自然语言处理(NLP): 12 BERT文本分类
文章目录
- BERT介绍
- BERT 论文阅读
- BERT用做特征提取
- BERT 源码分析
- BERT升级版
- RoBERTa:更强大的BERT
- ALBERT:参数更少的BERT
- DistilBERT:轻量版BERT
- 电影评论情感分析
- 代码实现
- 训练过程
- 新闻文本分类
- BERT预训练的中文模型和词典
- 代码实现
- 训练过程
- 在线服务预测
BERT介绍
BERT 论文阅读
来自论文《https://arxiv.org/pdf/1810.04805.pdf》
BERT说:“我要用 transformer 的 encoders”
Ernie不屑道:“呵呵,你不能像Bi-Lstm一样考虑文章”
BERT自信回答道:“我们会用masks”
解释一下Mask:
语言模型会根据前面单词来预测下一个单词,但是self-attention的注意力只会放在自己身上,那么这样100%预测到自己,毫无意义,所以用Mask,把需要预测的词给挡住。
如下图:

BERT 数据数据表示如图所示:
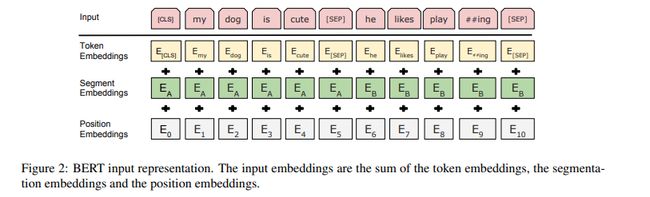
BERT的论文为我们介绍了几种BERT可以处理的NLP任务:
- 短文本相似
- 文本分类
- QA机器人
- 语义标注

BERT用做特征提取
微调方法并不是使用BERT的唯一方法,就像ELMo一样,你可以使用预选训练好的BERT来创建语境化词嵌入。然后你可以将这些嵌入提供给现有的模型。

哪个向量最适合作为上下文嵌入? 我认为这取决于任务。 本文考察了六种选择(与微调模型相比,得分为96.4):
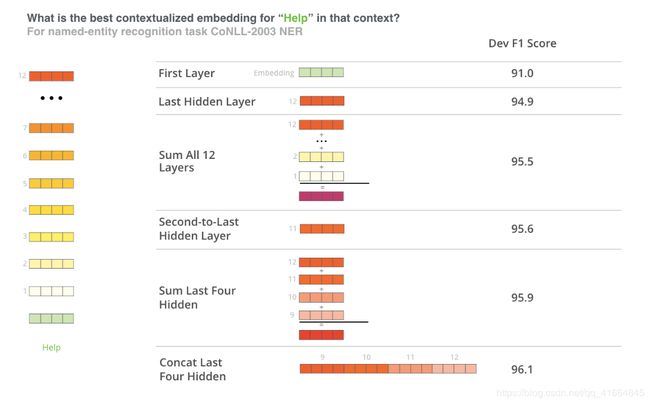
- Feature Extraction:特征提取
- Finetune:微调
BERT 源码分析
BERT是Transformer的一部分. Transformer本质是filter size为1的CNN. BERT比较适合几百个单词的情况,文章太长不太行。从github 上下载transformers 实现bert 预训练模型处理和文本分类的案例。
https://github.com/huggingface/transformers
重点关注几个重要的文件
- rule_gule.py 是一个文本分类实现的案例
- optimization.py 提供了AdamW 梯度更新算法
- modeling_bert.py 是HuggingFace提供的一个基于PyTorch实现的BERT 模型
pytorch_model.bin : 预训练的模型
vocab.txt :词典文件
config.json: bert 配置文件,主要bert 的定义的参数
英文预训练模型:
https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-uncased-pytorch_model.bin
https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-uncased-vocab.txt
https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-uncased-config.json
中文预训练模型:
https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-chinese-pytorch_model.bin
https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-chinese-vocab.txt
https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-chinese-config.json
- tokenization_bert.py 加载vocab.txt 词典文件,提供数据预处理方法,默认加载vocab.txt 文件名,可以详细查看代码
- 从本地加载词典和模型方法
我们首先把相关文件放到 bert_pretrain 目录下
bert_pretrain$ tree -a
├── config.json
├── pytorch_model.bin
└── vocab.txt
from transformers import BertTokenizer, BertForSequenceClassification
bert_path = './bert_pretrain/'
tokenizer = BertTokenizer.from_pretrained( os.path.join(bert_path, 'vocab.txt') )
model = BertForSequenceClassification.from_pretrained(
os.path.join(bert_path, 'pytorch_model.bin'),
config=os.path.join(bert_path, 'config.json'))
- 查看BERT仓库核心代码列表
可以查看BERT的PyTorch实现 (https://github.com/huggingface/transformers)。
modeling: https://github.com/huggingface/transformers/blob/master/src/transformers/modeling_bert.py
BertEmbedding: wordpiece embedding + position embedding + token type embedding
BertSelfAttnetion: query, key, value的变换
BertSelfOutput:
BertIntermediate
BertOutput
BertForSequenceClassification
