ceph-mimic版本的安装使用1
ceph部署实践(mimic版本)
关于luminous版本的请参照这篇文章
一、准备环境
4台adminos7.4 环境,存储节点上两块磁盘(sda操作系统,sdb数据盘)
client
admin
storage1
storage2
storage3
二、配置环境
1、修改主机名(对应节点上执行)
hostnamectl set-hostname client
hostnamectl set-hostname admin
hostnamectl set-hostname storage1
hostnamectl set-hostname storage2
hostnamectl set-hostname storage3
2、配置hosts文件(每个节点上均执行)
cat <<“EOF”>/etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
172.16.8.91 client
172.16.8.92 admin
172.16.8.93 admin
172.16.8.94 storage1
172.16.8.95 storage2
172.16.8.96 storage3
EOF
3、修改sudo配置文件,注释下面行(每个节点上均执行)
执行visudo命令注释下面一行
#Defaults requiretty
4、ceph的官方源在国外,网速比较慢,此处添加ceph源为清华源(每个节点上均执行)
cat
[Ceph]
name=Ceph packages for $basearch
baseurl=https://mirrors.tuna.tsinghua.edu.cn/ceph/rpm-mimic/el7/x86_64/
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc
[Ceph-noarch]
name=Ceph noarch packages
baseurl=https://mirrors.tuna.tsinghua.edu.cn/ceph/rpm-mimic/el7/noarch/
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc
[ceph-source]
name=Ceph source packages
baseurl=https://mirrors.tuna.tsinghua.edu.cn/ceph/rpm-mimic/el7/SRPMS/
enabled=1
gpgcheck=1
type=rpm-md
gpgkey=https://download.ceph.com/keys/release.asc
END
5、关闭selinux和firewall(各个节点)
setenforce 0
sed -i “s/SELINUX=enforcing/SELINUX=permissive/g” /etc/selinux/config
systemctl disable firewalld.service
systemctl stop firewalld.service
6、各个节点更新系统(各个节点)
yum update -y
注意:如果最新操作系统:此步骤可以省略
7、创建用户并设置密码为Changeme_123(各个节点)
useradd admin
echo Changeme_123 | passwd --stdin admin
8、配置sudo权限(各个节点)
echo -e ‘Defaults:admin !requiretty\nadmin ALL = (root) NOPASSWD:ALL’ | tee /etc/sudoers.d/ceph
chmod 440 /etc/sudoers.d/ceph
9、安装NTP(各个节点)
yum -y install ntp
修改配置文件/etc/ntp.conf
server NTP-server
注意:
NTP-server修改为自己的NTP服务器,如果局域网内无NTP服务器,此处可以用默认配置,采用centos官方ntp服务器
启动服务并设置开机启动
systemctl start ntpd
systemctl enable ntpd
查看ntp状态
ntpq -p
注意:
如果ntp时钟不同步,后面ceph服务起不来!
9、重启(各个节点)
reboot
三、安装和配置ceph(以下操作均在admin节点上执行)
1、配置互信
su - admin
$ ssh-keygen -t dsa -f ~/.ssh/id_dsa -N “”
$ ssh-copy-id 172.16.8.91
$ ssh-copy-id 172.16.8.92
$ ssh-copy-id 172.16.8.93
$ ssh-copy-id 172.16.8.94
$ ssh-copy-id 172.16.8.95
exit
2、安装ceph-deploy包
$ sudo yum -y install ceph-deploy
注意:最新版的ceph-deploy是2.0,安装操作系统用mimal的ISo会报如下错误,需要安装python-setuptools
[root@storage1 ceph]# ceph-deploy --help
Traceback (most recent call last):
File “/bin/ceph-deploy”, line 18, in
from ceph_deploy.cli import main
File “/usr/lib/python2.7/site-packages/ceph_deploy/cli.py”, line 1, in
import pkg_resources
ImportError: No module named pkg_resources
yum install python-setuptools
3、创建配置文件目录
$ mkdir /etc/ceph
4、创建集群
$ cd /etc/ceph
$ ceph-deploy new storage1 storage2 storage3
注意:如果需要指定网络,创建命令跟以下参数
–cluster-network
–public-network
5、在各个节点上安装ceph包
yum -y install ceph ceph-radosgw
6、、设置monitor和key
$ ceph-deploy mon create-initial
注意:执行完成后会在/etc/ceph目录多以下内容:
ceph.client.admin.keyring
ceph.bootstrap-mgr.keyring
ceph.bootstrap-osd.keyring
ceph.bootstrap-mds.keyring
ceph.bootstrap-rgw.keyring
ceph.bootstrap-rbd.keyring
ceph.bootstrap-rbd-mirror.keyring
7、将ceph.client.admin.keyring拷贝到各个节点上
ceph-deploy admin storage1 storage2 storage3
8、安装MGR
ceph-deploy mgr create storage1 storage2 storage3
9、启动osd,如果磁盘比较多,安装规划磁盘名称,重复执行即可
ceph-deploy osd create --data /dev/sdb storage1
ceph-deploy osd create --data /dev/sdb storage2
ceph-deploy osd create --data /dev/sdb storage3
拓展:
默认采用的是bluestore,如果需要指定更详细的参数请参照下面步骤:
使用filestore
