CDH安装Kylin2.0及操作
-
- CDH安装Kylin2.0及操作
第一步,安装
1,安装包准备
最新安装包版本为2.0,下载链接如下:http://kylin.apache.org/download/
下载内容为apache-kylin-2.0.0-bin-cdh57.tar.gz,见下图:

2,安装
通过xftp上传下载的安装包apache-kylin-2.0.0-bin-cdh57.tar.gz到CDH集群的Region Server节点
默认上传到/opt/kylin目录下,如果目录不存在则执行命令创建目录mkdir -p /opt/kylin
在xshell中跳转到新创建的目录cd /opt/kylin
在目录内执行命令解压安装包,tar -xvf apache-kylin-2.0.0-bin-cdh57.tar.gz
解压后文件目录如下:
其中bin目录为sh脚本存放目录
conf目录为配置文件存放目录
lib为类库存放目录
tomcat为kylin Web应用(图形化控制台)的存放目录
logs为日志存放目录
3,初始化kafka类库
上传kafka-clients-0.10.0-kafka-2.1.0.jar到lib目录下
第二步,配置
1,配置环境变量
在安装kylin的主机上修改环境变量并使之生效
执行命令并添加如下内容vi /etc/profile
#Kylin
export KYLIN_HOME=/opt/Kylin/apache-kylin-2.0.0-bin
#Hadoop
export HBASE_HOME=/opt/cloudera/parcels/CDH-5.10.0-1.cdh5.10.0.p0.41/lib/hbase
export HADOOP_HOME=/opt/cloudera/parcels/CDH-5.10.0-1.cdh5.10.0.p0.41/
export HIVE_HOME=/opt/cloudera/parcels/CDH-5.10.0-1.cdh5.10.0.p0.41/lib/hive
