windows下安装使用fairseq框架
最近,Facebook又开源了fairseq的PyTorch版:fairseq-py。大家从最新的文章可以看出,用CNN来做机器翻译,达到顶尖的准确率,速度则是RNN的9倍;同时,Facebook还开放了seq2seq学习工具包fairseq的Torch源代码和已训练的系统。
fairseq-py优势与介绍
fairseq-py包含论文中描述的全卷积模型,支持在一台机器上用多GPU进行训练,以及CPU和GPU上的快速beam search生成。
fairseq-py可以用来里实现机器翻译,也能用于其他seq2seq的NLP任务。
这个开源工具包同时还包含英译法、英译德的预训练机器翻译模型。
fairseq-py比之前的Torch版更高效,翻译的速度提高了80%,训练速度提升近50%。
介绍
FAIR序列到序列工具包(PyTorch)
这是一个PyTorch版本的fairseq,一个从序列到序列学习工具包从Facebook的AI研究。这个重新实现的原始作者(没有特别的顺序)Sergey Edunov,Myle Ott和Sam Gross。该工具包实现卷积序列到序列学习中描述的完全卷积模型,并在单个机器上实现多GPU训练,并在CPU和GPU上实现快速波束搜索生成。我们提供英语到法语和英语到德语翻译的预训练模型。
安装
在Mac和Linux下的安装可以参考这篇文章:pytorch使用fairseq-py实现实现快速机器翻译
官方GitHub:https://github.com/pytorch/fairseq
官方文档:https://fairseq.readthedocs.io/en/latest/
Windows下的安装
1.首先需要安装anaconda3,需要3.6版本的python环境。(3.5或3.7理论上也可以)。可以到清华镜像站下载安装。
2.需要有支持CUDA的GPU,fairseq的训练过程只支持gpu。可以百度在win10下如何安装cuda和cudnn,安装过程和tf,caffe等的没有区别。不要忘记添加环境变量。
3.安装pytorch。官网安装地址:https://pytorch.org/get-started/locally/ 推荐用conda安装,注意选择对应的系统、python、cuda版本。
4.安装MinGW。因为安装的过程中需要编译,需要安装C++编译器。此处参考本篇文章。
http://www.mingw.org/ 在该网站下载
安装的是不要安装在C盘,这是大佬们给的建议,我也不懂,反正不要安装在C盘就对了。
整个过程是在线安装,所以需要网络。
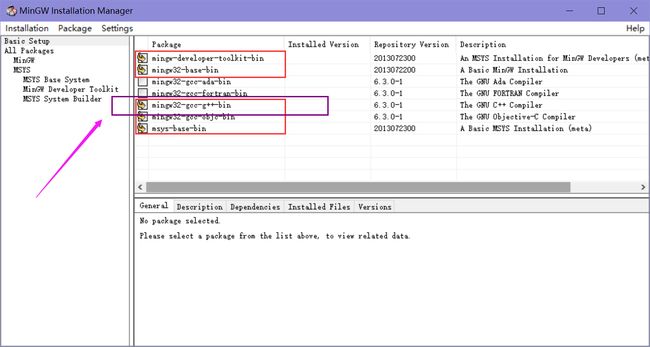
如果只是单纯的装gcc 选一个gcc紫框中的即可
然后点击左上Installation -> Apply Changes -> Apply
安装过程中对网络要求要稳定,如果出错按照出错重新安装。
配置环境变量
把安装路径加入系统环境
打开控制面板 -> 系统 -> 高级系统设置 -> 高级 -> 环境变量。
验证
gcc -v
5.需要安装git。安装方法自行百度,比较容易。
6.安装Cygwin。因为需要在windows下运行linux脚本,我们需要通过cygwin实现此功能。此处参考本篇文章。
在后续使用的过程中会发现缺少一些包,需要重复cygwin安装过程的最后一步,在所有安装包里搜索需要的安装包,勾选安装即可。(这里我也记不清缺了哪些了,反正来回安装了几次)。需要安装: dos2unix。
在安装好cygwin后,我们还需要安装wget:参考https://www.cnblogs.com/zlslch/p/7300873.html。
安装apt-cyg(相当于linux里的apt-get):参考http://www.cnblogs.com/asnjudy/p/4025887.html。
7.在cygwin中安装perl。因为官方示例脚本中使用了perl,如果想运行脚本,需要安装perl。但是我在windows下安装的perl在cygwin中无法使用,需要在Cygwin中安装。安装过程参考:https://blog.csdn.net/u013310119/article/details/81003526。安装过程会很慢。
8.安装fairseq。
首先安装相应的包:
conda install gcc cudnn nccl
conda install magma-cuda80 -c soumith
pip install cmake
pip install cffi然后下载安装fairseq:
git clone https://github.com/pytorch/fairseq.git
cd fairseq
pip install -r requirements.txt
python setup.py build
python setup.py develop如果上面过程都完成了,安装应该会正常进行。如果build的过程出现报错,基本上是因为版本问题或者gcc编译器的版本问题,可以尝试百度解决。
9.运行脚本
$ cd data/
$ dos2unix prepare-iwslt14.sh
$ bash prepare-iwslt14.sh
$ cd ..
