有OOM应该怎么分析?
2. JAVA finalizer为什么会引发OOM?
3. 为什么不能使用Thread.stop
Java中发生OOM应该怎么分析
大多数时候Java都做得足够好. 但是没办法还是有可能会有OutOfMemoryError(OOM) 发生. 那么我们应该怎么分析一个OOM错误呢?
拿到内存转储
方式1:自动转储
当OOM发生时, Java可以自动尝试(best effort)生成一个堆转储.只需要你在启动参数中加上如下参数:
-XX:+HeapDumpOnOutOfMemoryError这种方式生成的文件会在java的工作目录里面, 名字叫 java_pidXXX.hprof
方式2:手动转储
有时候你已经可以发现某个Java进程占用了很多内存了. 是时候手动导出一个堆内存了.
使用jmap. jmap是一个jdk自带的工具, 在jdk/bin下面,
jmap -dump:format=b,file=heap.bin
jmap -F -dump:format=b,file=heap.bin 强制导出 有一点很重要: 出于兼容性考虑,一定使用和你运行JRE**运行版本相同**的jmap工具.
运用工具分析
常见的内存分析工具是Eclipse的Memory analyzer 和 Jvisualvm.
Eclispe memory analyzer/ MAT
这个是Eclipse推出的一个可视化内存分析工具.

里面的很多组件都很好用:
1. histogram 列出每个class有多少instance
2. Leak suspects 列出了工具觉得可能有内存泄漏的地方.
比如Leak suspects页面的下图:

从上图可以看出, Finalizer线程占用860M的内存, 约93%的空间.
如果这些标准的页面不能让你得到你关注的东西, 可以采用OQL console. 就是上图左上角第4个图标.
采用OQL 我们可以做很多的事情, 比如列出Finalizer对象引用的哪些对象都是啥:
列出所有URLConnection的url:
SELECT f.referent.url.toString() FROM java.lang.ref.Finalizer f WHERE f.referent.toString().startsWith("sun.net.www.protocol.https.HttpsURLConnectionImpl")
mat的oql参考地址:http://help.eclipse.org/neon/index.jsp?topic=/org.eclipse.mat.ui.help/welcome.html
更强大的Jvisualvm
jdk自带的jvisualvm也可以分析堆转储.
它提供了比MAT更加强大的分析功能.
MAT是无法做到类似于sql groupby filter, top 之类的操作的. 或者更加复杂的查询. 但是在jvisualvm我们可以实现很复杂的查询:
比如下面的query可以实现: 我想查看Finalizer所引用的对象中, 前10个instance最多的class都是啥:
var counts = {};
var alreadyReturned = {};
top(
filter(
sort(
map(heap.objects("java.lang.ref.Finalizer"),
function (fobject) {
var className = classof(fobject.referent)
if (!counts[className]) {
counts[className] = 1;
} else {
counts[className] = counts[className] + 1;
}
return {string: className, count: counts[className]};
}),
'rhs.count-lhs.count'),
function (countObject) {
if (!alreadyReturned[countObject.string]) {
alreadyReturned[countObject.string] = true;
return true;
} else {
return false;
}
}),
"rhs.count > lhs.count", 10);大致解释下:
heap.objects(“java.lang.ref.Finalizer”)指定了堆上这个类的所有instance;
在map中, 每个record被映射为具有2个属性的对象:{string:className, count[className]}, 属性string, 代表class名字, 属性count代表它的instance个数;
在排序函数中rhs代表右边的元素, lhs代表左边的元素.
示例输出(不是前面的heap,但是不影响观赏)

jvisualvm的oql参考地址:https://visualvm.github.io/documentation.html (在里面的OQL部分)
Java Finalizer为啥会引发OOM
从前面的heap已经看到了, 有很多的instance都被Java中的Finalizer线程引用了.
什么是Finalizer
教科书都告诉我们最好不要覆盖finalize方法. 所有覆盖了finalize方法的对象都会在经过GC后被放入一个ReferenceQueue中, 然后后台有一个高优先级的线程来执行它的finalize方法.
这里注意以下几点:
1. 对象是在已经被GC识别为是垃圾后才丢到Queue中的,而不是丢到queue中,finalize完了才认为是垃圾的. 在queue中依然占用内存. IMPORTANT
2. 后台的Finalizer thread是一个高优先级的线程,而不是一个低优先级的线程.(参考源码.)
3. finalizer thread捕获了所有在finalize中可能抛出的Throwable.
4. 一个对象的finalize方法最多会执行一次.
5. 你也可以通过finalize来重新是的对象不能被回收. 参考<深入理解JAVA虚拟机 第二版>的3.2.4 生存还是死亡章节.
附, 关于finalizer线程优先级的源码:

finalizer会导致OOM吗
那么接着分析, 既然finalize方法捕获了所有的throwable, 那么只有可能是finalize方法慢了, 才会导致finalize queue一直增大, 占用内存, 最终OOM.
JMX里面实际有个选项可以获得当前的queue里面到底有多少个对象:
import java.lang.management.ManagementFactory;
ManagementFactory.getMemoryMXBean().getObjectPendingFinalizationCount();这个是我们的监控图: (等待执行finalize方法的对象个数)