export HADOOP_CMD=/opt/cloudera/parcels/CDH-5.10.0-1.cdh5.10.0.p0.41/lib/hadoop/bin/hadoop
export HCAT_HOME=/opt/cloudera/parcels/CDH-5.10.0-1.cdh5.10.0.p0.41/lib/hive-hcatalog
见下图,红框内为新增加内容

执行source /etc/profile使环境变量生效,输入echo $KYLIN_HOME检查变量是否生效
2,配置kylin.properties
1,跳转到kylin的conf目录,修改kylin.properties文件,在文件末尾追加如下内容:
kylin.engine.mr.lib-dir=/opt/cloudera/parcels/CDH-5.10.0-1.cdh5.10.0.p0.41/lib/sentry/lib
kylin.rest.servers=n10.worker.com:7070
kylin.job.jar=/opt/kylin/apache-kylin-2.0.0-bin/lib/kylin-job-2.0.0.jar
kylin.coprocessor.local.jar=/opt/kylin/apache-kylin-2.0.0-bin/lib/kylin-coprocessor-2.0.0.jar
其中kylin.rest.servers为kylin安装服务器主机名和端口号
2,去掉kylin.env.hadoop-conf-dir配置项前面的#注释
如下所示
# Hadoop conf folder, will export this as "HADOOP_CONF_DIR" to run spark-submit
# This must contain site xmls of core, yarn, hive, and hbase in one folder
kylin.env.hadoop-conf-dir=/etc/hadoop/conf
