Spring Cloud Sleuth链路跟踪之使用Mysq保存服务链路跟踪信息
不知不觉已经写链路追踪到第三篇文章了,结合官方文档看了一下追踪信息,最好是保存到数据库中,不然服务重启后,追踪的信息都没有了,所以今天我们就看看,如何把数据写入到mysql数据库中。
一、简介
上一篇文章已经实现了通过RabbitMQ消息中间件的方式来收集服务链路跟踪信息,但是当zipkin-server服务端重启之后,你会发现之前的链路信息都清空了,通过zipkin可视化界面已经不能看到服务之间的调用关系以及服务依赖关系了,这个时候我们就需要考虑将服务链路信息进行持久化,通常都是保存在数据库或者搜索引擎如ES中,本文将实现将服务链路跟踪信息保存在Mysql数据库中,从而实现链路信息的持久化。
二、修改zipkin-server
将链路信息保存数据库,主要改动是在zipkin-server服务端。
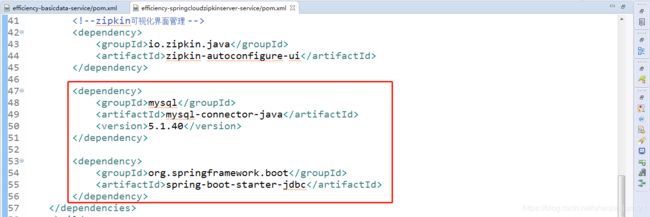
【a】在zipkin-server的pom.xml中添加依赖,mysql数据库依赖,主要添加mysql-connector-java、spring-boot-starter-jdbc等jar包
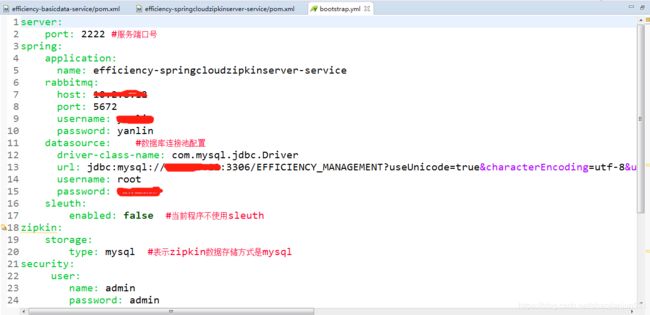
【b】application.yml中添加数据库配置、zipkin保存方式等信息,具体配置文件如下
【c】在数据库中创建存储链路信息的相关表,主要有:
zipkin_spans、zipkin_annotations、zipkin_dependencies三张表,具体sql:
CREATE TABLE IF NOT EXISTS zipkin_spans (
`trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit',
`trace_id` BIGINT NOT NULL,
`id` BIGINT NOT NULL,
`name` VARCHAR(255) NOT NULL,
`parent_id` BIGINT,
`debug` BIT(1),
`start_ts` BIGINT COMMENT 'Span.timestamp(): epoch micros used for endTs query and to implement TTL',
`duration` BIGINT COMMENT 'Span.duration(): micros used for minDuration and maxDuration query'
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
ALTER TABLE zipkin_spans ADD UNIQUE KEY(`trace_id_high`, `trace_id`, `id`) COMMENT 'ignore insert on duplicate';
ALTER TABLE zipkin_spans ADD INDEX(`trace_id_high`, `trace_id`, `id`) COMMENT 'for joining with zipkin_annotations';
ALTER TABLE zipkin_spans ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'for getTracesByIds';
ALTER TABLE zipkin_spans ADD INDEX(`name`) COMMENT 'for getTraces and getSpanNames';
ALTER TABLE zipkin_spans ADD INDEX(`start_ts`) COMMENT 'for getTraces ordering and range';
CREATE TABLE IF NOT EXISTS zipkin_annotations (
`trace_id_high` BIGINT NOT NULL DEFAULT 0 COMMENT 'If non zero, this means the trace uses 128 bit traceIds instead of 64 bit',
`trace_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.trace_id',
`span_id` BIGINT NOT NULL COMMENT 'coincides with zipkin_spans.id',
`a_key` VARCHAR(255) NOT NULL COMMENT 'BinaryAnnotation.key or Annotation.value if type == -1',
`a_value` BLOB COMMENT 'BinaryAnnotation.value(), which must be smaller than 64KB',
