为什么你的SQL执行很慢
为什么你的SQL执行很慢
- SQL语句执行很慢原因分析
- 1.没走索引
- 1.1对索引字段进行了计算操作
- 1.2存在隐式类型转换
- 1.3 like操作
- 1.4隐式编码转换
- 1.5 not in 操作
- 1.6扫描行数太多
- 2.等待锁
- 3.刷脏页
- 4.执行undo log
- 索引设计原则讨论
最近看完了丁奇老师在极客时间的课程,不得不说确实干货满满,然后趁着热乎劲顺手又二刷了《MySQL技术内幕》中的部分内容。但很多东西都是零散的,总觉得需要稍微总结一下。那写点什么呢?就从之前经常被问的两道面试题说起吧。
- 如果一条SQL语句执行很慢,你觉得有哪些原因?
- 如果让你给一张表设计索引,你会考虑哪些因素?
SQL语句执行很慢原因分析
先来回答第一个问题,如果一条SQL语句执行会很慢,会有哪些可能的原因。为了方便说明问题,这里先给出建表语句和初始化语句:
CREATE TABLE `t` (
`id` int(10) NOT NULL AUTO_INCREMENT,
`a` int(10) DEFAULT NULL,
`b` varchar(16) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_a` (`a`),
KEY `idx_b` (`b`)
) ENGINE=InnoDB;
insert into t values (null, 1,'1');
insert into t values (null, 2,'2');
insert into t values (null, 3,'3');
1.没走索引
首先,绝大部分人都能想到的一点就是SQL语句没有走索引。明明给相关字段加了索引,可为什么就是不走索引呢?极大概率是因为索引失效了,以下场景都有可能导致索引失效。
1.1对索引字段进行了计算操作
看这个例子:

为什么对索引字段进行了计算操作之后,就不会走索引了呢?
这里我们需要明白,走索引的本质其实是利用了B+树的有序性以便进行快速定位。但是对索引字段进行计算操作之后,有可能会破坏这种有序性(非线性计算),导致无法利用B+树的这一特性,因此优化器会放弃使用B+树的树搜索功能。
注意,这里要特别强调的是,这种情况下优化器只是放弃了树搜索的能力,而并不是一定会放弃走索引。什么意思呢?请继续看这个例子:

你看,在这个例子中,虽然依然对索引字段a做了计算操作,但是最终优化器还是走了索引idx_a。从执行计划还可以看出,优化器对该索引做了全索引扫面,且使用了覆盖索引。之所以没有选择遍历主键索引,是因为辅助索引更小,且可以利用覆盖索引。
所以,正确的姿势应该是这样的,把函数计算放在变量上:

1.2存在隐式类型转换
我们知道,MySQL中数字和字符串之间可能存在隐式类型转换,很多人都认为当发生隐式类型转换的时候,就不会走索引。真的是这样吗?我们来看两个例子:


在上面两个例子中,字段a和b其实都发生了隐式类型转换,但是结果却不一样。这是因为在MySQL中,当发生字符串和数字比较的场景时,会把字符串隐式转换为数字。
1.3 like操作
在like操作中,当%在前面时,也不会走索引。

1.4隐式编码转换
前面3种没有走索引的场景很多人都能答得上来,但还有一种比较不常见的,也是丁奇老师在他的课程中提到的隐式编码转换场景。
在MySQL中,每张表都可以单独指定其字符集,最常见的就是utf8和utf8mb4了,当两张表字符集不同时,进行联表操作会存在字符集转换,从而导致索引失效。这里不展开,具体可以参考丁奇老师的课程。
1.5 not in 操作
MySQL5.6之前的版本,not in操作也会导致索引失效。但在MySQL5.6引入ICP优化之后,not in操作也是可以走索引的,请看:

所谓ICP,全称Index Condition Pushdown(索引条件下推),即在索引遍历过程中,对索引中包含的字段先做判断,过滤掉不满足条件的记录,如此一来就可以减少回表次数,提升性能。
1.6扫描行数太多
为了说明这个问题,我们这里新建一张表t1并作初始化:
CREATE TABLE `t1` (
`id` int(10) NOT NULL,
`a` int(10) DEFAULT NULL,
`b` int(10) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_a` (`a`),
KEY `idx_b` (`b`)
) ENGINE=InnoDB;
delimiter ;;
create procedure idata()
begin
declare i int;
set i=1;
while(i<=10000)do
insert into t1 values(i, i, i);
set i=i+1;
end while;
end;;
delimiter ;
call idata();
然后看这样一个例子:


按照我们的理解,这两个语句应该会走索引idx_a,但是执行计划却显示第一个走了全表扫描,这又是为什么呢?
这是因为我们查询的是整行信息,根据辅助索引查到数据后还需要回表,这个成本也是要考虑在内的。当访问的数据占全表数据较大时,优化器会放弃辅助索引而直接全表扫描。
我们知道选择索引时优化器的工作,优化器在决定使用哪个索引时会综合考虑扫描行数、是否使用临时表、是否排序等信息,在我们这个例子中显然就是扫描行数的原因,也就是图中的rows字段。
那么在执行语句之前,优化器是怎么知道扫描行数的呢?这里就需要提到索引区分度了,也就是索引Cardinality(基数),这是一个统计信息,用于统计索引中不重复记录的个数。我们可以用show index命令看下:

