序列标注 | (5) 命名实体识别技术综述
本文是对 《命名实体识别技术综述》的摘录和笔记。
论文链接
文章目录
- 1. 简介
- 2. 研究难点
- 3. 主要方法
- 4. 研究热点
- 5. 数据集和评价指标
- 6. 参考文献
1. 简介
命名实体识别(NER)的目的是识别文本中的命名实体(边界)并将其归纳到相应的实体类型中。一般的实体类型包括人名、地名、组织机构名、日期等。
NER的主要难点在于领域命名实体识别的局限性(如军事领域命名实体识别等)、命名实体表述的多样性和歧义性、命名实体的复杂性和开放性。
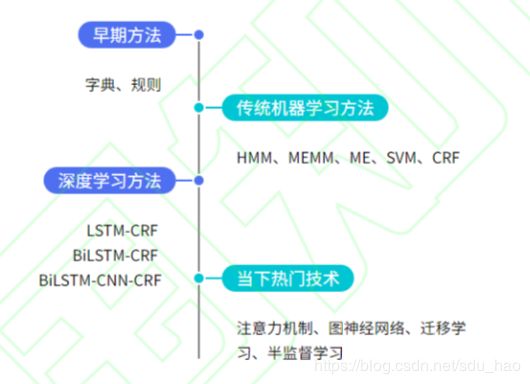
NER的研究进程从最初的规则字典方法到统计机器学习方法,再到目前的深度学习方法,性能不断提高。
目前NER的研究热点主要包括:匮乏资源下的命名实体识、细粒度命名实体识别、嵌套命名实体识别以及实体链接。
NER的意义:建立一个可以支撑自然语言理解和处理的大规模知识库对于实现人工智能的目标非常重要。NER可以检测出文本中的新实体和相应类型并加入到现有知识库中,为推动人工智能发展提供可靠的知识和技术基础。NER在多种NLP任务中都有广泛的应用,例如知识图谱构建、机器翻译、知识库构建、自动问答、网络搜索等。
2. 研究难点
-
领域命名实体识别局限性
NER在一些特定的领域和有限的实体类型中取得了较好的成绩,如新闻语料中的人名、地名、机构组织名的识别。但不能很好的迁移到其他领域,如军事、医疗、小语种语言、生物等。一方面是不同领域的数据都有该领域独特的特征,如医疗中的命名实体包括疾病、症状、药品等,新闻领域的模型肯定不适合;另一方面,一些领域缺乏标注数据集,模型难以训练。
半监督学习、远监督学习、无监督学习方法实现数据自动构建和补足以及迁移学习技术的应用可作为该问题的核心研究方向。 -
命名实体表述多样性和歧义性
不同文化、领域、背景下,命名实体的外延有差异,存在命名实体表述多样、指代不明确的现象。需要充分理解上下文语义来挖掘实体语义进行识别。可以通过实体链接、融合对齐等方法,实现实体不同表示的对齐、消除歧义。 -
命名实体的复杂性和开放性
传统NER主关注一小部分粗粒度的实体类型,如人名、地名、组织机构名等,实际场景中实体类型复杂多样,需要识别出更细粒度的实体类型,如人名可以细分为运动员、科学家等,地名可细分为国家、城市等。开放性指的是命名实体的类型和内容并不是永久不变的,随着时间变化可能会发生各种演变。
3. 主要方法
-
基于规则和字典和方法
语言学家通过人工方式,依据数据集特征构建特定规则模版或者特殊词典,使用匹配的方式对文本进行处理实现NER。可扩展性比较差,不好在其他实体类型或数据集扩展。 -
基于传统机器学习的方法
基于机器学习的方法中,NER被看作序列标注问题。也就是对序列中的每个元素(字/词)基于标签集合进行多分类。与朴素的分类问题相比,序列中每个元素当前的预测标签不仅与当前输入特征有关,还与之前预测标签有关,即预测标签序列之间有依赖关系。如在NER中,预测标签之间会有一些限制,如I-LOC不能出现在B-LOC之前、I标签不能出现在序列首部等。
主要方法包括:HMM、最大熵、最大熵HMM、SVM、CRF等。其中CRF被看作传统机器学习方法中做NER的主流模型,它对一个位置/元素进行标注过程中可以利用内部及上下文特征信息。 -
基于深度学习的方法
主流模型包括BiLSTM-CRF、BiLSTM-CNNs-CRF、Bert/AlBert+(BiLSTM)+CRF等。其中的神经网络结构可以有效的建模上下文信息,CRF可以优化输出标签序列,添加一些约束。
最近,在基于神经网络的结构上加入注意力机制、GNN、迁移学习、远监督学习等热门技术是目前主流的研究方向。
4. 研究热点
- 匮乏/低资源命名实体识别
NER一般需要大规模标注数据集,如每个输入序列/句子,要有一个对应的标注序列。当某些领域的标注数据很少时,如军事、医疗等,传统监督学习方法性能会大大降低。
一些学者采用迁移学习的方法,桥接富 足资源和匮乏资源,命名实体识别的迁移学习方法可以分为两种:基于并行语料库的迁移学习和基于共享 表示的迁移学习。利用并行语料库在高资源和低资源语言之间映射信息,Chen和Feng等[1-2]提出同时识别 和链接双语命名实体。Ni和Mayhew等[3]创建了一个跨语言的命名实体识别系统,该系统通过将带注释的富 足资源数据转换到匮乏资源上,很好地解决了匮乏资源问题。Zhou等[4]采用双对抗网络探索高资源和低资源之间有效的特征融合,将对抗判别器和对抗训练集成在一个统一的框架中进行,实现了端到端的训练。