9.1.1、使用filestore采用journal模式(每个节点数据盘需要两块盘或两个分区)
创建逻辑卷
vgcreate data /dev/sdb
lvcreate --size 100G --name log data
9.1.2、创建OSD
ceph-deploy osd create --filestore --fs-type xfs --data /dev/sdc --journal data/log storage1
ceph-deploy osd create --filestore --fs-type xfs --data /dev/sdc --journal data/log storage2
ceph-deploy osd create --filestore --fs-type xfs --data /dev/sdc --journal data/log storage3
使用bluestore
9.2.1、创建逻辑卷
vgcreate cache /dev/sdb
lvcreate --size 100G --name db-lv-0 cache
vgcreate cache /dev/sdb
lvcreate --size 100G --name wal-lv-0 cache
9.2.2、创建OSD
ceph-deploy osd create --bluestore storage1 --data /dev/sdc --block-db cache/db-lv-0 --block-wal cache/wal-lv-0
ceph-deploy osd create --bluestore storage2 --data /dev/sdc --block-db cache/db-lv-0 --block-wal cache/wal-lv-0
ceph-deploy osd create --bluestore storage3 --data /dev/sdc --block-db cache/db-lv-0 --block-wal cache/wal-lv-0
关于filestore和bluestore的区别这篇文章做了详细的说明,在有ssd的情况下bluestore优势比较明显。
http://www.yuncunchu.org/portal.php?mod=view&aid=74
wal & db 的大小问题
使用混合机械和固态硬盘设置时,block.db为Bluestore创建足够大的逻辑卷非常重要 。通常,block.db应该具有 尽可能大的逻辑卷。
建议block.db尺寸不小于4% block。例如,如果block大小为1TB,则block.db 不应小于40GB。
如果不使用快速和慢速设备的混合,则不需要为block.db(或block.wal)创建单独的逻辑卷。Bluestore将在空间内自动管理这些内容block。
- Ceph fileStore与 blueStore 架构对比
1.1.ceph 消息处理逻辑架构图
ceph后端支持多种存储引擎,以插件化的形式来进行管理使用,目前支持filestore,kvstore,memstore以及bluestore,目前默认使用的是filestore,但是目前bluestore也可以上生产。
1)Firestore存在的问题是:
在写数据前需要先写journal,会有一倍的写放大;
若是另外配备SSD盘给journal使用又增加额外的成本;
filestore一开始只是对于SATA/SAS这一类机械盘进行设计的,没有专门针对SSD这一类的Flash介质盘做考虑。
2)而Bluestore的优势在于:
减少写放大;
针对FLASH介质盘做优化;
直接管理裸盘,进一步减少文件系统部分的开销。
但是在机械盘场景Bluestore与firestore在性能上并没有太大的优势,bluestore的优势在于flash介质盘。
1.2. FileStore逻辑架构

1)首先,为了提高写事务的性能,FileStore增加了fileJournal功能,所有的写事务在被FileJournal处理以后都会立即callback(上图中的第2步)。日志是按append only的方式处理的,每次都是被append到journal文件末尾,同时该事务会被塞到FileStore op queue;
2)接着,FileStore采用多个thread的方式从op queue 这个 thread pool里获取op,然后真正apply事务数据到disk(文件系统pagecache)。当FileStore将事务落到disk上之后,后续的读请求才会继续(上图中的第5步)。
3)当FileStore完成一个op后,对应的Journal才可以丢弃这部分Journal。对于每一个副本都有这两步操作,先写journal,再写到disk,如果是3副本,就涉及到6次写操作,因此性能上体现不是很好。
1.3. Bluestore逻辑架构

1)Bluestore实现了直接管理裸设备的方式,抛弃了本地文件系统,BlockDevice实现在用户态下使用linux aio直接对裸设备进行I/O操作,去除了本地文件系统的消耗,减少系统复杂度,更有利于Flash介质盘发挥性能优势;
2)为了惯例裸设备就需要一个磁盘的空间管理系统,Bluestore采用Allocator进行裸设备的空间管理,目前支持StupidAllocator和BitmapAllocator两种方式;
3)Bluestore的元数据是以KEY-VALUE的形式保存到RockDB里的,而RockDB又不能直接操作裸盘,为此,bluestore实现了一个BlueRocksEnv,继承自EnvWrapper,来为RocksDB提供底层文件系统的抽象接口支持;
4)为了对接BlueRocksEnv,Bluestore自己实现了一个简洁的文件系统BlueFS,只实现RocksDB Env所需要的接口,在系统启动挂在这个文件系统的时候将所有的元数据都加载到内存中,BluesFS的数据和日志文件都通过BlockDevice保存到底层的裸设备上;
5)BlueFS和BlueStore可以共享裸设备,也可以分别指定不同的设备,比如为了获得更好的性能Bluestore可以采用 SATA SSD 盘,BlueFS采用 NVMe SSD 盘。
10、验证
$ ceph health
HEALTH_OK
四、ceph集群对外提供块存储服务(均在client上执行)
1、通过admin用户登录client节点
[admin@client ~]$ sudo chmod 644 /etc/ceph/ceph.client.admin.keyring
2、创建一个存储池
[admin@client ~]$ ceph osd pool create test 128
注意:
创建pool 通常在创建pool之前,需要覆盖默认的pg_num,官方推荐:
若少于5个OSD, 设置pg_num为128。
5~10个OSD,设置pg_num为512。
10~50个OSD,设置pg_num为4096。
超过50个OSD,可以参考pgcalc计算
3、创建一个10G的块
[admin@client ~]$ rbd create disk01 --size 10G --image-feature layering
rbd create --size 10G disk01 --pool test
4、查看rbd
[admin@client ~]$ rbd ls -l
NAME SIZE PARENT FMT PROT LOCK
disk01 10240M 2
5、将10G的块映射到本地
[admin@client ~]$ sudo rbd map disk01
/dev/rbd0
注意:
因为adminos7默认内核版本比较低,ceph的一些特性无法使用,需要手动禁用才能map成功。命令如下
$ rbd feature disable test/disk01 exclusive-lock object-map fast-diff deep-flatten