configuration: https://github.com/huggingface/transformers/blob/master/transformers/configuration_bert.py
tokenization: https://github.com/huggingface/transformers/blob/master/transformers/tokenization_bert.py
DataProcessor: https://github.com/huggingface/transformers/blob/master/transformers/data/processors/glue.py#L194
BERT升级版
RoBERTa:更强大的BERT
论文地址:https://arxiv.org/pdf/1907.11692.pdf
- 加大训练数据 16GB -> 160GB,更大的batch size,训练时间加长
- 不需要NSP Loss
- 使用更长的训练 Sequence
- Static vs. Dynamic Masking
- 模型训练成本在6万美金以上(估算)
ALBERT:参数更少的BERT
论文地址:https://arxiv.org/pdf/1909.11942.pdf
- 一个轻量级的BERT模型
- 核心思想:
- 共享层与层之间的参数 (减少模型参数)
- 增加单层向量维度
DistilBERT:轻量版BERT
https://arxiv.org/pdf/1910.01108.pdf
- MLM, NSP
- MLM: cross entropy loss: -\sum_{i=1}^k p_i log (q_i) = - log (q_{label})
- teacher (MLM) = distribution
- student: 学习distribution: -\sum_{i=1}^k p_teacher_i log (q_student_i)
Patient Distillation
https://arxiv.org/abs/1908.09355

电影评论情感分析
我们通过斯坦福大学电影评论数据集进行情感分析,验证BERT 在情感分析上效果。
代码实现
import argparse
import logging
import os
import random
import time
import numpy as np
import torch
import torch.nn as nn
from torch.utils.data import TensorDataset, DataLoader
from transformers import BertTokenizer, BertForSequenceClassification, AdamW
from transformers.data.processors.glue import glue_convert_examples_to_features as convert_examples_to_features
from transformers.data.processors.utils import DataProcessor, InputExample
logger = logging.getLogger(__name__)
# 初始化参数
parser = argparse.ArgumentParser()
args = parser.parse_args(args=[]) # 在jupyter notebook中,args不为空
args.data_dir = "./data/"
args.model_type = "bert"
args.task_name = "sst-2"
args.output_dir = "./outputs2/"
args.max_seq_length = 128
args.do_train = True
args.do_eval = True
args.warmup_steps = 0
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
args.device = device
args.seed = 1234
args.batch_size = 48
args.n_epochs=3
args.lr = 5e-5
print('args: ', args)
def set_seed(args):
random.seed(args.seed)
np.random.seed(args.seed)
torch.manual_seed(args.seed)
if torch.cuda.is_available() > 0:
torch.cuda.manual_seed_all(args.seed)
set_seed(args) # Added here for reproductibility
class Sst2Processor(DataProcessor):
"""Processor for the SST-2 data set (GLUE version)."""
def get_example_from_tensor_dict(self, tensor_dict):
"""See base class."""
return InputExample(
tensor_dict["idx"].numpy(),
tensor_dict["sentence"].numpy().decode("utf-8"),
None,
str(tensor_dict["label"].numpy()),
)
def get_train_examples(self, data_dir):
"""See base class."""
return self._create_examples(self._read_tsv(os.path.join(data_dir, "train.tsv")), "train")
def get_dev_examples(self, data_dir):
"""See base class."""