还有学者采用正样本-未标注样本学习方法(Positive-Unlabeled, PU),仅使用未标注数据和部分不完善的 命名实体字典来实现命名实体识别任务。Yang等学者[5]采用AdaSampling方法,它最初将所有未标记的实例 视为负实例,不断地迭代训练模型,最终将所有未标注的实例划分到相应的正负实例集中。Peng等学者[6] 实现了PU学习方法在命名实体识别中的应用,仅使用未标记的数据集和不完备的命名实体字典来执行命名 实体识别任务,该方法无偏且一致地估算任务损失,并大大减少对字典大小的要求。
针对资源匮乏领域标注数据的缺乏问题,基于迁移学习、对抗学习、远监督学习等方法被充分利用,解决资源匮乏领域的命名实体识别难题,降低人工标注工作量,也是最近研究的重点。
- 细粒度命名实体识别
为了智能地理解文本并提取大量信息,更精确地确定非结构化文本中提到的实体类型很有意义。通常这些实体类型在知识库的类型层次结构中可以形成类型路径,例如,牛顿可以按照如下类型的路径归类: 物理学家/科学家/人。知识库中的类型通常为层次结构的组织形式,即类型层次。
大多数命名实体识别研究都集中在有限的实体类型上,Ling和Daniel[7]定义了一个细粒度的112个标签集,如下图所示,将标签问题表述为多类型多标签分类。

学者们在该领域已经进行了许多研究,通常学习每个实体的分布式表示,并应用多标签分类模型进行类型推断。Neelakantan和Chang [8]利用各种信息构造实体的特征表示,如实体的文字描述、属性和类型, 之后,学习预测函数来推断实体是否为某类型的实例。Yaghoobzadeh等[9]重点关注实体的名称和文本中的实体指代项,并为实体和类型对设计了两个评分模型。这些工作淡化了实体之间的内部关系,并单独为每个实体分配类型。Jin等[10]以实体之间的内部关系为结构信息,构造实体图,进一步提出了一种网络嵌入框架学习实体之间的相关性。最近的研究表明以卷积方式同时包含节点特征和图结构信息,将实体特征丰富到图结构将获益颇多[11-12]。此外,还有学者考虑到由于大多数知识库都不完整,缺乏实体类型信息,例如 在DBpedia数据库中36.53%的实体没有类型信息。因此对于每个未标记的实体,Jin等[13]充分利用其文本描 述、类型和属性来预测缺失的类型,将推断实体的细粒度类型问题转化成基于图的半监督分类问题,提出了使用分层多图卷积网络构造3种连通性矩阵,以捕获实体之间不同类型的语义相关性。
此外,实现知识库中命名实体的细粒度划分也是完善知识库的重要任务之一。细粒度命名实体识别现 有方法大多是通过利用实体的固有特征(文本描述、属性和类型)或在文本中实体指代项来进行类型推断, 最近有学者研究将知识库中的实体转换为实体图,并应用到基于图神经网络的算法模型中。
- 嵌套命名实体识别
通常要处理的命名实体是非嵌套实体,但是在实际应用中,嵌套实体非常多。大多数命名实体识别会 忽略嵌套实体,无法在深层次文本理解中捕获更细粒度的语义信息。如下图所示,在 “3 月 3 日,中国驻爱 尔兰使馆提醒旅爱中国公民重视防控,稳妥合理加强防范。” 句子中提到的中国驻爱尔兰使馆是一个嵌套 实体,中国和爱尔兰均为地名,而中国驻爱尔兰使馆为组织机构名。普通的命名实体识别任务只会识别出 其中的地名“中国”和“爱尔兰”,而忽略了整体的组织机构名。
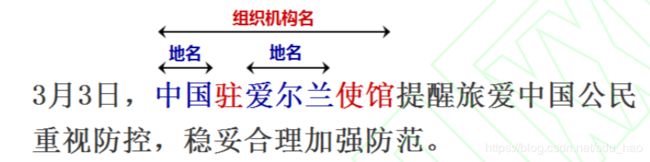
学者们提出了多种用于嵌套命名实体识别的方法。Finkel和Manning[14]基于CRF构建解析器,将每个命名实体作为解析树中的组成部分。Ju等[15]动态堆叠多个扁平命名实体识别层,并基于内部命名实体识别提取外部实体。如果较短的实体被错误地识别,这类方法可能会遭受错误传播问题的困扰。嵌套命名实体识别的另一系列方法是基于超图的方法。Lu和Roth[16]首次引入了超图,允许将边缘连接到不同类型的节点以表示嵌套实体。Muis和Lu[17]使用多图表示法,并引入分隔符的概念用于嵌套实体检测。但是这样需要依靠手工提取的特征来识别嵌套实体,同时遭受结构歧义问题的困扰。Wang和Lu[18]提出了一种使用神经网络获取分布式特征表示的神经分段超图模型。Katiyar和Cardie [19]提出了一种基于超图的计算公式,并以贪婪学习的方式使用LSTM神经网络学习嵌套结构。这些方法都存在超图的虚假结构问题,因为它们枚举了代表实体的节点、类型和边界的组合。Xia等[20]提出了MGNER架构,不仅可以识别句子中非重叠的命名实体,也可以识别嵌套实体,此外不同于传统的序列标注任务,它将命名实体识别任务分成两部分开展,首先识别实体,然后进行实体分类。