6、查看映射
[admin@client ~]$ rbd showmapped
id pool image snap device
0 rbd disk01 - /dev/rbd0
7、格式化为xfs格式
[admin@client ~]$ sudo mkfs.xfs /dev/rbd0
8、挂载rbd0到本地的目录中
[admin@client ~]$ sudo mount /dev/rbd0 /mnt
[admin@client ~]$ df -hT
Filesystem Type Size Used Avail Use% Mounted on
/dev/mapper/cl-root xfs 26G 1.8G 25G 7% /
devtmpfs devtmpfs 2.0G 0 2.0G 0% /dev
tmpfs tmpfs 2.0G 0 2.0G 0% /dev/shm
tmpfs tmpfs 2.0G 8.4M 2.0G 1% /run
tmpfs tmpfs 2.0G 0 2.0G 0% /sys/fs/cgroup
/dev/vda1 xfs 1014M 231M 784M 23% /boot
tmpfs tmpfs 396M 0 396M 0% /run/user/0
/dev/rbd0 xfs 10G 33M 10G 1% /mnt
五、使用ceph集群提供cephfs文件系统
1、在admin节点上执行如下命令,启用storage1上的mds服务
[admin@admin ceph]$ ceph-deploy mds create storage1
2、在storage1节点上进行如下操作
[admin@storage1 ~]$ sudo chmod 644 /etc/ceph/ceph.client.admin.keyring
3、创建名为cephfs_data的pool
[admin@storage1 ~]$ ceph osd pool create cephfs_data 128
pool ‘cephfs_data’ created
4、创建名为cephfs_metadata的pool
[admin@storage1 ~]$ ceph osd pool create cephfs_metadata 128
pool ‘cephfs_metadata’ created
5、启用pool
[admin@storage1 ~]$ ceph fs new cephfs cephfs_metadata cephfs_data
new fs with metadata pool 2 and data pool 1
6、查看
[admin@storage1 ~]$ ceph fs ls
name: cephfs, metadata pool: cephfs_metadata, data pools: [cephfs_data ]
7、查看mds状态
[admin@storage1 ~]$ ceph mds stat
e4: 1/1/1 up {0=storage1=up:creating}
以下操作在client节点上
8、安装rpm包
[root@client ~]# yum -y install ceph-fuse
9、获取admin的key
[root@client ~]# ssh admin@storage1 “sudo ceph-authtool -p /etc/ceph/ceph.client.admin.keyring” > admin.key
[root@client ~]# chmod 600 admin.key
10、挂载
[root@client ~]# mount -t ceph storage1:6789:/ /mnt -o name=admin,secretfile=admin.key
[root@client ~]# df -hT
Filesystem Type Size Used Avail Use% Mounted on
/dev/mapper/cl-root xfs 26G 1.9G 25G 7% /
devtmpfs devtmpfs 2.0G 0 2.0G 0% /dev
tmpfs tmpfs 2.0G 0 2.0G 0% /dev/shm
tmpfs tmpfs 2.0G 8.4M 2.0G 1% /run
tmpfs tmpfs 2.0G 0 2.0G 0% /sys/fs/cgroup
/dev/vda1 xfs 1014M 231M 784M 23% /boot
tmpfs tmpfs 396M 0 396M 0% /run/user/0
172.16.8.94:6789:/ ceph 78G 21G 58G 27% /mnt
六、安装RGW
radosgw的FastCGI可以支持多种类型的WebServer,如Apache2、Nginx等。Ceph从Hammer版本开始,在使用Ceph-deploy的情况下默认使用内置的civetweb替代旧版本的Apache2部署方式。
6.1、安装rgw服务
ceph-deploy rgw create storage1 storage2 storage3
6.2、查看状态
[root@storage1 ceph]# ceph -s
cluster:
id: 9eb106eb-2af4-4aaf-bcdb-58e95bce828c
health: HEALTH_OK
services:
mon: 3 daemons, quorum storage1,storage2,storage3
mgr: storage3(active), standbys: storage1, storage2
osd: 3 osds: 3 up, 3 in
rgw: 3 daemons active
data:
pools: 4 pools, 32 pgs
objects: 189 objects, 2.2 KiB
usage: 3.0 GiB used, 237 GiB / 240 GiB avail
pgs: 32 active+clean
io:
client: 48 KiB/s rd, 0 B/s wr, 57 op/s rd, 38 op/s wr
七、安装dashboard
mimic 版 dashboard 安装
1、添加mgr 功能
ceph-deploy mgr create node1 node2 node3
2、开启dashboard 功能
ceph mgr module enable dashboard
3、创建证书
ceph dashboard create-self-signed-cert
4、创建 web 登录用户密码
ceph dashboard set-login-credentials user-name password
5、查看服务访问方式
ceph mgr services
6、在/etc/ceph/ceph.conf中添加
[mgr]
mgr modules = dashboard
7、设置dashboard的ip和端口
ceph config-key put mgr/dashboard/server_addr 192.168.8.106
ceph config-key put mgr/dashboard/server_port 7000
8、登录:
https://172.16.8.94:7000
在这里插入图片描述
八、通过grafana监控ceph
1、启用Prometheus监控模块:
ceph mgr module enable prometheus
ss -tlnp|grep 9283
LISTEN 0 5 :::9283 ::? users:((“ceph-mgr”,pid=3715,fd=70))
2、安装Prometheus:
下载软件包
