【论文笔记】未分类_2016
20161201
【1】Chatfield K, Simonyan K, Vedaldi A, et al. Return of the Devil in the Details: Delving Deep into Convolutional Nets[J]. Computer Science, 2014.
这篇文章比较了几个深度网络模型以及传统特征提取方法在图片分类的结果。实验展示了数据扩展、特征归一化、维度改变等因素对最终模型性能的影响。同时也证明了在ILSVRC上训练的深度模型,在其它数据的分类上依然非常有效,倘若加上针对性的fine-tune会更有效。源代码链接
PS: 为了加强对深度学习的理解,最近开始读些早些时候的paper。
20161013
【1】Large-Margin Softmax Loss for Convolutional Neural Networks, Weiyang Liu, Yandong Wen, Zhiding Yu, Meng Yang,Proceedings of The 33rd International Conference on Machine Learning, pp. 507–516, 2016
Softmax 的 loss 函数经常在卷积神经网络被用到,较为简单实用,但是它并不能够明确引导网络学习区分性较高的特征。这篇文章提出了large-marin softmax (L-Softmax) loss, 能够有效地引导网络学习使得类内距离较小、类间距离较大的特征。同时,L-Softmax不但能够调节不同的间隔(margin),而且能够防止过拟合。可以使用随机梯度下降法推算出它的前向和后向反馈,实验证明L-Softmax学习出的特征更加有可区分性,并且在分类和验证任务上均取得比softmax更好的效果。
PS: 算法原理比较简单,实现也相对容易。论文交待的细节也比较详尽,最重要的是它仅用WebFace训练,就在LFW上取得了98.71%的验证准确率。确实值得学习下。
【1】Kemelmacher-Shlizerman I, Seitz S M. Collection flow[C]//Computer Vision and Pattern Recognition (CVPR), 2012 IEEE Conference on. IEEE, 2012: 1792-1799.
计算一对人脸图像 (I,J) 之间的光流,容易受到光照、姿态以及其它变化的影响。作者通过一批相同人脸的多张图片集,将待计算的人脸进行表情和姿态的规整,得到 I′ , J′ 。通过这四者的关系,得到更加精确的光流计算结果: (I→I′)∘(J′→J) .
PS: 我对光流算法不太了解,但是其中提到的表情和姿态的规整比较感兴趣。这种算法需要预先收集大量的与测试图片相同的人脸图片来作为规整的依据,应该可以放松条件,找到相似人脸图片即可(Wang W, Cui Z, Yan Y, et al. Recurrent Face Aging[J] 这篇文章进一步发展了这样的规整方法)。

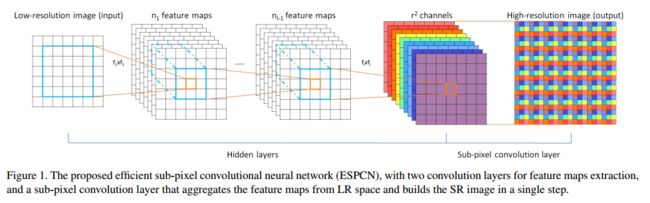
【2】Shi W, Caballero J, Huszár F, et al. Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2016: 1874-1883.
本篇文章了提出了一种新型的CNN框架,用于实现在低分辨率的图像上提取特征并进行超分辨处理。而之前的超分辨方法需将低分辨率图像上采样至高分辨率图像的尺寸,再使用滤波器进行双线性插值,这种方式容易陷入局部最优且计算量较大。本篇文章提出了一种叫做 sub-pixel convolution layer,它可以学习一组而不是一个上采样滤波器,从低分辨率的特征图得到高分辨率图像。这种方法既取得比之前方法更好的效果,处理速度也比之前基于CNN的超分辨率方法更快。