嵌套实体识别充分利用内部和外部实体的嵌套信息,从底层文本中捕获更细粒度的语义,实现更深层次的文本理解,研究意义重大。
- 命名实体链接
命名实体链接主要目标是进行实体消歧,从实体指代项(实体mention)对应的多个候选实体中选择意思最相近的一个实体。这些候选实体可能选自通用知识库,例如维基百科、百度百科[21],也可能来自领域知识库,例如军事知识库、装备知识库。下图给出了一个实体链接的示例。短文本“美海军陆战队F/A-18C战斗机安装了生产型AN/APG-83雷达”,其中实体指代项是“生产型AN/APG-83雷达”,该实体指代项在知识库中可能存在多种表示和含义,而在此处短文本,其正确的含义为“AN/APG-83可扩展敏捷波束雷达”。

实体链接的关键在于获取语句中更多的语义,通常使用两种方法:一种是通过外部语料库获取更多的辅助信息,另一种是对本地信息的深入了解以获取更多与实体指代项相关的信息[22]。Tan 等[23]提出了一种候选实体选择方法,使用整个包含实体指代项的句子而不是单独的实体指代项来搜索知识库,以获得候选实体集,通过句子检索可以获取更多的语义信息,并获得更准确的结果。Lin 等[24]寻找更多线索来选择候选实体,这些线索被视为种子实体指代项,用作实体指代项与候选实体的桥梁。Dai 等[25]使用社交平台 Yelp 的特征信息,包括用户名、用户评论和网站评论,丰富了实体指代项相关的辅助信息,实现了实体指代项的歧义消除。因此,与实体指代项相关的辅助信息将通过实体指代项和候选实体的链接实现更精确的歧义消除。
另一些学者使用深度学习研究文本语义。Francis-Landau等[26]使用卷积神经网络学习文本的表示形式, 然后获得候选实体向量和文本向量的余弦相似度得分。Ganea和Hofmann[27]专注于文档级别的歧义消除,使用神经网络和注意力机制来深度表示实体指代项和候选实体之间的关系。Mueller和Durrett[28]将句子左右分开,然后分别使用门控循环单元和注意力机制,获得关于实体指代项和候选实体的分数。Ouyang等[29]提出一种基于深度序列匹配网络的实体链接算法, 综合考虑实体之间的内容相似度和结构相似性,从而帮助机器理解底层数据。目前,在实体链接中使用深度学习方法是一个热门的研究课题。
5. 数据集和评价指标
- 数据集
1)CoNLL 2003数据集[30],标注了4种实体类型: PER,LOC,ORG MISC。
- CoNLL 2002数据集[31], 标注了4种实体类型: PER,LOC,ORG MISC。
- ACE 2004 多语种训练语料库[32], 包含用于 2004 年自动内容提取(ACE)技术评估的全套英语、阿拉伯语和中文培训数据。 语言集由为实体和关系标注的各种类型的数据组成。
- ACE 2005 多语种训练语料库[32], 包含完整的英语、阿拉伯语和汉语训练数据, 可以用来做实体、关系、事件抽取等任务。
- OntoNotes 5.0 数据集[33],包含英语、汉语、阿拉伯语, 实体被标注为 PERSON,ORGANIZATION,LOCATION 等 18 个类型。
6)MUC 7 数据集[34] - Twitter数据集是由Zhang等[35]提供, 不仅包含文本还包含图片信息。
大部分数据集的发布官方都直接给出了训练集、验证集和测试集的划分。同时不同的数据集可能采用不同的标注方法,最常见的标注方法有 IOB,BIOES,Markup,IO,BMEWO 等,下面详细介绍几种常用的标注方法:
1) IOB 标注法,是 CoNLL 2003 采用的标注法, I 表示内部,O 表示外部, B 表示开始。如若语料(序列)中某个词标注 B/I-XXX,B/I 表示这个词属于命名实体的开始或内部(中间或结尾),即该词是命名实体的一部分,XXX 表示命名实体的类型(如Person、Location等)。当词标注为 O 则表示属于命名实体的外部,即它不是一个命名实体。
2)BIOES 标注法,是在 IOB 方法上的扩展,具有更完备的标注规则。其中 B 表示这个词处于一个命名实体的开始,I 表示内部(中间),O 表示外部,E 表示这个词处于一个实体的结束, S 表示这个词是单独形成一个命名实体。BIOES 是目前最通用的命名实体标注方法。