3,配置spark运行参数
根据当地集群情况,配置使用内存,使用虚拟核心和执行实例数。
kylin.engine.spark-conf.spark.executor.memory=1G #executor的分配内存大小
kylin.engine.spark-conf.spark.executor.cores=2 #executor的核心数
kylin.engine.spark-conf.spark.executor.instances=1 #执行executor的实例数
4,配置Mapreduce参数
kylin.engine.mr.reduce-input-mb=500 # reduce容器的内存大小
kylin.engine.mr.max-reducer-number=500 #最大reduce数量
kylin.engine.mr.mapper-input-rows=1000000 #输入数据行数
3,配置hive,hbase配置文件
上一步中kylin.env.hadoop-conf-dir配置的目录为hive,hbase等文件的配置目录,目录中至少包含如下图所示文件:(注,有些文件原先已经存在)
![]()
如果hive-site.xml,hbase-site.xml不存在,需要在其他节点拷贝相应文件过来,下面是这两个文件的样板文件
hive-site.xml配置:
hbase-site.xml配置:
拷贝过来的文件请检查配置项中针对zookeeper的配置是否正确,如果不正确请予以修正
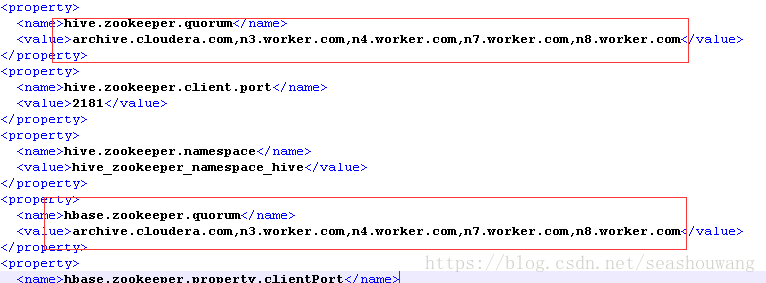
4,配置相关
如果集群中不存在hive组件,请先安装hive服务,安装hive之前需要在内置的postgresql数据库中添加hive数据库,或者安装MySQL,在安装hive服务过程中配置安装的MySQL数据库。
安装完毕hive服务,会在安装hive的节点上找到hive-site.xml文件,拷贝到kylin安装节点上即可。
第三步,kylin使用