wget https://github.com/prometheus/prometheus/releases/download/v1.5.2/prometheus-1.5.2.linux-amd64.tar.gz
将prometheus拷贝到/usr/local/bin/下
tar -zxvf prometheus-*.tar.gz
cd prometheus-*
cp prometheus promtool /usr/local/bin/
prometheus --version
prometheus, version 2.3.2 (branch: HEAD, revision: 71af5e29e815795e9dd14742ee7725682fa14b7b)
build user: root@5258e0bd9cc1
build date: 20180712-14:02:52
go version: go1.10.3
3、配置prometheus服务
mkdir /etc/prometheus
mkdir /var/lib/prometheus
4、创建 /usr/lib/systemd/system/prometheus.service
vim /usr/lib/systemd/system/prometheus.service ###配置启动项
[Unit]
Description=Prometheus
Documentation=https://prometheus.io
[Service]
Type=simple
WorkingDirectory=/var/lib/prometheus
EnvironmentFile=-/etc/prometheus/prometheus.yml
ExecStart=/usr/local/bin/prometheus
–config.file /etc/prometheus/prometheus.yml
–storage.tsdb.path /var/lib/prometheus/
[Install]
WantedBy=multi-user.target
5、创建配置文件
vim /etc/prometheus/prometheus.yml ##配置配置文件
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: ‘prometheus’
static_configs:- targets: [‘172.16.8.94:9090’] #storage1的IP
- job_name: ‘ceph’
static_configs:- targets:
- 172.16.8.94:9283
- 172.16.8.95:9283
- 172.16.8.96:9283
6、启动服务
- targets:
systemctl daemon-reload
systemctl start prometheus
systemctl status prometheus
7、验证:
http://172.16.8.94:9090/graph
在这里插入图片描述
6、安装grafana:
yum -y localinstall https://s3-us-west-2.amazonaws.com/grafana-releases/release/grafana-5.2.2-1.x86_64.rpm
systemctl start grafana-server
systemctl status grafana-server
7、登录grafana
http://172.16.8.94:9000/
默认用户名和密码:admin/admin,登录后需要修改密码。
8、添加数据源
参照:
http://blog.51cto.com/wangzhijian/2156186
下载json
https://grafana.com/dashboards/917
附录:
1、卸载
在admin节点上执行卸载rpm包
$ ceph-deploy purge admin storage1 storage2 storage3
在admin节点上执行,删除配置
$ ceph-deploy purgedata admin storage1 storage2 storage3
$ ceph-deploy forgetkeys
2、修复一个HEALTH_WARN
[root@storage1 ~]# ceph -s
cluster:
id: 9eb106eb-2af4-4aaf-bcdb-58e95bce828c
health: HEALTH_WARN
application not enabled on 1 pool(s)
services:
mon: 3 daemons, quorum storage1,storage2,storage3
mgr: storage3(active), standbys: storage1, storage2
osd: 3 osds: 3 up, 3 in
rgw: 3 daemons active
data:
pools: 5 pools, 96 pgs
objects: 2.79 k objects, 9.8 GiB
usage: 18 GiB used, 222 GiB / 240 GiB avail
pgs: 96 active+clean
通过ceph health detail查看原因
[root@storage1 ~]# ceph health detail
HEALTH_WARN application not enabled on 1 pool(s)
POOL_APP_NOT_ENABLED application not enabled on 1 pool(s)
application not enabled on pool ‘test’
use 'ceph osd pool application enable ', where is ‘cephfs’, ‘rbd’, ‘rgw’, or freeform for custom applications.
解决办法
ceph osd pool application enable test rbd
3、删除 pool
先在ceph.conf 增加下面:
mon_allow_pool_delete = true
并重启ceph-mon:
systemctl restart ceph-mon@storage1
启用dashboard
使用如下命令即可启用dashboard模块:
ceph mgr module enable dashboard
默认情况下,仪表板的所有HTTP连接均使用SSL/TLS进行保护。
要快速启动并运行仪表板,可以使用以下内置命令生成并安装自签名证书:
ceph dashboard create-self-signed-cert
Self-signed certificate created
创建具有管理员角色的用户:
ceph dashboard set-login-credentials admin admin
Username and password updated
查看ceph-mgr服务:
默认下,仪表板的守护程序(即当前活动的管理器)将绑定到TCP端口8443或8080
ceph mgr services
{
“dashboard”: “https://ceph01:8080/”,
}
浏览器输入https://ceph01:8080输入用户名admin,密码admin登录即可查看

查看集群状态:


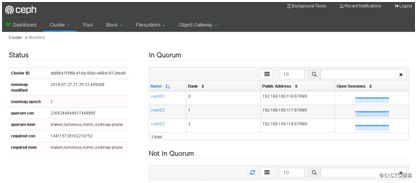

6.启用Prometheus模块
启用Prometheus监控模块:
ceph mgr module enable prometheus
ss -tlnp|grep 9283
LISTEN 0 5 :::9283 ::? users:((“ceph-mgr”,pid=3715,fd=70))