`a_type` INT NOT NULL COMMENT 'BinaryAnnotation.type() or -1 if Annotation',
`a_timestamp` BIGINT COMMENT 'Used to implement TTL; Annotation.timestamp or zipkin_spans.timestamp',
`endpoint_ipv4` INT COMMENT 'Null when Binary/Annotation.endpoint is null',
`endpoint_ipv6` BINARY(16) COMMENT 'Null when Binary/Annotation.endpoint is null, or no IPv6 address',
`endpoint_port` SMALLINT COMMENT 'Null when Binary/Annotation.endpoint is null',
`endpoint_service_name` VARCHAR(255) COMMENT 'Null when Binary/Annotation.endpoint is null'
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
ALTER TABLE zipkin_annotations ADD UNIQUE KEY(`trace_id_high`, `trace_id`, `span_id`, `a_key`, `a_timestamp`) COMMENT 'Ignore insert on duplicate';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`, `span_id`) COMMENT 'for joining with zipkin_spans';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id_high`, `trace_id`) COMMENT 'for getTraces/ByIds';
ALTER TABLE zipkin_annotations ADD INDEX(`endpoint_service_name`) COMMENT 'for getTraces and getServiceNames';
ALTER TABLE zipkin_annotations ADD INDEX(`a_type`) COMMENT 'for getTraces';
ALTER TABLE zipkin_annotations ADD INDEX(`a_key`) COMMENT 'for getTraces';
ALTER TABLE zipkin_annotations ADD INDEX(`trace_id`, `span_id`, `a_key`) COMMENT 'for dependencies job';
CREATE TABLE IF NOT EXISTS zipkin_dependencies (
`day` DATE NOT NULL,
`parent` VARCHAR(255) NOT NULL,
`child` VARCHAR(255) NOT NULL,
`call_count` BIGINT,
`error_count` BIGINT
) ENGINE=InnoDB ROW_FORMAT=COMPRESSED CHARACTER SET=utf8 COLLATE utf8_general_ci;
ALTER TABLE zipkin_dependencies ADD UNIQUE KEY(`day`, `parent`, `child`);
通过改动zipkin server,这样就可以实现mysql存储链路信息。
三、启动项目
依次启动项目,我们先访问http://10.2.8.42/effi/efficacy/basicdata/childdata/retrieve?id=1&dirType=2
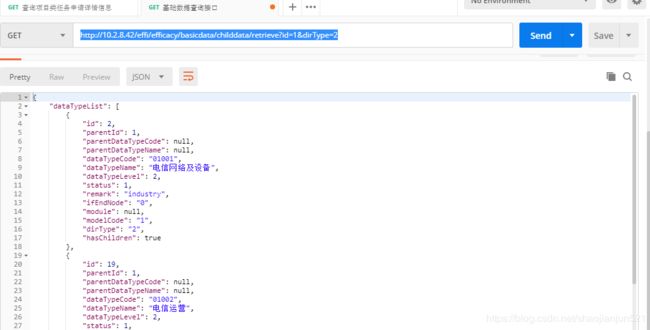
可以看到,接口调用成功,这时候我们再访问zipkin server可视化界面http://10.2.8.42:2222/,
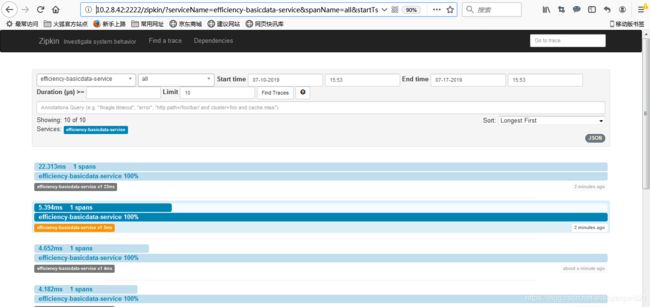
如图,可以看到rabbitMQ成功收集了服务链路信息。这时候我们查询数据库中相关表的数据,
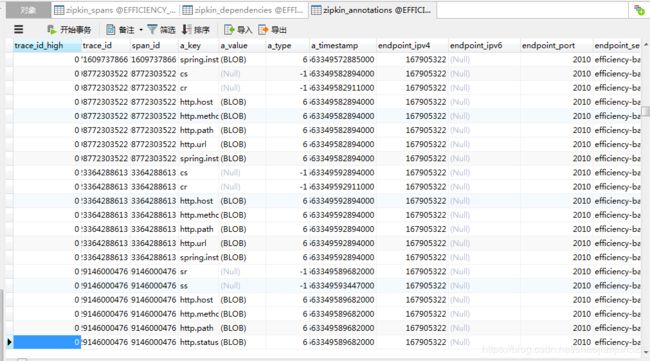
由图,我们已经实现了将链路信息持久化到数据库中。
四、总结
上面我们通过改造zipkin-server将服务链路跟踪信息保存到数据库中,当然,在实际项目中,也可以保存在搜索引擎(如ES中),
这需要根据具体项目规模以及项目需求来定,以上是作者在学习Spring Cloud Sleuth持久化链路信息的一些总结以及方法,仅供大家参考,一起学习一起进步!