1,kylin服务启动与停止
1,kylin启动
跳转到安装目录的bin目录下,执行命令./kylin.sh start启动kylin服务。
在启动过程中会检查hive和hbase的依赖,如果配置丢失或环境变量配置出错,会在启动过程中出现错误信息,请重新执行第二步的配置过程后重试。
2,kylin服务停止
同样的,使用命令./kylin.sh stop可以停止kylin服务
注:在修改kylin.properties或其他相关配置时,需要重启kylin才能使配置生效
2,kylin登录
输入http://{kylin安装主机名}:7070/kylin,在界面中输入用户名ADMIN,密码KYLIN登录kylin。

登录kylin后,在下图中点击+加号,添加一个Project
3,kylin日志查看
在xshell中输入tail -f logs/kylin.log命令查看kylin运行日志,logs/kylin.log文件为kylin主程序日志。
另外,logs/kylin.out为tomcat运行日志
第四步,模型及Cube处理
1,kafka流处理table创建
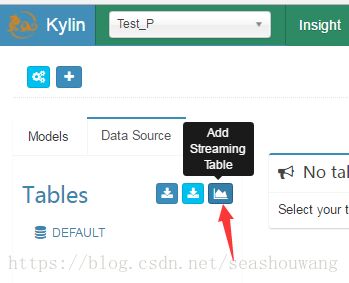
在kylin主界面选择创建的project,如下图中的Test_P
1,在主界面找到下图所示Add Streaming Table按钮,依次点击Data Source标签->Add Streaming Table按钮
2,使用下面的json字符串创建Table
{"Type":0,"RealCode":"RealCode","ServiceType":0,"DeviceType":0,"PlateNum":"PlateNum","ProtoType":0,"RouteType":0,"GroupAccount":"GroupAccount","Time":1497152123000,"FileType":0,"AuthType":"AuthType","AccessSystemID":1138067013