数据库架构设计一次搞定
学自:(沈剑,2019中国系统架构师大会)
一、前言
作为架构师,在数据库架构设计上,至少四个方面是需要系统性考虑的:
一、如何保证数据库的高可用
(1)读库高可用,如何保证?
(2)写库单点,如何消除?
(3)服务层,站点层,如何高可用?
二、如何提升数据库的读写性能
(1)索引为何会降低读性能?
(2)一主多从真的好么?
(3)数据库写入性能如何线性提升?
三、如何保证数据的一致性
(1)主从有延时,如何保证一致性?
(2)缓存与数据库,如何保证一致性?
四、如何保证数据库的扩展性
(1)表要增加一个属性,如何扩展?
(2)数据量又暴涨了,该怎么办?
(3)数据要迁移了,如何不停机?
(4)分库之后,跨库分页如何实现?
二、数据库工程架构,要设计些什么
任何脱离业务的架构设计,都是耍流氓:
1、依据“业务模式”设计库结构、表结构
2、依据“访问模式”设计索引结构
此外,数据库工程架构,还要设计些什么呢?
1、高可用
2、读性能
3、一致性
4、扩展性
三、基本概念
1、单库

创业公司初期都是单库,比如一个库里有300个表。
但后期一个库并不能很容易的拆成多个库,因为多个表有join操作,join操作不能跨库。
所以,单库在最初就要考虑后续的拆分问题。
2、复制(replication)与分组(group)
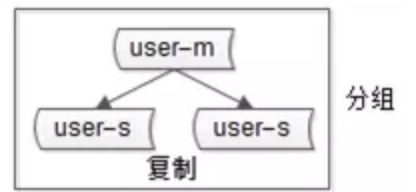
2.1、一主多从,解决了:
- 读性能扩展:通过加slave节点扩展
- 读高可用:通过slave节点数据冗余
2.2、一主多从带来的问题:
- 主从延迟
2.3、没有解决的问题:
- 主高可用
- 数据存储容量:原来只能存1T数据,分组后最多还是只能存1T
3、分片(sharding)

3.1、分片解决了:
- 存储容量扩容
- 读性能扩展
- 写性能扩容
3.2、分片带来的问题:
- SQL扩展的问题:如求Max无法跨“片”,从而牺牲了一些SQL特性。
3.3、分片没有解决:
- 高可用问题
- 会引发路由规则(router rule)问题
关于路由规则,常见的路由规则有:
1、范围路由:
Server1: 1 ~ 1亿
Server2: 1亿 ~ 2亿
Server3:…
问题:每台server的存储和访问的负载都不均衡
优点:扩展方便
2、hash(一致性hash,hashcode对n取模)
可解决:存储和访问的负载均衡
带来问题:迁移、扩展的问题。
实际上路由规则和业务是耦合的。
4、互联网数据量大场景,线上实际既有分组又有分片

5、垂直拆分
把表拆分成user_base和user_ext两类:
- user_base表:存储字段小,访问频度高的数据
- user_ext表:存储字段大,访问不频繁的数据
5.1、垂直拆分解决了:
- 提升读写性能:因为user_base表字段小,访问频度高,可充分使用DB buffer缓存(buffer:以行为单位,把磁盘数据提前加载到内存)
5.2、垂直拆分带来的问题:
- 原来只需要一个SQL,现在可能需要两个SQL
5.3、垂直拆分没有解决:
- 扩展性
四、高可用
1、怎样验证你的系统是否高可用呢?
去线上随便关一台机器,看对用户是否有影响。
理论上,对于要求高可用的系统,系统的每一层都需要高可用。
2、数据层怎样做到高可用呢?
2.1、redis怎样做到高可用?
Jedis会自动支持主从高可用:主挂了,会自动调用从。
2.2、数据库做到高可用的思路:复制+冗余
例如google CFS也是复制了3份文件
缓存的本质也是数据冗余。
数据层冗余会引发一致性问题
2.2.1、如何保证读库高可用?分组:读库冗余
读数据库时,数据库连接池会自动做到把请求发送给可用的读库。
2.2.2、如何保证写库高可用?双写:写库冗余
带来的问题:
- 一致性问题:如自增主键ID,双写时可能会重复。解决方案:一般是奇数,一遍是偶数;或由业务费来保证ID不重复
2.2.3、如何保证读写高可用?
读写都放在主库上,同时同步到从库,主库故障时从库顶上。这样读写一致性问题会得到缓解。
五、怎样提升数据库读性能
1、索引怎样用来提升读性能
1.1、索引是越多性能越好吗?
过多的索引会导致写性能降低、且索引占用内存大导致命中率低:因为数据库的内存缓存buffer是有限的,所以过多,导致内存buffer缓存不下,这样在查询索引数据时,仍需要读磁盘,从而导致性能下降
1.2、索引提升读性能最佳实践
对于一主二从的场景:
- master写库:不用建索引
- slave读库:需要建索引
2、提升读性能:增加从库
增加从库会带来什么问题?
- 从库越多,同步越慢
- 数据不一致
3、提升读性能:增加缓存
常见玩法:app–>service–>cache–>mysql-m–><–mysql s(m)
3.1、增加缓存会带来什么问题?
Cache Aside Pattern
Cache Aside Pattern最经典的缓存+数据库读写的模式。
术语标准解释:
- 如果应用程序更新信息,则可以通过对数据存储进行修改,并使缓存中的相应项目无效,从而遵循直写策略。
- 当下一个项目需要时,使用cache-aside策略将导致更新的数据从数据存储中检索并添加到高速缓存中。
术语白话解释:
- 读的时候,先读缓存,缓存没有的话,那么就读数据库,然后取出数据后放入缓存,同时返回响应
- 更新的时候,先删除缓存,然后再更新数据库
对于读请求:
- 先读cache, 再读DB
- 如果cache hit it, 直接返回
- 如果cache miss it, 则读取DB,并将数据set回缓存