3)Markup 标注法,是 OntoNotes 数据集使用的标注方法,方式比较简单。例如:ENAMEX TYPE=”ORG”>LondonENAMEX> is an international metropolis,它直接用标签把命名实体标注出来,然后通过 TYPE 字段设置相应的类型。
- 评价指标
目前,命名实体识别任务常采用的评价指标有精确率(Precision)、召回率(Recall)、F1 值(F1-Measure)等。
精确率:对给定数据集,分类正确样本个数和总样本数的比值(准确率)。即:
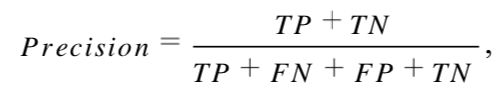
式中,TP 指正确预测为正类,FN 指错误预测为负类,FP 指错误预测为正类,TN 指正确预测为负类。
召回率: 真正为正类的样本中,有多少被预测成正类,即:

F1 值:是精确率和召回率的调和平均指标,是平衡准确率和召回率影响的综合指标。
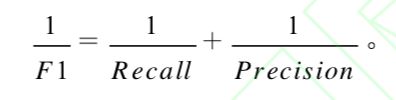
6. 参考文献
[1]. CHEN Y, ZONG C, SU K Y. On Jointly Recognizing and Aligning Bilingual Named Entities[C]//Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics. Association for Computational Linguistics, 2010: 631-639.
[2]. FENG X, FENG X, QIN B, et al. Improving Low Resource Named Entity Recognition using Cross-lingual Knowledge Transfer[C]//IJCAI. 2018: 4071-4077.
[3]. MAYHEW S, TSAI C T, ROTH D. Cheap Translation for Cross-lingual Named Entity Recognition[C]//Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, 2017: 2536-2545.
[4]. ZHOU J T, ZHANG H, JIN D, et al. Dual Adversarial Neural Transfer for Low-resource Named Entity Recognition[C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019: 3461-3471.
[5]. YANG P, LIU W, YANG J. Positive Unlabeled Learning Via Wrapper-based Adaptive Sampling[C]//IJCAI. 2017: 3273-3279.
[6]. PENG M, XING X, ZHANG Q, et al. Distantly Supervised Named Entity Recognition using Positive-Unlabeled Learning[J].arXiv preprint arXiv:1906.01378, 2019.
[7]. LING X, WELD D S. Fine-grained Entity Recognition[C]//Twenty-Sixth AAAI Conference on Artificial Intelligence, 2012.
[8]. NEELAKANTAN A, CHANG M W. Inferring Missing Entity Type Instances for Knowledge Base Completion: New dataset and methods[J]. arXiv preprint arXiv:1504.06658, 2015.
[9]. YAGHOOBZADEH Y, SCHÜTZE H. Multi-level Representations for Fine-grained Typing of Knowledge Base Entities[J]. arXiv preprint arXiv:1701.02025, 2017.