,"RealType":0,"CyberCode":"CyberCode","IMSI":"IMSI","RESOURCETYPE":33,"ManufacturerCode":"723005104","SystemType":"145","DATASOURCEID":1701480372,"InterfaceID":3,"AreaCode":"371082","TerminalMac":"TerminalMac","MachineCode":"72300510494885E24008C","IMEI":"IMEI","InterfaceGroupID":4,"UnitCode":"37108235180040","GuildID":"GuildID","RouteMac":"08:10:78:CA:E2:0F"}
3,如下图所示步骤创建Streaming表,1,粘贴上面的json到窗口左侧,2,点击中间的》按钮,自动出现Table的column列表,3,填入Table Name表名,如T_kafka
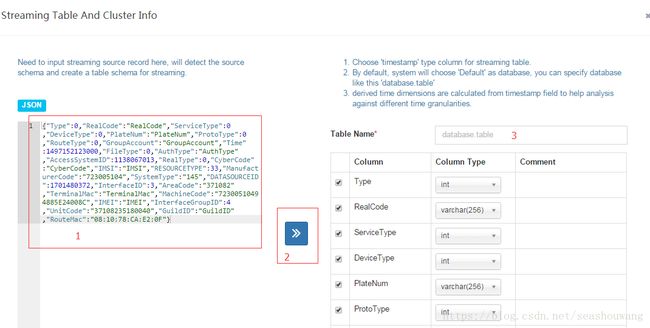
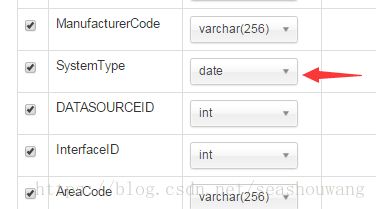
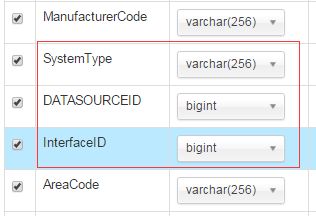
4,修改Column列表中int列类型为bigint(关键),修改SystemType为varchar(256)
修改后如下:
5,输入table name表名后点击窗口下方next按钮
![]()
在新的界面中录入kafka的Topic,如kylin
在下方维护集群的kafka broker信息,端口号为9092
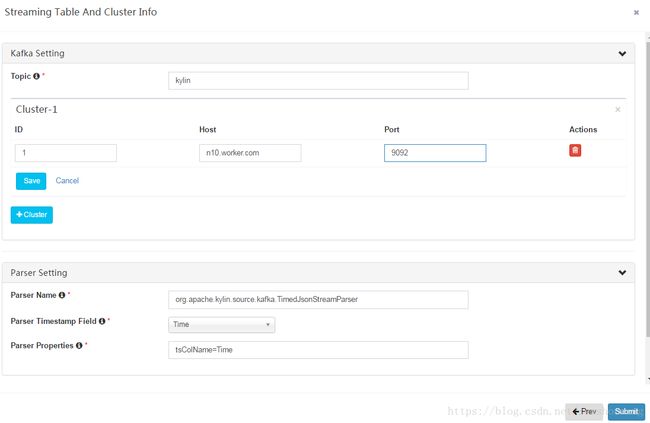
点击Kafka Setting下面的save按钮保存kafka配置信息,点击右下角Submit按钮保存Streaming Table
2,模型创建
1,在kylin主界面选择Models标签页,点击+New按钮,出现下拉列表,选择New Model按钮,如下图所示