ceph mgr services
{
“dashboard”: “https://ceph01:8080/”,
“prometheus”: “http://ceph01:9283/”
}
安装Prometheus:
tar -zxvf prometheus-*.tar.gz
cd prometheus-*
cp prometheus promtool /usr/local/bin/
prometheus --version
prometheus, version 2.3.2 (branch: HEAD, revision: 71af5e29e815795e9dd14742ee7725682fa14b7b)
build user: root@5258e0bd9cc1
build date: 20180712-14:02:52
go version: go1.10.3
mkdir /etc/prometheus && mkdir /var/lib/prometheus
vim /usr/lib/systemd/system/prometheus.service ###配置启动项
[Unit]
Description=Prometheus
Documentation=https://prometheus.io
[Service]
Type=simple
WorkingDirectory=/var/lib/prometheus
EnvironmentFile=-/etc/prometheus/prometheus.yml
ExecStart=/usr/local/bin/prometheus
–config.file /etc/prometheus/prometheus.yml
–storage.tsdb.path /var/lib/prometheus/
[Install]
WantedBy=multi-user.target
vim /etc/prometheus/prometheus.yml ##配置配置文件
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: ‘prometheus’
static_configs:- targets: [‘192.168.100.116:9090’]
- job_name: ‘ceph’
static_configs:- targets:
- 192.168.100.116:9283
- 192.168.100.117:9283
- 192.168.100.118:9283
- targets:
systemctl daemon-reload
systemctl start prometheus
systemctl status prometheus
安装grafana:
wget https://s3-us-west-2.amazonaws.com/grafana-releases/release/grafana-5.2.2-1.x86_64.rpm
yum -y localinstall grafana-5.2.2-1.x86_64.rpm
systemctl start grafana-server
systemctl status grafana-server

输入默认帐号密码admin登录之后会提示更改默认密码,更改后即可进入,之后添加数据源:

配置数据源名称、类型以及其URL

然后点击最下边的“Save&Test”,提示“Data source is working”即是成功连接数据源

从grafana官网上下载相应仪表盘文件并导入到grafana

最后呈现效果如下:

cephfs几种挂载方式
一、启用cephfs
Ceph文件系统至少需要两个RADOS池,一个用于数据,一个用于元数据
启用mds服务
ceph-deploy mds create node01
创建数据pool
ceph osd pool create cephfs_data 128
创建Metadata池
ceph osd pool create cephfs_metadata 128
启用pool
ceph fs new cephfs cephfs_metadata cephfs_data
查看cephfs
ceph fs ls
二、挂载cephfs
挂载cephfs有两种方式,kernel driver和fuse
1、kernel driver挂载
关闭认证情况下
sudo mkdir /mnt/wyl
sudo mount -t ceph 192.168.0.1:6789:/ /mnt/wyl
设置开机自动挂载/etc/fstab
172.16.70.77:6789:/ /mnt/ceph ceph noatime,_netdev 0 2
启用认证
cat ceph.client.admin.keyring
[client.admin]
key = AQBSdU5bT27AKxAAvKoWQdGpSuNRCHjC4B8DVA==
mount -t ceph 172.16.70.77:6789:/ /wyl -o name=admin,secret=AQBSdU5bT27AKxAAvKoWQdGpSuNRCHjC4B8DVA==
设置开机自动挂载/etc/fstab
172.16.70.77:6789:/ /mnt/ceph ceph name=admin,secretfile=/etc/ceph/secret.key,noatime,_netdev 0 2
注意:检查是否启用cephx认证方法,如果值为none为禁用,cephx为启用
[root@node1 ceph]# cat /etc/ceph/ceph.conf | grep auth | grep required
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
2、fuse挂载
安装挂载工具
yum -y install ceph-fuse ceph
将存储节点的admin秘钥拷贝到本地
ssh root@node1 “ceph-authtool -p /etc/ceph/ceph.client.admin.keyring” > admin.key
root@node1’s password:
赋予权限
chmod 600 admin.key
执行挂载
mount -t ceph node1:6789:/ /mnt -o name=admin,secretfile=admin.key
df -hT
设置开机自动挂载/etc/fstab
id=admin,conf=/etc/ceph/ceph.conf /mnt fuse.ceph defaults 0 0
mds可以同时启用多个节点,不同的client挂载不同mds存储节点,不同client可以同时写数据,数据是共享的
3、windows挂载:
https://github.com/ksingh7/ceph-cookbook/tree/master/ceph-dokan
安装dokaninstall.exe
存储多路径实践
一、服务端
1、安装epel源
yum --enablerepo=epel -y install scsi-target-utils
2、修改配置文件/etc/tgt/targets.conf
incominguser username “b021191eb4fb613a” #用户名及密码,注意密码长度