return self._create_examples(self._read_tsv(os.path.join(data_dir, "dev.tsv")), "dev")
def get_test_examples(self, data_dir):
"""See base class."""
return self._create_examples(self._read_tsv(os.path.join(data_dir, "test.tsv")), "test")
def get_labels(self):
"""See base class."""
return ["0", "1"]
def _create_examples(self, lines, set_type):
"""Creates examples for the training and dev/test sets."""
examples = []
for (i, line) in enumerate(lines):
if i == 0:
continue
guid = "%s-%s" % (set_type, i)
text_a = line[0]
label = line[1]
examples.append(InputExample(guid=guid, text_a=text_a, text_b=None, label=label))
return examples
def load_and_cache_examples(args, processor, tokenizer, set_type):
# Load data features from cache or dataset file
print("Creating features from dataset file at {}".format(args.data_dir))
label_list = processor.get_labels()
if set_type == 'train':
examples = (
processor.get_train_examples(args.data_dir)
)
if set_type == 'dev':
examples = (
processor.get_dev_examples(args.data_dir)
)
if set_type == 'test':
examples = (
processor.get_test_examples(args.data_dir)
)
features = convert_examples_to_features(
examples, # 原始数据
tokenizer, #
label_list=label_list,
max_length=args.max_seq_length, # 设置每个batch 最大句子长度
output_mode='classification', # 设置分类标记
pad_on_left=False, # 右侧进行padding
pad_token=tokenizer.convert_tokens_to_ids([tokenizer.pad_token])[0],
pad_token_segment_id=0, # bert 分类设置0
mask_padding_with_zero=True # the attention mask will be filled by ``1``
)
# Convert to Tensors and build dataset
all_input_ids = torch.tensor([f.input_ids for f in features], dtype=torch.long)
all_attention_mask = torch.tensor([f.attention_mask for f in features], dtype=torch.long)
all_token_type_ids = torch.tensor([f.token_type_ids for f in features], dtype=torch.long)
all_labels = torch.tensor([f.label for f in features], dtype=torch.long)
dataset = TensorDataset(all_input_ids, all_attention_mask, all_token_type_ids, all_labels)
return dataset
def epoch_time(start_time, end_time):
elapsed_time = end_time - start_time
elapsed_mins = int(elapsed_time / 60)
elapsed_secs = int(elapsed_time - (elapsed_mins * 60))
return elapsed_mins, elapsed_secs
def train(model, data_loader, criterion, optimizer):
epoch_acc = 0.
epoch_loss = 0.
total_batch = 0
model.train()
for batch in data_loader:
#
batch = tuple(t.to(device) for t in batch)
input_ids, attention_mask, token_type_ids, labels = batch
# 预测
outputs = model(input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids)[0]
# 计算loss和acc
loss = criterion(outputs, labels)
_, y = torch.max(outputs, dim=1)
acc = (y == labels).float().mean()
#
if total_batch % 100==0:
print('Iter_batch[{}/{}]:'.format(total_batch, len(data_loader)),
'Train Loss: ', "%.3f" % loss.item(), 'Train Acc:', "%.3f" % acc.item())
# 计算批次下总的acc和loss
epoch_acc += acc.item() # 当前批次准确率
epoch_loss += loss.item() # 当前批次loss
# 剃度下降
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
#scheduler.step() # Update learning rate schedule
model.zero_grad()
total_batch += 1
# break
return epoch_acc / len(data_loader), epoch_loss / len(data_loader)
def evaluate(model, data_loader, criterion):
epoch_acc = 0.
epoch_loss = 0.