如上图: - 先从cache中尝试get数据,结果miss了
- 再从db中读取数据,从库,读写分离
- 最后把数据set回cache,方便下次读命中
对于写请求
- 淘汰缓存,而不是更新缓存
- 先操作数据库,再淘汰缓存
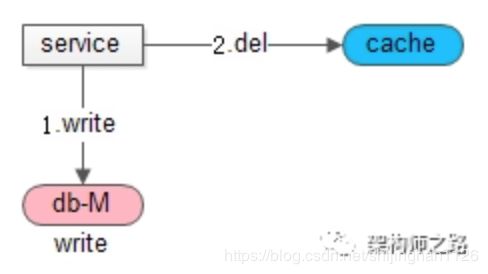
Cache Aside Pattern为什么建议淘汰缓存,而不是更新缓存?
如果更新缓存,在并发写时,可能出现数据不一致。
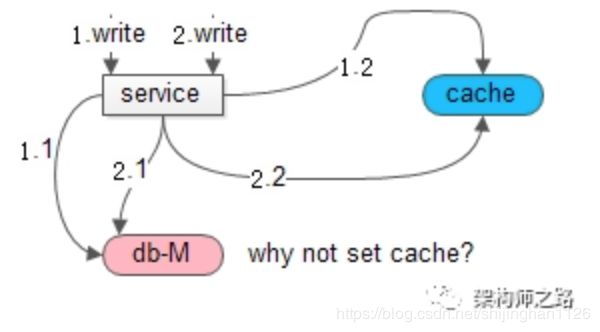
如上图所示,如果采用set缓存:
在1和2两个并发写发生时,由于无法保证时序,此时不管先操作缓存还是先操作数据库,都可能出现:
- 请求1先操作数据库,请求2后操作数据库
- 请求2先set了缓存,请求1后set了缓存
导致,数据库与缓存之间的数据不一致。
所以,Cache Aside Pattern建议,delete缓存,而不是set缓存。
为什么先写数据库,再淘汰缓存?