那么我们有2个方向:
1. 某些对象覆盖了finalize方法, 而且finalize方法实现的效率不高, 导致越来越多.
2. 某些对象实现了类似于block或者sleep的逻辑,阻塞了整个线程.
调查了1, 感觉不太对, 发现都是jdk自己实现的一些底层链接, 应该不会很慢才对, 我们也尝试了缓存URLConnection对象, 有很大程度缓解, 但是最终还是有OOM发生了.
那么只能是2了. 话不多说赶紧执行下jstack看下这个线程在干啥:
"Finalizer" #3 daemon prio=8 os_prio=1 tid=0x00000000510ae000 nid=0x1e78 in Object.wait() [0x0000000000b2e000]
java.lang.Thread.State: WAITING (on object monitor)
at java.lang.Object.wait(Native Method)
at java.lang.Object.wait(Object.java:502)
at sun.security.ssl.SSLSocketImpl.closeInternal(SSLSocketImpl.java:1697)
- locked <0x00000000d2449060> (a sun.security.ssl.SSLSocketImpl)
at sun.security.ssl.SSLSocketImpl.close(SSLSocketImpl.java:1602)
at com.microsoft.sqlserver.jdbc.TDSChannel.disableSSL(Unknown Source)
at com.microsoft.sqlserver.jdbc.TDSChannel.close(Unknown Source)
at com.microsoft.sqlserver.jdbc.SQLServerConnection.close(Unknown Source)
at com.microsoft.sqlserver.jdbc.SQLServerConnection.terminate(Unknown Source)
at com.microsoft.sqlserver.jdbc.SQLServerConnection.throwInvalidTDS(Unknown Source)
at com.microsoft.sqlserver.jdbc.TDSReader.throwInvalidTDS(Unknown Source)
at com.microsoft.sqlserver.jdbc.TDSReader.readPacket(Unknown Source)
at com.microsoft.sqlserver.jdbc.TDSChannel$SSLHandshakeInputStream.ensureSSLPayload(Unknown Source)
at com.microsoft.sqlserver.jdbc.TDSChannel$SSLHandshakeInputStream.read(Unknown Source)
at com.microsoft.sqlserver.jdbc.TDSChannel$ProxyInputStream.read(Unknown Source)
at sun.security.ssl.InputRecord.readFully(InputRecord.java:465)
at sun.security.ssl.InputRecord.read(InputRecord.java:503)
at sun.security.ssl.SSLSocketImpl.readRecord(SSLSocketImpl.java:973)
- locked <0x00000000d244d4d8> (a java.lang.Object)
at sun.security.ssl.SSLSocketImpl.waitForClose(SSLSocketImpl.java:1769)
at sun.security.ssl.SSLSocketImpl.closeSocket(SSLSocketImpl.java:1579)
at sun.security.ssl.SSLSocketImpl.closeInternal(SSLSocketImpl.java:1713)
at sun.security.ssl.SSLSocketImpl.close(SSLSocketImpl.java:1602)
at sun.security.ssl.BaseSSLSocketImpl.finalize(BaseSSLSocketImpl.java:269)
at java.lang.System$2.invokeFinalize(System.java:1270)
at java.lang.ref.Finalizer.runFinalizer(Finalizer.java:98)
at java.lang.ref.Finalizer.access$100(Finalizer.java:34)
at java.lang.ref.Finalizer$FinalizerThread.run(Finalizer.java:210)
很明显, 对比几次的线程dump我们发现都是这个对象在执行wait方法. 那么它是不是在等一个永远不会来的通知,然后导致thread block了呢, 这样就可以解释queue为啥越来越大了, 因为后面根本没法执行了嘛.
Thread.stop
接着上面的说, 现在我们知道了是sun.security.ssl.SSLSocketImpl.closeInternal(SSLSocketImpl.java:1697) 这里面在等锁, 但是一直没拿到.!!
那就很奇怪了, 官网的jdk实现的应该没有这种bug才对, 这个不会是jdk的bug吧?
然后我们对比了下自己的业务日志, 发现, 对应的时间点有个很奇怪的groovy脚本报了超时被强制结束了. 从那一开始, 等待执行finalize方法的queue就增大了. 然后检查了代码:
// 为了能够确保客户的groovy脚本可以被结束掉, 我们每提交一个任务都触发了一个超时的Timer来强制结束
// 大致就是:
_targrtThread.stop();就是这句stop导致对象锁被不正确是释放掉了.
查看官网对thread.stop 方法的说明: https://docs.oracle.com/javase/7/docs/technotes/guides/concurrency/threadPrimitiveDeprecation.html
Because it is inherently unsafe. Stopping a thread causes it to unlock all the monitors that it has locked. (The monitors are unlocked as the ThreadDeath exception propagates up the stack.) If any of the objects previously protected by these monitors were in an inconsistent state, other threads may now view these objects in an inconsistent state. Such objects are said to be damaged. When threads operate on damaged objects, arbitrary behavior can result. This behavior may be subtle and difficult to detect, or it may be pronounced. Unlike other unchecked exceptions, ThreadDeath kills threads silently; thus, the user has no warning that his program may be corrupted. The corruption can manifest itself at any time after the actual damage occurs, even hours or days in the future.
可以看到, 简单来说, 直接stop会导致线程释放所有的monitor, 并且会导致被monitor保护的变量处于不一致的状态. finally方法也没办法正确执行.
所以说, 这个问题是stop导致的. 后面改为interrupt方法就没有再出问题了.
总结
1. 不要用Thread.stop.
2. 不要覆盖实现finalize方法.
3. OQL对内存分析很有用, 可以多学习.