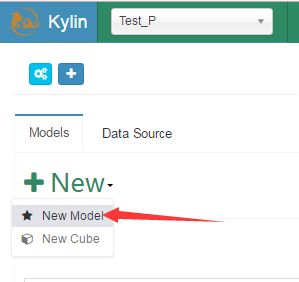
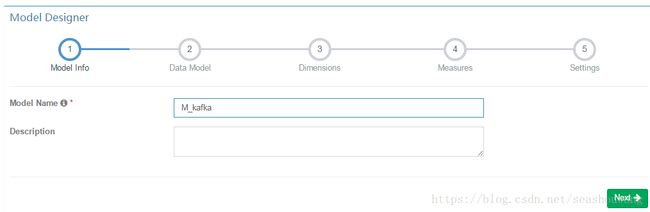
2,输入模型名称(如m_kafka)点击Next
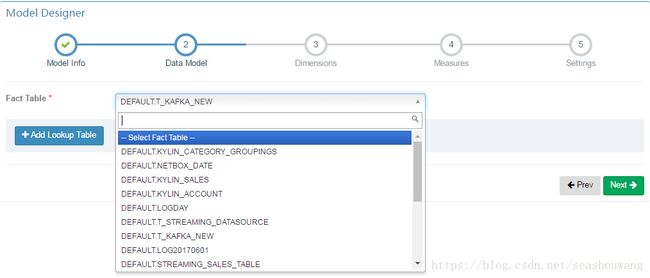
3,在Fact Table的下拉列表中选择刚刚创建的T_kafka Streaming Table,点击Next
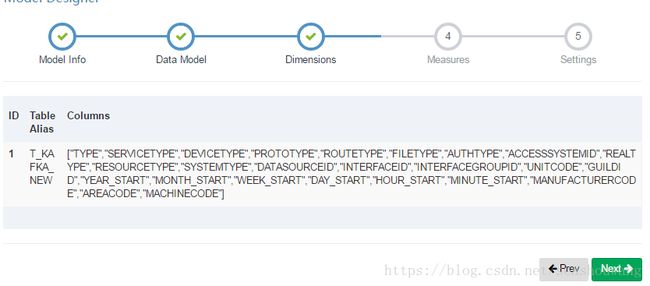
4,在维度Dimensions选择中添加维度列,如下图所示,点击Next
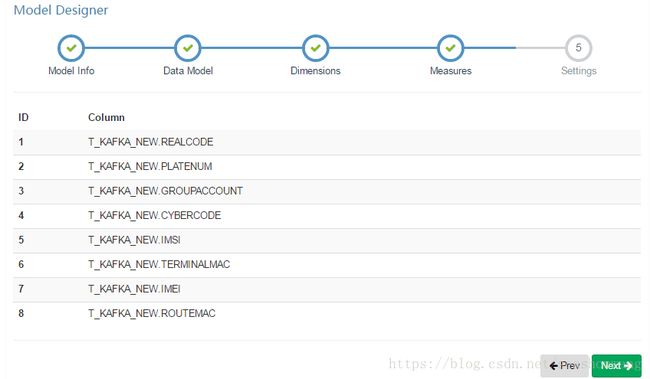
5,在度量列选择界面选择度量列如下所示,点击Next
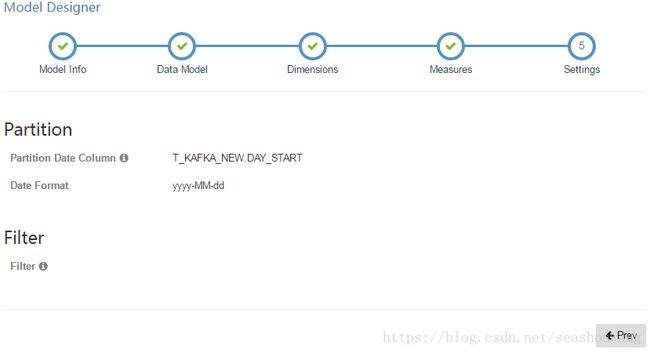
6,在Setting中选择Partition列为DAY_START,选择日期格式为yyyy-MM-dd,如果选择日期列为小时,分钟等,需要选择日期时间格式,如yyyy-MM-dd HH:MM:SS
7,点击Submit按钮保存新建的模型
3,Cube创建与构建
1,在kylin主界面选择Models标签页,点击+New按钮,出现下拉列表,选择New Cube按钮,如下图所示
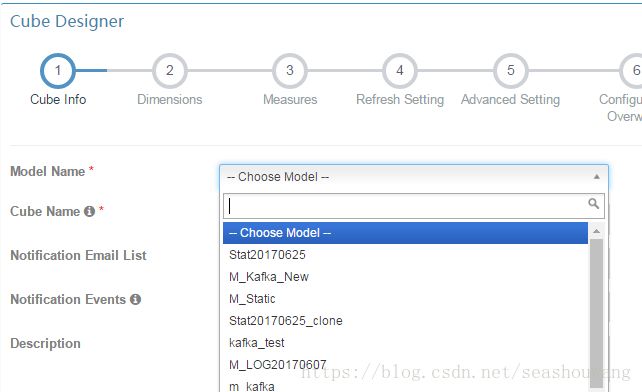
2,在模型名称Model Name下拉列表中选择刚刚创建的模型,如下图
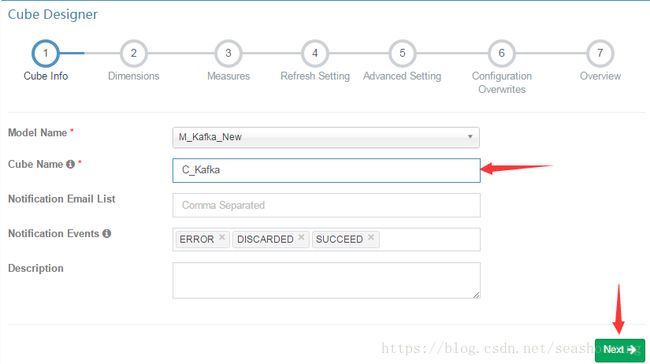
2,输入Cube Name,如C_kafka,点Next
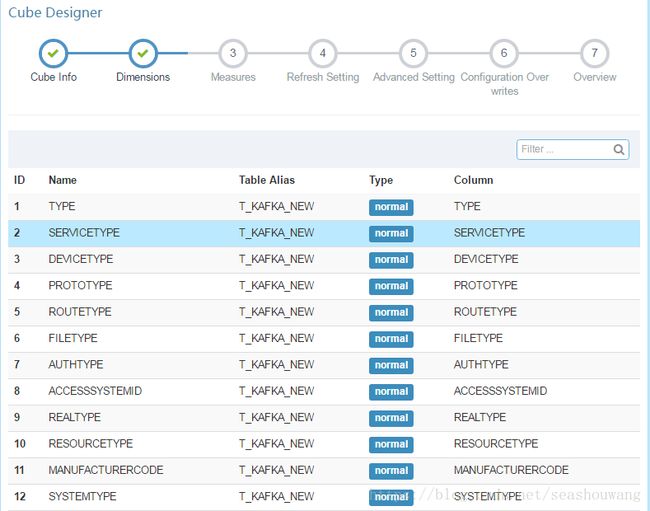
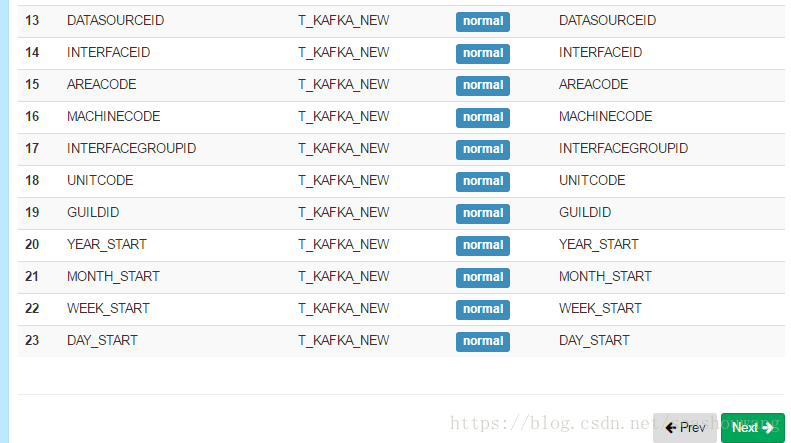
3,选择维度,最终选择如下图所示列,点击Next
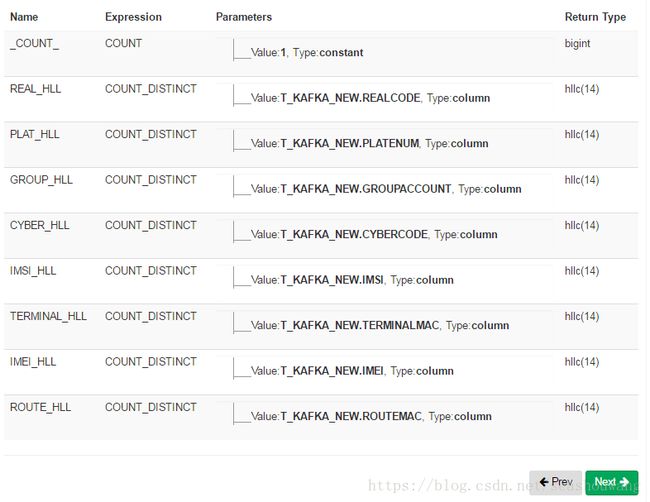