model.eval()
with torch.no_grad():
for batch in data_loader:
#
batch = tuple(t.to(device) for t in batch)
input_ids, attention_mask, token_type_ids, labels = batch
# 预测
outputs = model(input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids)[0]
# 计算loss和acc
loss = criterion(outputs, labels)
_, y = torch.max(outputs, dim=1)
acc = (y == labels).float().mean()
# 计算批次下总的acc和loss
epoch_acc += acc.item() # 当前批次准确率
epoch_loss += loss.item() # 当前批次loss
return epoch_acc / len(data_loader), epoch_loss / len(data_loader)
def main():
# 1. 定义数据处理器
processor = Sst2Processor()
label_list = processor.get_labels()
num_labels = len(label_list)
print('label_list: ', label_list)
print('num_label: ', num_labels)
print('*' * 60)
# 2. 加载数据集
train_examples = processor.get_train_examples(args.data_dir)
dev_examples = processor.get_dev_examples(args.data_dir) # 每条记录封装InputExample 类实例对象
test_examples = processor.get_test_examples(args.data_dir) # 每条记录封装InputExample 类实例对象
print('训练集记录数:', len(train_examples))
print('验证集数据记录数:', len(dev_examples))
print('测试数据记录数:', len(test_examples))
print('训练数据数据举例:\n', train_examples[0])
print('验证集数据数据举例:\n', dev_examples[0])
print('测试集数据数据举例:\n', test_examples[0])
# 3.加载本地 词表 模型
bert_path = './bert_pretrain/'
tokenizer = BertTokenizer.from_pretrained( os.path.join(bert_path, 'vocab.txt') )
train_dataset = load_and_cache_examples(args, processor, tokenizer, 'train')
dev_dataset = load_and_cache_examples(args, processor, tokenizer, 'dev')
test_dataset = load_and_cache_examples(args, processor, tokenizer, 'test')
train_dataloader = DataLoader(train_dataset, batch_size=args.batch_size, shuffle=True)
dev_dataloader = DataLoader(dev_dataset, batch_size=args.batch_size, shuffle=False)
test_dataloader = DataLoader(test_dataset, batch_size=args.batch_size, shuffle=False)
# 4. 模型定义
model = BertForSequenceClassification.from_pretrained(
os.path.join(bert_path, 'pytorch_model.bin'),
config=os.path.join(bert_path, 'config.json'))
model.to(device)
N_EPOCHS = args.n_epochs
# 梯度更新算法AdamW
t_total = len(train_dataloader) // N_EPOCHS
no_decay = ["bias", "LayerNorm.weight"]
optimizer_grouped_parameters = [
{
"params": [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)],
"weight_decay": 0.0,
},
{"params": [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)], "weight_decay": 0.0},
]
optimizer = AdamW(optimizer_grouped_parameters, lr=args.lr,
correct_bias=False)
# loss_func
criterion = nn.CrossEntropyLoss()
# 5. 模型训练
print('模型训练开始: ')
logger.info("***** Running training *****")
logger.info(" train num examples = %d", len(train_dataloader))
logger.info(" dev num examples = %d", len(dev_dataloader))
logger.info(" test num examples = %d", len(test_dataloader))
logger.info(" Num Epochs = %d", args.n_epochs)
best_valid_loss = float('inf')
for epoch in range(N_EPOCHS):
start_time = time.time()
train_acc, train_loss = train(model, train_dataloader, criterion, optimizer)
val_acc, val_loss = evaluate(model, dev_dataloader, criterion)
end_time = time.time()
epoch_mins, epoch_secs = epoch_time(start_time, end_time)
if val_loss < best_valid_loss:
print('loss increasing->')
best_valid_loss = val_loss
torch.save(model.state_dict(), 'bert-model.pt')
print(f'Epoch: {epoch + 1:02} | Epoch Time: {epoch_mins}m {epoch_secs}s')
print(f'\tTrain Loss: {train_loss:.3f} | Train Acc: {train_acc * 100:.3f}%')
print(f'\t Val. Loss: {val_loss:.3f} | Val. Acc: {val_acc * 100:.3f}%')
# evaluate
model.load_state_dict(torch.load('bert-model.pt'))
test_acc, test_loss = evaluate(model, test_dataloader, criterion)
print(f'Test Loss: {test_loss:.3f} | Test Acc: {test_acc * 100:.2f}%')
if __name__ == '__main__':
main()
训练过程
python3 main.py
loss increasing->
Epoch: 01 | Epoch Time: 13m 38s
Train Loss: 0.293 | Train Acc: 88.791%
Val. Loss: 0.307 | Val. Acc: 88.600%
Epoch: 02 | Epoch Time: 13m 40s
Train Loss: 0.160 | Train Acc: 94.905%