Cache Aside Pattern方案存在什么问题?
答:如果先操作数据库,再淘汰缓存,在原子性被破坏时:
1)修改数据库成功了
2)淘汰缓存失败了
会导致,数据库与缓存数据不一致。
六、一致性优化
1、主库从库一致性问题
1.1、为什么会出现主从一致性问题?
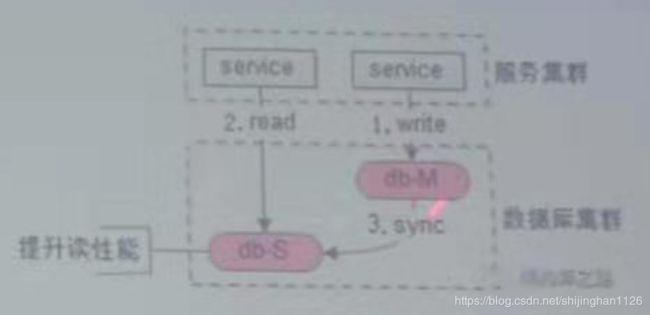
在主向从同步过程中,会出现主从一致性问题。
1.2、如何优化主从不一致问题
方案1、忽略
绝大多数业务,都允许主库和从库短时间内不一致。
方案2、强制读主库
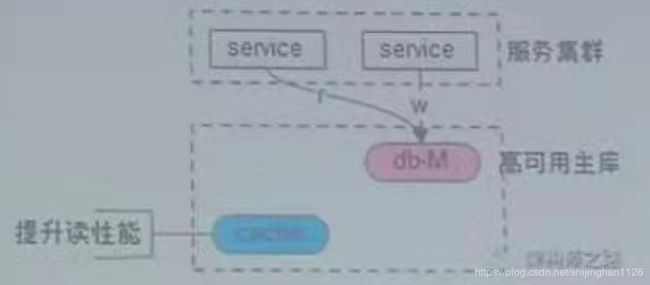
方案3、选择性读主库
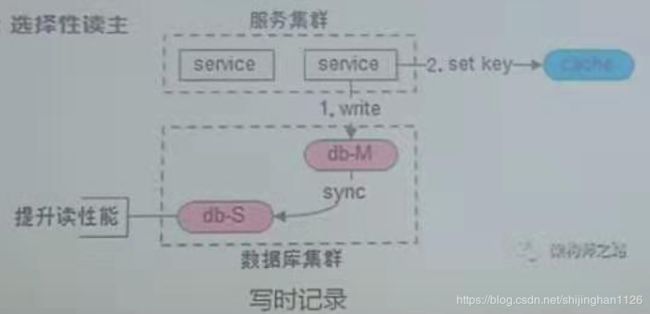
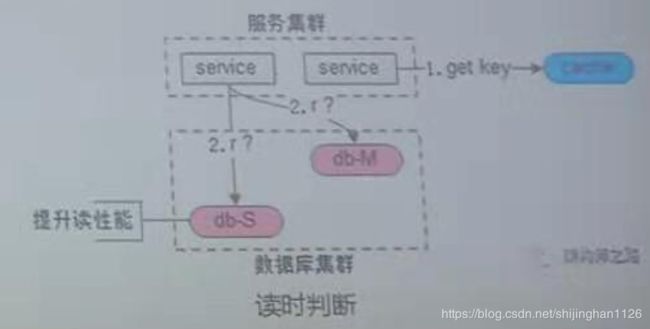
2、缓存一致性问题
2.1、为什么会出现缓存一致性问题
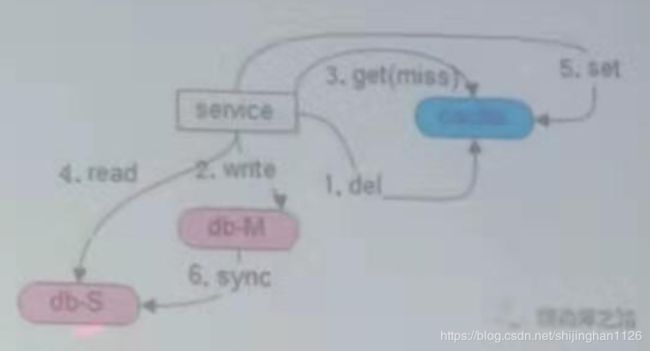
“写后立即读”问题:
"先写DB,再删除缓存“,只能缓解该问题,但不能根治。
2.2、如何优化缓存不一致问题
消除“主从延时”导致的不一致:

从binlog触发一次“二次淘汰”,
也可以在service层异步触发“二次淘汰”。
即写数据时在写完DB后,删除了缓存;这时有读请求到从库,此时主库还没有完成向从库的同步,读请求读到的从库不是最新数据,而更新了缓存。那么,当主库同步完从库后,会通过binlog或service层异步触发“二次淘汰”来更新缓存。
七、扩展性
1、典型的微服务架构数据库扩容
特点:数据量大、吞吐量达、高可用
系统架构:微服务
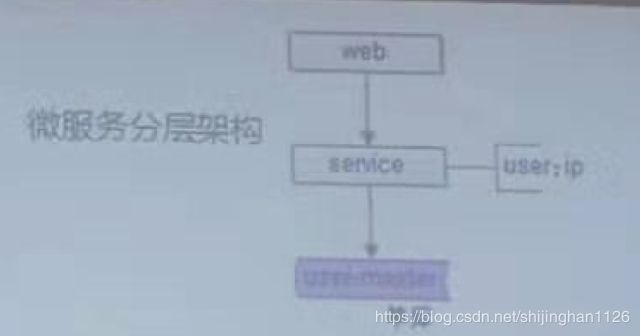
思考:
1)数据层如何高可用

2)数据层如何扩展

2、要解决什么问题
- 吞吐量持续增大,如何进一步增加实例
- 数据量持续增大,如何进一步水平扩展
3、扩展性问题解决方案
方案1、停服扩容

方案2、追日志

Step1、记录日志:对新的操作记录日志到文件
Step2、数据迁移:把原数据库的数据迁移到新库
Step3、数据补齐:把旧库的日志补齐到新库
Step4、数据检验:通过工具检验新库与旧库的数据是否一致,不一致通过手动等方式补齐。
方案3、双写