3、配置selinux # chcon -R -t tgtd_var_lib_t /iscsi_disks # semanage fcontext -a -t tgtd_var_lib_t /iscsi_disks 4、配置防火墙 # firewall-cmd --add-service=iscsi-target --permanent # firewall-cmd --reload 5、重启tgtd并设置开机启动 # systemctl restart tgtd # systemctl enable tgtd 6、查看状态 # tgtadm --mode target --op show 二、客户端 安装软件包 # yum -y install iscsi-initiator-utils 修改InitiatorName(可不改) # vi /etc/iscsi/initiatorname.iscsi InitiatorName=iqn.2014-07.test.com 修改配置文件/etc/iscsi/iscsid.conf node.session.auth.authmethod = CHAP node.session.auth.username = username node.session.auth.password = password 发现目标 # iscsiadm -m discovery -t sendtargets -p 192.168.8.101 # iscsiadm -m discovery -t sendtargets -p 192.168.8.102 确认状态 # iscsiadm -m node -o show 登录 # iscsiadm -m node --login 查看会话 # iscsiadm -m session -o show 以下步骤也在客户端操作 安装 yum install device-mapper-multipath 设置开机启动 systemctl enable multipathd.service 添加配置文件 需要multipath正常工作只需要如下配置即可,如果想要了解详细的配置,请参考Multipath # vi /etc/multipath.conf blacklist { devnode "^sd[a-e]" #过滤磁盘,哪些不做多路径 } defaults { user_friendly_names yes path_grouping_policy multibus failback immediate no_path_retry fail } 加载内核模块 # modprobe dm-multipath 启动服务 # systemctl start multipathd.service 查看服务 # multipath -ll mpatha (360000000000000000e00000000010001) dm-2 IET ,VIRTUAL-DISK size=30G features='0' hwhandler='0' wp=rw `-+- policy='service-time 0' prio=1 status=active |- 3:0:0:1 sdd 8:48 active ready running `- 4:0:0:1 sde 8:64 active ready running 此时,执行lsblk命令就可以看到多路径磁盘mpatha了: # lsblk NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT sda 8:0 0 20G 0 disk ├─sda1 8:1 0 500M 0 part /boot └─sda2 8:2 0 19.5G 0 part ├─centos-root 253:0 0 17.5G 0 lvm / └─centos-swap 253:1 0 2G 0 lvm [SWAP] sdb 8:16 0 30G 0 disk sdc 8:32 0 30G 0 disk sdd 8:48 0 30G 0 disk └─mpatha 253:2 0 30G 0 mpath sde 8:64 0 30G 0 disk └─mpatha 253:2 0 30G 0 mpath sr0 11:0 1 603M 0 rom 格式化磁盘 mkfs.xfs /dev/mapper/mpathf -f 挂载磁盘 mount /dev/mapper/mpathf /mnt/ 查看分区 [root@localhost mnt]# df -h Filesystem Size Used Avail Use% Mounted on /dev/mapper/centos-root 98G 891M 97G 1% / devtmpfs 16G 0 16G 0% /dev tmpfs 16G 0 16G 0% /dev/shm tmpfs 16G 8.6M 16G 1% /run tmpfs 16G 0 16G 0% /sys/fs/cgroup /dev/sda1 497M 120M 377M 25% /boot tmpfs 3.2G 0 3.2G 0% /run/user/0 /dev/mapper/mpathf 500G 33M 500G 1% /mnt 配置自动挂载,修改/etc/fstab /dev/mapper/mpathf /mnt/ xfs _netdev 0 0 在服务端down一个网卡 [root@localhost ~]# ifdown eno33559296 Device 'eno33559296' successfully disconnected. 在客户端测试读写 [root@localhost mnt]# dd if=/dev/zero of=test bs=4M count=1024 1024+0 records in 1024+0 records out 4294967296 bytes (4.3 GB) copied, 5.77562 s, 744 MB/s 在服务端恢复刚才down的网卡,然后down另一个网卡 [root@localhost ~]# ifup eno33559296 Device 'eno33559296' successfully disconnected. [root@localhost ~]# ifdown eno16780032 Device 'eno33559296' successfully disconnected. 在客户端测试 [root@localhost mnt]# dd if=/dev/zero of=test1 bs=4M count=1024 1024+0 records in 1024+0 records out 4294967296 bytes (4.3 GB) copied, 5.93495 s, 724 MB/s比较Swift与HDFS话Ceph本质
Ceph是一个支持大量小文件和随机读写的分布式文件系统,在维护 POSIX 兼容性的同时加入了复制和容错功能。目前Ceph已经被加到了Linux内核之中,虽然可能还不适用于生产环境。它也想实现统一存储的目标,即:
对象系统,类似Swift, 这里是RADOS, Reliable Autonomic Distributed Object Store, 可靠的自主分布式对象存储。在每台host上都要运行OSD(Object Storage Daemon)进程,当然,如果已经用RAID, LVM或btrf,xfs(最好别用ext4)将每台host上的硬盘都做成一个池了的话,运行一个OSD就可以了。OSD会默认创建三个池:data, metada与RBD 。同时,在每台host上还要运行MON (Monitor)进程。
文件存储,类似Hadoop中的HDFS,但HDFS是流式存储,即一次写多次读。想使用Ceph文件存储的话,那还在每台host上还要运行MDS(Meta-Data Server)进程。MDS是在对象系统的基础之上为Ceph客户端又提供的一层POSIX文件系统抽象实现。
块存储, 类似Cinder
这样说来,至少有下列几种方式可以访问Ceph中的对象:
RADOS方式,RADOS是Ceph的基础,即使对于Ceph文件存储,底层也是使用RADOS,RADOS本来提供一个librados库来访问对象,这个库支持php, java, python, c/c++。还通过RADOS Gateway来提供和Swift与Amazon-S3兼容的REST接口。