看到这里你也许会感到奇怪,表中明明只有10000行数据,为什么主键的基数却是10337?
因为基数本身其实是一个预估值,如果通过全表扫描的方式来精确统计的话,每次发生变更都需要做一次全表扫描,在生产环境这是不可接受的。所以InnoDB是通过采样的方式来预估的,既然是预估,那么就有可能不准确。当然,也不是每次发生变更都会进行采样,以下两种场景都会触发InnoDB对基数值的重新预测:
- 自上次统计后,表中1/16的数据已发生变化
- 自上次统计后,表的修改次数 > 2 000 000 000
因此,当基数统计不准确的时候,优化器就有可能不走索引或者选错索引,针对这种场景,我们有两种解决方案:
- 使用analyze table t命令触发基数的重新统计
- 使用force index(idx_a)强制走索引

2.等待锁
这也是很容易想到的一点,我们正在执行的SQL语句,可能需要对某些资源加锁(比如表锁或者行锁),但是该资源正在被其他事物持有,导致当前事务必须等待。碰到这种场景,我们可以使用show processlist命令查看当前语句的状态,以作进一步的分析。关于SQL语句加锁又是一个很大的话题,本文不做展开,以后找机会写篇文章细聊。

当面试官问你SQL语句为什么执行很慢时,你能回答道这一步基本可以让提问者感到满意了,但这还不足以让他感到惊艳。如果你还能回答下面提到的两点之一,应该可以为自己加分不少哦~
3.刷脏页
为了保证事务的持久性,InnoDB引擎采用了Write Ahead Log(WAL)策略,即事务提交时,先写日志,再写磁盘。当然在写日志之前会更新内存,而这里的日志自然也就是redo log了。
当内存中的数据页相对磁盘的数据页发生变化时,我们称该内存页为脏页,反之则为干净页。从持久性上考虑,脏页是必须要刷回磁盘,这个过程我们称之为刷脏页,而这个过程中就有可能导致平时执行很快的SQL突然变慢了。那么什么情况会触发MySQL的刷脏页操作呢?一般来说有以下4种情况:
- 我们知道redo log区别于binlog的一个特点是容量有限、循环写入。因此当redo log写满时,必须停止其它所有更新操作来将redo log写入磁盘
- 因为脏页是存在于内存中,因此当内存不够用时,需要淘汰一部分数据页,如果淘汰的是脏页,就需要先将脏页同步到磁盘
- MySQL认为系统比较空闲的时候
- MySQL正常关闭的时候
而在这4种情况中,对我们影响最大的就是redo log写满的场景,因为一旦出现这种情况,整个系统将不再接受更新,这种场景需要尽量避免。另外如果内存不够用,需要淘汰的脏页太多,也会明显影响性能。
所以控制好脏页刷新的机制很重要。
4.执行undo log
这种场景也是丁奇老师在他的课程里提到的一点,怎么理解呢?
我们知道,更新语句不仅会写redo log,还会写undo log,即在事务更新数据之前,会先在undo log中记录该数据的当前版本,而这也正是InnoDB保证原子性和实现MVCC机制的关键,这里直接借用丁奇老师课程中的一张图作简要说明:
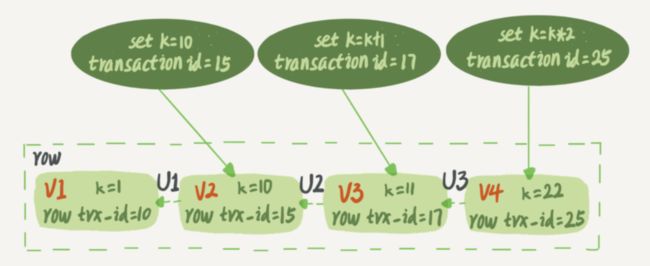
图中显示k值有4个版本,分别是id为10、15、17和25的事务修改的,V4即为其最新版本,而V1、V2、V3则是k值的历史版本。但需要说明的是,历史版本V1、V2、V3并不是物理上真实存在的,而是必要情况下根据undo log计算出来的,图中的虚线U1、U2、U3可以理解为就是undo log。
也就是说,当我们需要的k值是其V1版本的时候,我们需要从k值的当前版本V4出发,依次执行U3、U2和U1这三条undo log。因此如果一条SQL语句在当时需要执行很多的undo log来找到数据的某一历史版本的话,也可能导致执行起来很慢。
索引设计原则讨论
在上文讨论SQL语句为什么执行很慢时,我们发现最常见的原因就是没走索引或者走错了索引,可见索引的设计是很重要的,因此现在就来看看第二个问题:设计索引时需要考虑哪些因素,怎么设计索引?
- 如果能走聚集索引,就可以减少不必要的回表操作,因此尽量指定主键,这个我们一般用数据库自增id即可,因为自增id天然有序,且最多占用8个字节
- 如果能走覆盖索引,也可以避免回表,因此可以考虑将一些常用字段放在二级索引中,查询时查询不要查整行数据
- 选择区分度较高的字段进行索引,因为区分度太低的话,会导致基数很大,扫描行数增加
- 最好设计唯一索引,数据插入时可以确保业务正确
- 如果有大量更新操作,最好可以设计非唯一索引,以便利用change buffer带来的优势
- 对字符串字段加索引,如果字符串太长,可考虑前缀索引,
- 如果使用前缀索引对区分度影响较大,可以考虑倒叙存储+前缀索引的方式
- 由于索引也会占用磁盘空间,因此索引也不是越多越好
- 欢迎补充~
更多技术文章,咱们公众号见,我在公众号里等你~
