互联网金融:风控评分卡知识要点整理
风控评分卡知识要点
建立评分卡之前需要确定的要素
1)项目目标
2)项目范围
3)时程规划
4)成本效益分析
5)配套措施
6) 运营计划
评分卡模型开发七步骤
1)确定评分目的
2)基本参数的定义
1、分观察期和表现期。
2、违约和不确定的定义,使用滚动率来确定
3、确定评分范围
4、样本分组
3)资料准备
1、来源:申请资料、内部黑名单、第三方数据
2、数据质量:正确性,实时信,合法性,可用性
4)变量分析
5)建立模型
6)拒绝推论,推测拒绝用户的还款表现,从而增大样本数量
1、单纯扩充法,用核准的用户训练模型,然后计算出拒绝用户的理论违约率。将违约率高于threadhold的用户定义为bad user(前提是初步模型要有比较高的正确率)
2、计算初拒绝用户的理论违约率之后,根据初步模型的分数将用户分组。再按该组的正常和违约比例随机分配拒绝用户的好坏属性(前提是初步模型要有比较高的稳定性)
6)评分卡验证,ROC,AUC(模型有效性),KS值,卡方检验(统计学效果),PSI(稳定性)
评分卡应用
用户分级
将风险相近的用户分成同一组,然后进行根据业务需求设定分割点
单点分割:不是拒绝就是接受
双点分割:中间的一段不太能确定的采用人工审核
##双评分卡混合使用
1)同时采用银行内部信用和外部信用评分,做交叉验证。如果差别比较大的化就需要人工介入。
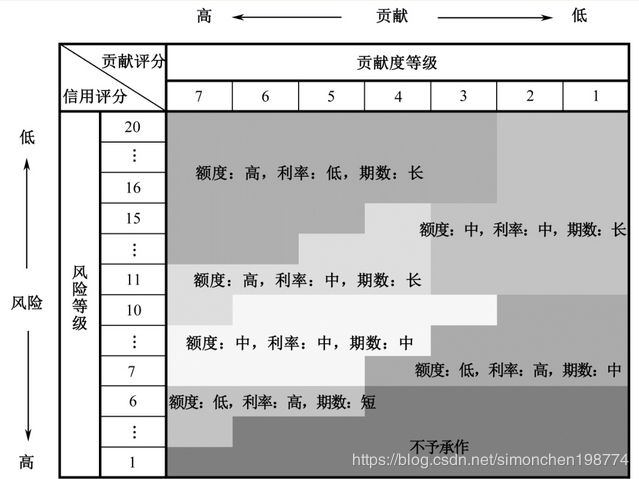
2)结合风险维度和贡献维度进行评分
评分卡的规格和设计
数据质量的检验
1)是否有足够的坏客户
2)模型训练的客户是否和用来预测的客户属于同一个群体
3)数据的准确性,比如说收入是年收入还是9个月的收入,比如说是否有过空值插入
排除样本
1)政策性通过或者拒绝的人
1)不予以评分的人,比如收入过高或信用极好的人
好用户、坏用户定义
1)采用滚动率法来定义,首先对用户的好坏进行程度上的划分
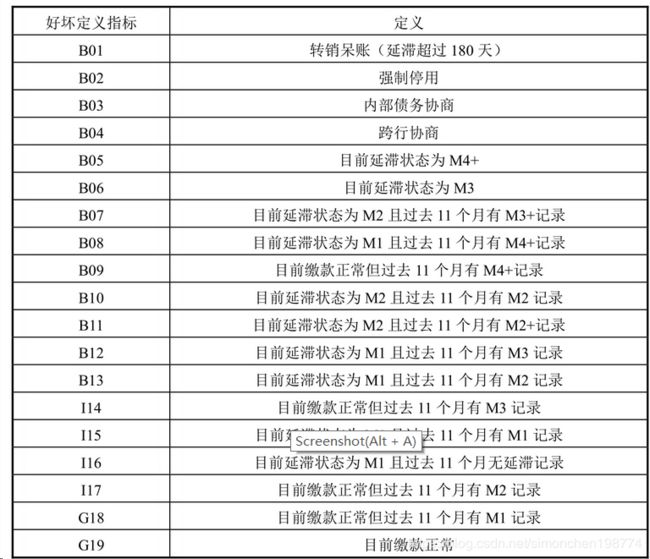 然后根据滚动率计算用户从一个状态下滑到另外一个状态的概率
然后根据滚动率计算用户从一个状态下滑到另外一个状态的概率
评分卡预测能力评价
Vintage模型,一般观察时间是12个月
分组分析
1)业务需求
2)统计预测力,1、好坏比值在各分组间有明显差异,2、利用决策树确定有基本预测能力的变量,再看这些按这些变量分组是否满足业务需求 3、每个分组间要有一定数量的样本
 如上图所示,我们利用决策树模型将用户客群大致分成了网银用户、公积金用户以及按照6个月平均消费额度计算出来的工资卡用户
如上图所示,我们利用决策树模型将用户客群大致分成了网银用户、公积金用户以及按照6个月平均消费额度计算出来的工资卡用户
细致分析与自变量分析
细致分类
一般是吧变量按照样本数量均分,观察目标的变化趋势是否和业务经验相匹配
##单因子分析
PSI表示稳定性,小于0.1说明比较稳定
IV值大于0.3时说明有比较强的预测能力,0.1-0.3表示有部分的预测能力
粗略分类
用户好坏对比的趋势应该与业务经验保持一致
最多8个区间