RBD(rados block device)与QEMU-RBD,前面说了,Ceph已经加到内核了,所以可以使用内核的RBD驱动来访问对象,它也和QEMU-RBD兼容。
CephFS, 上述MDS提供的POSIX兼容的文件系统。在生产系统中,建议用以上三种方式,不建议这种。
一个数据块具体存放在哪些host上需要有元数据来描述,HDFS是在一台机器上集中存储元数据的(HA可以通过配置主备实现),Swift则完全是分布式的,一个数据块具体存放在哪些host(在Ceph中称OSD, OSD是在host上维护数据块的一个进程)上由一致性哈希算法决定,元数据使用rsync命令同步分布在每一个host上,所以需要分级来减小元数据的大小,所以也就有了Accounts, Containers, Objects这三级RING。对应在RADOS中,有两级映射,先经过哈希把key映射到PG (Placement Group, 为了减小抖动,PG是通过公式:(Totol_num_of_OSD * 100 ) / max_replication_count) / Pool_Count)),再通过一致性哈希函数CRUSH从PGID映射到实际存储数据的host (OSD)。Swift使用的一致性哈希算法使用flat的host列表,但是CRUSH这种一致性哈希算法使用的host列表具有层次结构(CRUSH: disk, node, rack, row, switch, power circuit, room, DC, 再引入pool逻辑概念,rules告诉CRUSH如何复制数据到不同的pool),并且能允许用户通过指定policies把复制存放在不同的机架。剩下的事和Swift类似,CRUSH会生成在RING上产生副本信息,第一个副本是主,其它是从,主负责接收来自客户端的写,及协调多个客户端的写,主再将数据写给从,待主返回结果后,主才告诉用户写成功,所以副本是强一致性的,这点和AWS dynamo这些最终一致性的做法有些区别。当新增机器或发生宕机时,和swift也类似,CRUSH一致性哈希算法也会保证数据的抖动性最小(即转移的数据块最少)。
除了存储节点外,还有一些监控节点组成的小集群,负责监控存储节点的运行状态,它们通过Paxos协议达到一致和保持数据冗余,Paxos和ZooKeeper中用到的领导者选择算法Zap协议类似,只要保证这些host中的大多数host不出故障就行,并且我们一般选择奇数台host,举个例子,在5个host的监控集群中,任何两台机器故障的情况下服务都能继续运行。
在一致性保证方面,在ZooKeeper中,领导者与跟随者非常聪明,跟随者通过更新号(唯一的全局标识叫zxid, ZooKeeper Transaction ID)来滞后领导者,这样大部分host确认更新之后,写操作就能被提交了。Ceph换汤不换药,这个全局标识改了个名叫epoch序号(例如:OSD加入或删除会更新MDS节点上的OSD Map元数据,相关的OSD或随机的OSD会被push更新,所以会有osd.a是更新后的,osd.b是旧的,那么当osd.b与MDS通信时会带上epoch,发现这个值比它低,就会更新。这也是osd_find_best_info_ignore_history_les参数能让OSD重新加入元数据恢复PG状态的原理),所以Monitor节点记录的是epoch序号和一些全局状态(如存储节点是否在线,地址端口等),非常轻量,每个监测到存储节点发生变更时,如存储节点上线或下线,将epoch序号增加以区别先前的状态。总之,Monitor节点维护了这些集群状态映射对象ClusterMap,包括:monitor map, OSD map, placement group (PG) map, CRUSH map, mds map。例如当存储节点宕机时,监控节点发现后更新epoch和ClusterMap,然后通过gossip p2p方式推送给存储节点(这种p2p通知和存储节点自主复制和HDFS中的master-slave模型是有区别的),存储节点再重新计算CRUSH决定将宕机机器丢失副本补上,由于一致性哈希的特性,发生变更的PG不会很多,也就是说抖动性不会很大。
通过将Ceph与现有的Swift, Hadoop等现有技术一坐标映射,到了这一步,笔者也就清楚Ceph是做什么的了。有机会再看看OpenStack是怎样用它的,以及它是怎样具体安装部署的。
通过iscsi使用ceph的块设备
一、 问题提出
现在要求把机房的设备存储都利用起来,建立一个存储池,能满足用多少创建多少而且能够跨平台挂载创建的硬盘。目前,已经建立起来了CEPH的集群,存储池达到了56244M,于是设想创建一个RBD(RADOS block device),然后通过ISCSI-target把创建的RBD导出来用于客户端的挂载,这个客户端可以是任意linux和windows。
二、 可行性分析
上述的问题的实现主要是两部分,一部分是创建RBD,另一部分是通过安装ISCSI-target把RBD导出,用于Ceph集群外主机挂载。目前的实验环境已经可以成功的创建RBD用于Ceph集群内的装有RBD客户端的主机挂载,剩下的就是第二部分的实现。由于Ceph已经支持通过iscsi协议来使用rbd,所以在理论上是可行的。
三、具体的实现过程
3.1 环境说明
实验平台:还是在我之前文章中搭建的三节点的ceph集群基础上操作。
客户测试端:能够ping通ceph-mon节点的主机,在这里我的是自己的win10计算机【ceph-mon节点是:192.168.1.220 win10是:192.168.1.153】
服务端 ISCSI-target采用Linux SCSI target framework (tgt)(http://stgt.sourceforge.net/)
3.2 创建RBD
在ceph-mon节点执行下面命令:
rbd create --size {megabytes} {pool-name}/{image-name}
比如创建大小为1GB,名为ceph-rbd1的RBD:
rbd create rbds_pool/iscsi-image --size 4096
未指定pool-name则默认创建到rbd池里面
查看RBD:rbd ls {poolname} 不加poolname默认查看rbd池下的RBD
查看RBD详细信息:
rbd info {pool-name}/{image-name}
[root@node1 ~]# rbd info rbds_pool/iscsi-image
rbd image ‘iscsi-image’:
size 4096 MB in 1024 objects
order 22 (4096 kB objects)
block_name_prefix: rbd_data.d3562ae8944a
format: 2
features: layering, exclusive-lock, object-map, fast-diff, deep-flatten
flags:
比如查看ceph-rbd1:rbd info ceph-rbd1 不加pool-name默认rbd池
3.3 映射RBD
创建好的RBD需要映射到客户机才能使用,客户机需要内核支持Ceph块设备和文件系统,推荐内核2.6.34或更高版本。
检查Linux版本和对RBD的支持:
modprobe rbd
modprobe rbd没有返回消息说明内核对rbd支持。
在ceph-osd节点执行下面命令:
rbd map rbd/ceph-rbd1
格式是rbd map {pool-name}/{image-name} 不加{pool-name}默认rbd
查看映射后的RBD在操作系统中的设备名:
rbd showmapped
可以看到创建的RBD在操作系统的设备名是/dev/rbd1
fdisk –l /dev/rbd1#参看分区情况