[10]. JIN H, HOU L, LI J, et al. Attributed and Predictive Entity Embedding for Fine-grained Entity Typing in Knowledge Bases[C]//Proceedings of the 27th International Conference on Computational Linguistics,2018: 282-292.
[11]. DEFFERRARD M, BRESSON X, VANDERGHEYNST P. Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering[C]//Advances in Neural Information Processing Systems,2016: 3844-3852.
[12]. ATWOOD J, TOWSLEY D. Diffusion-convolutional Neural Networks[C]//Advances in Neural Information Processing Systems,2016: 1993-2001.
[13].JINH,HOUL,etal.FineGrainedEntityTypingViaHierarchicalMultiGraphConvolutionalNetworks[C]//Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP),2019: 4970-4979.
[14]. FINKEL J R, MANNING C D. Nested Named Entity Recognition[C]//Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing: Volume 1-Volume 1. Association for Computational Linguistics, 2009: 141-150.
[15]. JU M, MIWA M, ANANIADOU S. A Neural Layered Model for Nested Named Entity Recognition[C]//Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers),2018: 1446-1459.
[16]. LU W, ROTH D. Joint Mention Extraction and Classification with Mention Hypergraphs[C]//Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, 2015: 857-867.
[17]. MUIS A O, LU W. Labeling Gaps Between Words: Recognizing Overlapping Mentions with Mention Separators[J]. arXiv preprint arXiv:1810.09073, 2018.
[18].WANGB,LUW.NeuralSegmentalHypergraphsforOverlappingMentionRecognition[J].arXivpreprintarXiv:1810.01817, 2018.
[19]. KATIYAR A, CARDIE C. Nested Named Entity Recognition Revisited[C]//Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), 2018: 861-871.
[20]. XIA C, ZHANG C, YANG T, et al. Multi-Grained Named Entity Recognition[J]. arXiv preprint arXiv:1906.08449, 2019.
[21]. LE P, TITOV I. Improving Entity Linking by Modeling Latent Relations between Mentions[J]. arXiv preprint arXiv:1804.10637, 2018.
[22]. GUPTA N, SINGH S, ROTH D. Entity Linking Via Joint Encoding of Types, Descriptions, and Context[C]//Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing. 2017: 2681-2690.
[23]. TAN C, WEI F, REN P, et al. Entity Linking for Queries by Searching Wikipedia Sentences[J]. arXiv preprint arXiv:1704.02788, 2017.
[24]. LIN Y, LIN C Y, JI H. List-only Entity Linking[C]//Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers),2017: 536-541.
[25].DAIH,SONGY,QIUL,etal.EntityLinkingwithinaSocialMediaPlatform:ACaseStudyonYelp[C]//Proceedingsofthe 2018 Conference on Empirical Methods in Natural Language Processing,2018: 2023-2032.
[26]. FRANCIS-LANDAU M, DURRETT G, KLEIN D. Capturing Semantic Similarity for Entity Linking with Convolutional Neural Networks[J]. arXiv preprint arXiv:1604.00734, 2016.
[27]. GANEA O E, HOFMANN T. Deep Joint Entity Disambiguation with Local Neural Attention[J]. arXiv preprint arXiv:1704.04920, 2017.
[28]. MUELLER D, DURRETT G. Effective Use of Context in Noisy Entity Linking[C]//Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing,2018: 1024-1029.
[29]. OUYANG X, CHEN S, ZHAO H, et al. A Multi-Cross Matching Network for Chinese Named Entity Linking in Short Text[C]//Journal of Physics: Conference Series. IOP Publishing, 2019, 1325(1): 012069.
[30]. YANG P, LIU W, YANG J. Positive Unlabeled Learning Via Wrapper-based Adaptive Sampling[C]//IJCAI. 2017: 3273-3279.
[31]. SANG E F, DE MEULDER F. Introduction to the CoNLL-2003 Shared Task: Language-independent Named Entity Recognition[J]. arXiv preprint cs/0306050, 2003.
[32]. ZHANG Y, YANG J. Chinese Ner Using Lattice Lstm[J]. arXiv preprint arXiv:1805.02023, 2018.
[33]. REN X, HE W, QU M, et al. Afet: Automatic Fine-grained Entity Typing by Hierarchical Partial-label Embedding[C]//Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, 2016: 1369-1378.
[34]. ZHOU J T, ZHANG H, JIN D, et al. Dual Adversarial Neural Transfer for Low-resource Named Entity Recognition[C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019: 3461-3471.
[35]. ZHANG Q, FU J, LIU X, et al. Adaptive Co-attention Network for Named Entity Recognition in Tweets[C]//Thirty-Second AAAI Conference on Artificial Intelligence,2018.