4,创建度量如下图所示,点Next
其中单个度量选择及配置如下图所示:
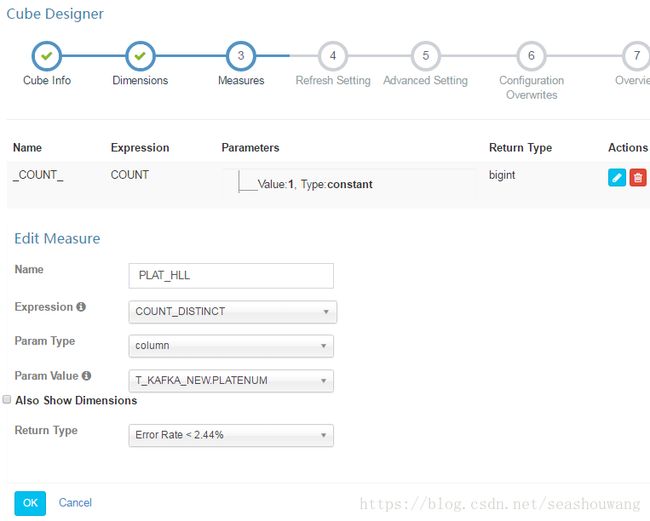
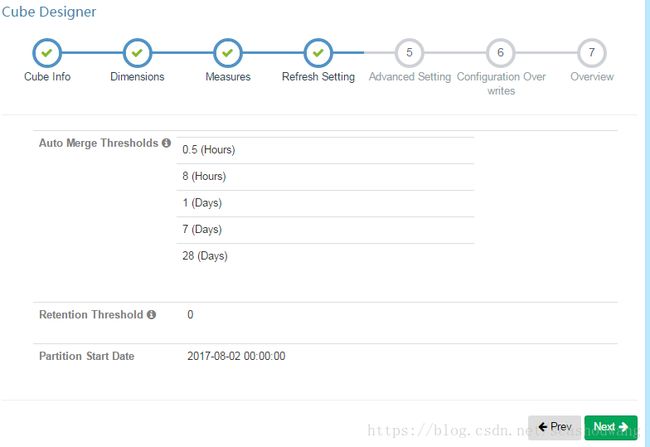
5,刷新日期设置成如下图所示,有0.5小时,8小时,1天,7天,28天,Partition Start Date选择当天时间的零点,点Next
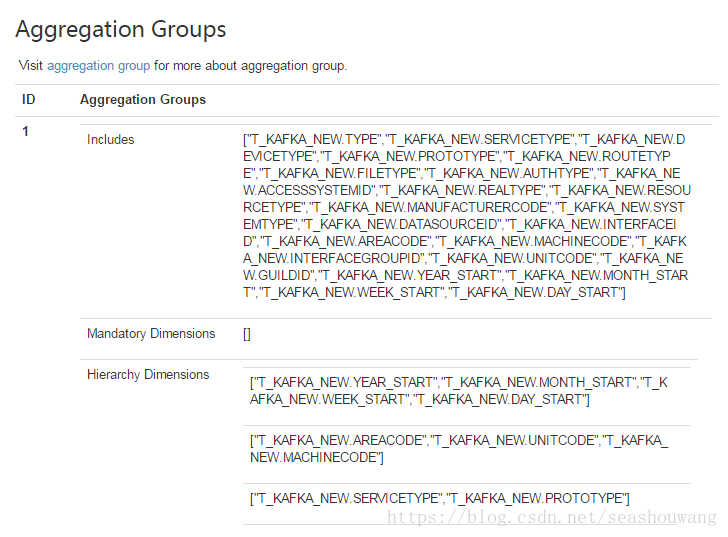
6,配置高级设置Advanced Setting中的统计组如下图所示,其他使用界面默认值,Kube Engine选择MapReduce,不可选择Spark,目前2.0版本kylin不支持Spark构建kafka流数据。点Next

7,Configuration Over writes之间点Next

8,在Overview界面查看配置信息是否正确,点Submit保存新增的Cube
4,Cube构建与SQL查询验证
1,Cube构建
Cube在创建成果后会在Model模型界面列表中显示出来,如下图所示:
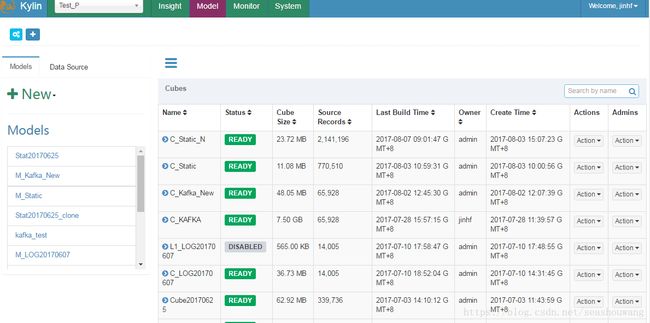
找到刚刚创建的Cube,在Actions列中点开动作列表,选择build,执行build

2,build过程监控
选择窗口最上方的Montor标签,最新build的任务会以列表的形式显示
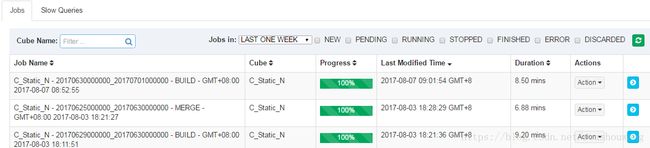
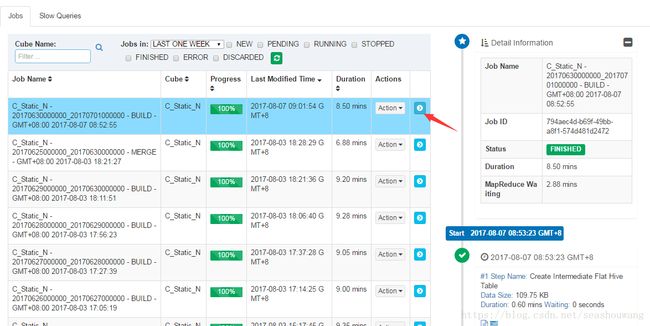
查看具体job的步骤详情,可以点击最后一列的》按钮
3,SQL查询验证
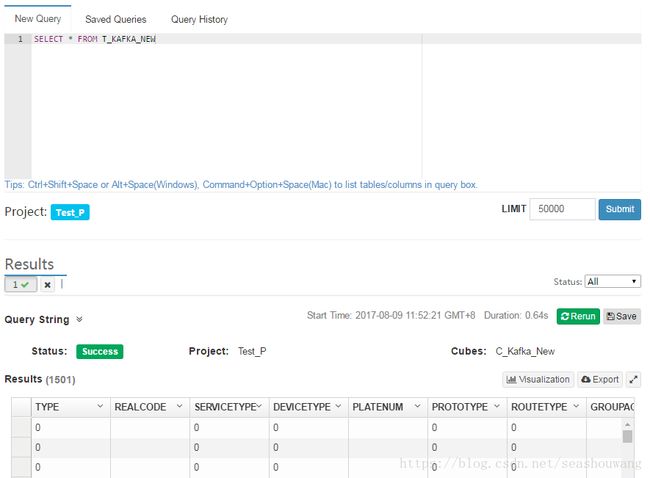
选择窗口最上方的Insight标签,输入SQL语句查询上面步骤创建的Streaming Table,点击Submit执行SQL,如下图
查询结果如下图所示,如果查询正常,cube验证完成。