如果用于本机挂载执行接下来步骤:
mkfs.xfs /dev/rbd1 #格式化RBD
mkdir /mnt/ceph-vol1 #创建挂载点
mount /dev/rbd1 /mnt/ceph-vol1 #挂载RBD,可以写入数据测试一下挂载后的RBD
不过我们的目的是Ceph集群外主机挂载RBD,所以上面的步骤了解一下即可,集群外主机挂载RBD需要用到ISCSI-target。
3.4 配置rbdmap
根据网络文档了解到,创建rbd块设备并rbd map后,如果不及时rbd unmap,关机的时候系统会停留在umount此rbd设备上。所以要配置rbdmap。官方文档无rbdmap的介绍,而且这个脚本也不是官方发布的,为避免遇到这种问题先下载并设置开机启动rbdmap,将来再尝试不加入这个脚本会不会出现问题。
sudo wget https://raw.github.com/ceph/ceph/a4ddf704868832e119d7949e96fe35ab1920f06a/src/init-rbdmap -O /etc/init.d/rbdmap #获得脚本文件
sudo chmod +x /etc/init.d/rbdmap #增加执行权限
sudo update-rc.d rbdmap defaults #添加开机启动
修改rbdmap的配置文件/etc/ceph/rbdmap将映射好的rbd添加进去,注意/etc/ceph/rbdmap路径是wget时的当前路径 ,我wget时是在/etc/ceph路径下的。
vi /etc/ceph/rbdmap# RbdDevice Parameters#poolname/imagename id=client,keyring=/etc/ceph/ceph.client.keyring
rbds_pool/iscsi-image id=client,keyring=/etc/ceph/ceph.client.admin.keyring
如果使用了cephx那么,keyring=/etc/ceph/ceph.client.admin.keyring就要加上了
3.5 配置ISCSI-target
Linux SCSI target framework (tgt)用来将 Linux 系统仿真成为 iSCSI target 的功能;安装tgt,并检查是否支持rbd:
#wget http://ceph.com/packages/ceph-extras/rpm/centos6/x86_64/scsi-target-utils-1.0.38-48.bf6981.ceph.el6.x86_64.rpm
#rpm -ivh scsi-target-utils-1.0.38-48.bf6981.ceph.el6.x86_64.rpm
在这里一开始的时候是直接yum安装的:yum install -y iscsi-initiator-utils 安装之后发现使用下面的命令后,安装的是scsi-target-utils-1.0.55版本,不支持rbd,然后又用这种方式进行rpm包安装1.0.38版本后支持rbd。
#tgtadm --lld iscsi --op show --mode system | grep rbd
rbd (bsoflags sync:direct)#返回这个信息表明支持rbd
文件的了解:
/etc/tgt/targets.conf:主要配置文件,设定要分享的磁盘格式与哪几颗;
/usr/sbin/tgt-admin:在线查询、删除 target 等功能的设定工具;
/usr/sbin/tgt-setup-lun:建立 target 以及设定分享的磁盘与可使用的客户端等工具软件。
/usr/sbin/tgtadm:手动直接管理的管理员工具 (可使用配置文件取代);
/usr/sbin/tgtd:主要提供 iSCSI target 服务的主程序;
/usr/sbin/tgtimg:建置预计分享的映像文件装置的工具 (以映像文件仿真磁盘);
SCSI 有一套自己分享 target 档名的定义,基本上,藉由 iSCSI 分享出来的 target 檔名都是以 iqn 为开头,意思是:『iSCSI Qualified Name (iSCSI 合格名称)』的意思。那么在 iqn 后面要接啥档名呢?通常是这样的:
iqn.yyyy-mm.:identifier
单位网域名的反转写法 :这个分享的target名称
比如:target iqn.2015-9.localhost:iscsi 在接下看的配置中会用到
我们主要是修改 /etc/tgt/targets.conf,把创建好的RBD信息添加进去。
vim /etc/tgt/targets.conf
此档案的语法如下:
后端存储类型 – 默认 rdwr, 可选 aio, 等…在这里选rbd
backing-store rbd/ceph-rbd1
# <==LUN 1 (LUN 的编号通常照顺 序)Format is /
然后点击此电脑——》管理
最后就可以看见这个块设备了,刚开始的时候这个盘显示的是未分配的状态,我们只需要格式化(右键然后点击新建卷)就ok了。
3.7 linux客户端挂载
本次主要针对的windows客户端挂载,成功的挂载说明服务器端是没有问题的,如果要在linux上进行挂载,只需要安装iSCSI initiator然后进行简单的配置。
Linux客户端配置:
-
配置拓展源安装iscsi-initiator-utils
apt-get install iscsi-initiator-utils -
发现目标设备
sudo iscsiadm -m discovery -t sendtargets -p 192.168.1.220
3.登陆目标设备,然后挂载
$ sudo iscsiadm -m node -T iqn.2018-3.localhost:iscsi -p 192.168.1.220 -l
成功之后就可以fdisk -l发现了
lxl@lxl-virtual-machine:~$ sudo fdisk -l
Disk /dev/sda: 20 GiB, 21474836480 bytes, 41943040 sectors
…省略…
Disk /dev/sdd: 4 GiB, 4294967296 bytes, 8388608 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 4194304 bytes
I/O size (minimum/optimal): 4194304 bytes / 4194304 bytes
Disklabel type: dos
Disk identifier: 0x69ebb11c
Device Boot Start End Sectors Size Id Type
/dev/sdd1 8192 8380415 8372224 4G 7 HPFS/NTFS/exFAT
然后新建/mnt/rbd_iscsi目录,使用命令sudo mount /dev/sdd1 /mnt/rbd_iscsi就可以了。
查看一下:
lxl@lxl-virtual-machine:~$ sudo mount | grep sdd1
/dev/sdd1 on /mnt/rbd_iscsi type fuseblk (rw,relatime,user_id=0,group_id=0,allow_other,blksize=4096)
卸载目标设备:
首先sudo umount /dev/sdd1 /mnt/rbd_iscsi
然后再使用命令:
sudo iscsiadm -m node -T iqn.2018-3.localhost:iscsi -p 192.168.1.220 -u
以上就是windows【win10】和linux【ubuntu17.04】通过ISCSI-target把创建的RBD挂载使用的全过程。