$ TEXT=data/iwslt14.tokenized.de-en
$ python preprocess.py --source-lang de --target-lang en \
--trainpref $TEXT/train --validpref $TEXT/valid --testpref $TEXT/test \
--thresholdtgt 3 --thresholdsrc 3 --destdir data-bin/iwslt14.tokenized.de-en注意,我们虽然在Cygwin下运行linux命令,但实际上还是Windows环境,会出现许多编码问题。
注意这里要先用dos2unix转换编码,不然会报错:$'\r': 未找到命令。
运行的时候还会报几个错。需要改这几个地方:
(1)在prepare-iwslt14.sh的第10行:
BPEROOT=subword-nmt改成BPEROOT=subword-nmt/subword_nmt
因为windows下不支持python文件里直接写另一个文件名来引用的形式。感兴趣可以看看不修改情况下的报错。这里具体的原因我理解也不是很深。
(2)tokenizer.py文件的37行,84行:
with open(filename, 'r') as f:改成with open(filename, 'r',encoding='utf8') as f:
这是因为windows下,文件默认打开的编码是gbk,不改会报错。
10.训练模型
$ mkdir -p checkpoints/fconv
$ CUDA_VISIBLE_DEVICES=0 python train.py data-bin/iwslt14.tokenized.de-en \
--lr 0.25 --clip-norm 0.1 --dropout 0.2 --max-tokens 4000 \
--arch fconv_iwslt_de_en --save-dir checkpoints/fconv具体参数设置可以参考官方文档。这里是用fairseq-py卷积模型,框架还提供了lstm和transformer两种模型。
11.运行模型(以及计算BLEU)
> python generate.py data-bin/iwslt14.tokenized.de-en \
--path checkpoints/fconv/checkpoint_best.pt \
--batch-size 128 --beam 5
| [de] dictionary: 35475 types
| [en] dictionary: 24739 types
| data-bin/iwslt14.tokenized.de-en test 6750 examples
| model fconv
| loaded checkpoint trainings/fconv/checkpoint_best.pt
S-721 danke .
T-721 thank you .
...在运行这一步的时候会报错,出现bleu_zero_init() function找不到的情况。这是由于在windows下编译的过程中,函数名被改变了。需要在fairseq/fairseq/clib/libbleu/libbleu.cpp这个文件中,第99行的extern "C" 里面的三个函数前面加上__declspec(dllexport):
__declspec(dllexport) void bleu_zero_init(bleu_stat* stat)
__declspec(dllexport) void bleu_one_init(bleu_stat* stat)
__declspec(dllexport) void bleu_add然后重新build fairseq就可以了。这个问题在fairseq的git上的issue 292。
之后我们会遇到另一个错误,出现在generate.py的print的过程中,应该是因为print默认gbk编码,无法识别特殊字符(可能是德语字母)。需要在generate.py前面加上:
import io
import sys
sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='utf-8')更改print的默认编码为utf-8。就不会报错了。
至此就可以在Windows下成功运行起来官方的示例了。