Val. Loss: 0.336 | Val. Acc: 88.664%
Epoch: 03 | Epoch Time: 13m 40s
Train Loss: 0.127 | Train Acc: 96.367%
Val. Loss: 0.471 | Val. Acc: 88.935%
Test Loss: 0.289 | Test Acc: 89.57%
新闻文本分类
我们使用新闻的title 进行文本的分类,属于中文短文本分类业务,这里使用BERT提供的预训练中文模型进行,通过HuggingFace提供transformers 模型实现文本分类,最终的效果非常的不错。
BERT预训练的中文模型和词典
https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-chinese-pytorch_model.bin
https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-chinese-vocab.txt
https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-chinese-config.json
- 下载完成config.json 后,我们分别重命名文件
pytorch_model.bin : 预训练的模型
vocab.txt :词典文件
config.json: bert 配置文件,主要bert 的定义的参数
- 修改config.json ,设置分类个数,我们这里设置num_labels = 10 表示10个类别分类
{
"architectures": [
"BertForSequenceClassification"
],
"attention_probs_dropout_prob": 0.1,
"directionality": "bidi",
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"max_position_embeddings": 512,
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pooler_fc_size": 768,
"pooler_num_attention_heads": 12,
"pooler_num_fc_layers": 3,
"pooler_size_per_head": 128,
"pooler_type": "first_token_transform",
"type_vocab_size": 2,
"vocab_size": 21128,
"num_labels": 10
}
- 加载词典和模型方法
# 词典和BERT 预训练模型目录
bert_path = './bert_pretrain/'
# 加载词典: 默认当前目录下vocab.txt 文件
tokenizer = BertTokenizer.from_pretrained(bert_path)
# 初始化BERT 预训练的模型
model = BertForSequenceClassification.from_pretrained(
os.path.join(bert_path, 'pytorch_model.bin'),# 模型路径
config=os.path.join(bert_path, 'config.json')# BERT 配置文件
)
代码实现
- 自定义数据处理器NewsProcessor ,继承DataProcessor
参考bert 代码中rule_bert.py 实现
class NewsProcessor(DataProcessor):
"""Processor for the News-2 data set (GLUE version)."""
def get_train_examples(self, data_dir):
"""See base class."""
return self._create_examples(self._read_tsv(os.path.join(data_dir, "train.tsv")), "train")
def get_dev_examples(self, data_dir):
"""See base class."""
return self._create_examples(self._read_tsv(os.path.join(data_dir, "dev.tsv")), "dev")
def get_test_examples(self, data_dir):
"""See base class."""
return self._create_examples(self._read_tsv(os.path.join(data_dir, "test.tsv")), "test")
def get_labels(self):
"""See base class."""
return ["0", "1", "2", "3", "4", "5", "6", "7", "8", "9"]
def _create_examples(self, lines, set_type):
"""Creates examples for the training and dev/test sets."""
examples = []
for (i, line) in enumerate(lines):
guid = "%s-%s" % (set_type, i)
text_a = line[0]
label = line[1]
examples.append(InputExample(guid=guid, text_a=text_a, text_b=None, label=label))
return examples
def load_and_cache_examples(args, processor, tokenizer, set_type):
# Load data features from cache or dataset file
print("Creating features from dataset file at {}".format(args.data_dir))
if set_type == 'train':
examples = (
processor.get_train_examples(args.data_dir)
)
if set_type == 'dev':
examples = (
processor.get_dev_examples(args.data_dir)
)
if set_type == 'test':
examples = (
processor.get_test_examples(args.data_dir)
)
features = convert_examples_to_features(
processor,
examples, # 原始数据
tokenizer, #
max_length=args.max_seq_length, # 设置每个batch 最大句子长度
pad_token=tokenizer.convert_tokens_to_ids([tokenizer.pad_token])[0],
pad_token_segment_id=0, # bert 分类设置0
mask_padding_with_zero=True # the attention mask will be filled by ``1``
)
# Convert to Tensors and build dataset
all_input_ids = torch.tensor([f.input_ids for f in features], dtype=torch.long)
all_attention_mask = torch.tensor([f.attention_mask for f in features], dtype=torch.long)
all_token_type_ids = torch.tensor([f.token_type_ids for f in features], dtype=torch.long)
all_labels = torch.tensor([f.label for f in features], dtype=torch.long)
dataset = TensorDataset(all_input_ids, all_attention_mask, all_token_type_ids, all_labels)
return dataset
- 定义训练预测方法
def train(model, data_loader, criterion, optimizer):
epoch_acc = 0.