Step1、双写数据(服务升级)
Step2、数据迁移(通过小工具)
Step3、数据检验(通过小工具)
方案4、双倍扩容
Step1、改配置
Step2、reload配置
Step3、收尾
4、各类业务场景的水平切分实践
问题:如何拆?按哪个属性拆?
下面的场景几乎涵盖了互联网90%的场景。
- 单key:用户库:user(uid, XXOO)
- 1对多:帖子库:tiezi(tid, uid, XXOO)
- 多对多:好友库:friend(uid, friend_uid, XXOO)
- 多key:订单库:order(oid, buyer_id, seller_id, XXOO)
4.1、用户库拆分
用户库:10亿数据量
user(uid, uname, passwd, age, sex, create_time, … )
业务需求如下:
- 1%登陆请求:where uname=xxx and passwd=xxx
- 99%查询请求:where uid=xxx
方案:按uid分库
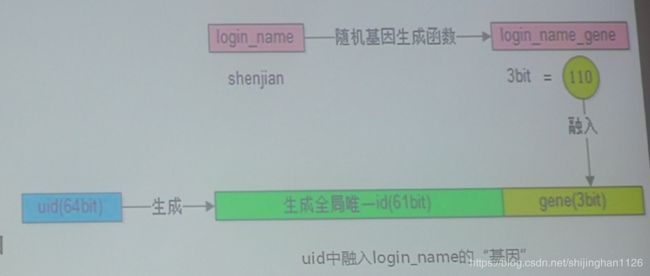
- 索引表法:根据hash分区,再查。
- 缓存映射法
- login_name生成uid
- 基因法:uid中融入login_name的“基因”:这样利用login_name就可以定位到库。
结论:根据uid来拆分库,即把uid作为负载均衡的key, 把用户平均存到n个库中。
4.2、帖子库拆分
结论:“1对多”场景,使用“1”分库,例如帖子库中一个uid对应多个tid, 则采用uid进行分库。
4.3、好友库拆分
好友库:friend(uid, friend_uid, nick, memo, XXOO)
业务需求如下:
- 查询我的好友(50%的请求):用于页面展示
select friend_uid from friend where uid=xxx - 查询加我为好友的用户(50%的请求):用户反向通知
select uid from friend where friend_uid=xxx

即对于各50%的查询操作,通过数据冗余存1份来拆分。
结论:”多对多”场景,使用数据冗余方案,多份数据使用多种分库手段。即把查询分流。不同的查询请求落到不同的库上查询。
4.4、订单库拆分
订单库:10亿数据量
order(oid, buyer_id, seller_id, order_info, xxoo)
业务需求如下:
-
查询订单信息:80%请求
select * from order where oid=xxx -
查询我买的东西:19%请求
select * from order where buyer_id=xxx -
查询我卖出的东西:1%请求
select * from order where seller_id=xxx
结论:“多key”场景一般有两种方案:
方案一:采用2和3综合的方案
方案二:1%的请求采用多库查询
八、总结
1、数据库工程架构,要考虑:
- 库结构、表结构、索引结构
- 高可用、读性能、一致性、扩展性
2、保证高可用的思路:复制冗余
但数据冗余会引发一致性问题
3、提升读性能的场景方案是:
- 加索引:不同库的索引可以不一样
- 加从库:会引发主从不一致
- 加缓存:会引发缓存不一致
4、旁路缓存最佳实践,Cache Aside Pattern:
- 读最佳实践
- 写最佳实践:淘汰缓存,先写数据库
5、数据冗余带来的一致性问题优化:
- 主从不一致:忽略、强制读主、选择性读主
- 缓存不一致:“写后立即读”问题,二次淘汰
6、增加数据库实例、增大数据库容量的扩展性实践:
- 停服扩容
- 追日志扩容(记日志+迁移数据+追日志+一致性对比)
- 双写扩容(双写+迁移数据+一致性对比)
- 双倍扩容(改配置+reload+收尾)
7、用户库拆分实践:
- 索引表、缓存映射、生成uid、基因法决定login_name路由
- 前台与后台分离,解决后台类需求
8、帖子库拆分实践:
- uid分库,基因法决定tid路由
- 索引外置,解决检索类需求
9、好友库拆分实践:
- 数据冗余,是实现多对多的常见实践
- 数据冗余的三类方法:服务同步冗余、服务异步冗余、服务线下冗余
- 最终一致性实践:线下扫全库、先下扫增量、线上实时检测
10、订单库拆分实践:
- 融会贯通,综合应用