epoch_loss = 0.
total_batch = 0
model.train()
for batch in data_loader:
#
batch = tuple(t.to(device) for t in batch)
input_ids, attention_mask, token_type_ids, labels = batch
# 预测
outputs = model(input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids)[0]
# 计算loss和acc
loss = criterion(outputs, labels)
_, y = torch.max(outputs, dim=1)
acc = (y == labels).float().mean()
#
if total_batch % 100 == 0:
print('Iter_batch[{}/{}]:'.format(total_batch, len(data_loader)),
'Train Loss: ', "%.3f" % loss.item(), 'Train Acc:', "%.3f" % acc.item())
# 计算批次下总的acc和loss
epoch_acc += acc.item() # 当前批次准确率
epoch_loss += loss.item() # 当前批次loss
# 剃度下降
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
# scheduler.step() # Update learning rate schedule
model.zero_grad()
total_batch += 1
# break
return epoch_acc / len(data_loader), epoch_loss / len(data_loader)
def evaluate(model, data_loader, criterion):
epoch_acc = 0.
epoch_loss = 0.
model.eval()
with torch.no_grad():
for batch in data_loader:
#
batch = tuple(t.to(device) for t in batch)
input_ids, attention_mask, token_type_ids, labels = batch
# 预测
outputs = model(input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids)[0]
# 计算loss和acc
loss = criterion(outputs, labels)
_, y = torch.max(outputs, dim=1)
acc = (y == labels).float().mean()
# 计算批次下总的acc和loss
epoch_acc += acc.item() # 当前批次准确率
epoch_loss += loss.item() # 当前批次loss
return epoch_acc / len(data_loader), epoch_loss / len(data_loader)
核心代码定义后,我们就可以定义optimzier ,加载数据进行模型训练了,这里不在详述。
下面我们直接看下训练过程以及最终效果如何。
训练过程
python3 main.py
这里针对短文本分类,一般在24 个字左右,这里我们迭代3轮,我们发现效果还是非常不错的。
训练数据数据举例:
InputExample(guid='train-0', text_a='中华女子学院:本科层次仅1专业招男生', text_b=None, label='3')
验证集数据数据举例:
InputExample(guid='dev-0', text_a='体验2D巅峰 倚天屠龙记十大创新概览', text_b=None, label='8')
测试集数据数据举例:
InputExample(guid='test-0', text_a='词汇阅读是关键 08年考研暑期英语复习全指南', text_b=None, label='3')
loss increasing->
Epoch: 01 | Epoch Time: 7m 0s
Train Loss: 0.288 | Train Acc: 91.121%
Val. Loss: 0.206 | Val. Acc: 93.097%
loss increasing->
Epoch: 02 | Epoch Time: 7m 4s
Train Loss: 0.153 | Train Acc: 95.030%
Val. Loss: 0.200 | Val. Acc: 93.612%
Epoch: 03 | Epoch Time: 7m 5s
Train Loss: 0.109 | Train Acc: 96.385%
Val. Loss: 0.205 | Val. Acc: 93.661%
Test Loss: 0.201 | Test Acc: 93.72%
在线服务预测
- 加载模型以及字典
- 定义bert预测方法
with open('data/class.txt') as f:
items = [item.strip() for item in f.readlines()]
def predict(model,text):
tokens_pt2 = tokenizer.encode_plus(text, return_tensors="pt")
print(type(tokens_pt2))
input_ids = tokens_pt2['input_ids']
attention_mask = tokens_pt2['attention_mask']
token_type_ids = tokens_pt2['token_type_ids']
with torch.no_grad():
outputs = model(input_ids=input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids)[0]
_,y=torch.max(outputs,dim=1)
return y.item()
- 在线服务测试验证
text = "安徽2009年成人高考成绩查询系统"
y_pred = predict(model,text)
print('*'*60)
print('在线服务预测:')
print("{}->{}->{}".format( text,y_pred,items[y_pred]))
输出结果
安徽2009年成人高考成绩查询系统->3->教育