将空白的数值分配到Null区间,如果Null区间的好坏比比整体要低,那么就把Null区间作为一个独立的区间经行WOE的分析,否则的化建议去除该变量或者在Null值比较少的情况下删除这些样本
模型建立方法论
线性回归
变量选择
1)顺向选择法,看自变量是否有最小的F值(一般大于0.5)
2)反向淘汰法
3)逐步分析法
回归系数的显著信检验
t检验,F检验
https://www.cnblogs.com/nxld/p/6123239.html
R检验
R2=SSR/SST
逻辑回归
WOE检验
模型表现,卡方检验
单变量->Wald值检验
整体模型的检验->-2log(L)最大似然函数的检验
逻辑回归+线性回归组合建模过程
步骤1、拆分训练集和测试集
步骤2、WOE计算,要与经验相一致
步骤3、相关性分析,如果相关性大于0.7,则取WOE值高的变量
步骤4、重复步骤2到步骤3,寻找最佳模型变量
步骤5,利用步骤4选择出来的变量拟合逻辑回归模型
步骤6, 计算log(odd)值的残差,并利用线性回归拟合出残差和第三方变量的线性关系
步骤7,结合线性回归和逻辑回归计算出odd_adjust值,
步骤8,模型检验ROC,KS
步骤9,将ODD值转化为分数
拒绝推论的原因和方法
拒绝推论的使用原因和场景
使用原因:1)增加建模样本数量
2)光靠核准的用户集只能知道接受了多少坏用户,但是无法知道有多少好用户被拒绝
2)可以帮助找出被拒绝的好用户,从而改善内部的流程
3)高核准率且判断信心很强的时候不适合做拒绝推论
4)拒绝推论的流程
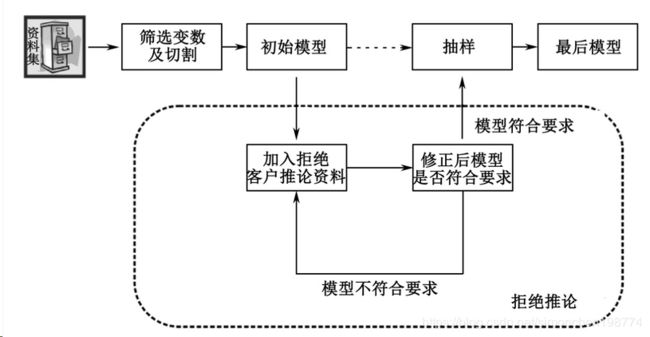
拒绝推论的方法
1)依照现行的好坏比进行判断,缺点是容易低估坏用户的比例
2)在特定时间内核准所有申请件
3)核准所有阈值以上的申请件,但是随机核准阈值以下的申请件,给临界点以下的用户较低的授信额度
4)两张评分卡交互使用
5)利用行外数据判断用户的好坏
6)分配法

7)硬性截断法,设定一个坏用户比例p,低于p的视为坏用户
8)迭代再分类,反复使用分配法模型,直到模型的log(odd)与score的分布收敛为止
最终模型的选择和风险校准
最终模型的产出
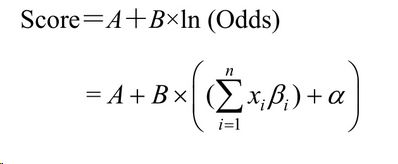
最终模型的产出
设定风险校准
不同评分卡的分数调教
1)计算出各个样本分组的最终模型得分
2)各分组样本由低到高排序
3)将排好序的样本切成n等分,再计算每一等分的log(odd)值,建立每种切等的平均分数及log(odd)的回归式,观察哪种回归式有最强的解释能力
风险等级区隔
 模型验证
模型验证
1)基尼系数
2)KS值
3)ROC曲线
决策点(cut-off)设定
1)好坏件比率,规定评分卡通过的用户好坏件比率必须在一定水平以上
2)核准率,规定一定的通过比率
3)好用户数量,开发样本中核准用户中的好用户数量要在一定的比例以上
4)坏用户数量,开发样本中核准用户中的坏用户数量要在一定的比例以下
信用评分监控报告
1)观察期间的稳定度PSI
2)表现期间鉴别度
前端监控报告
评分分布表
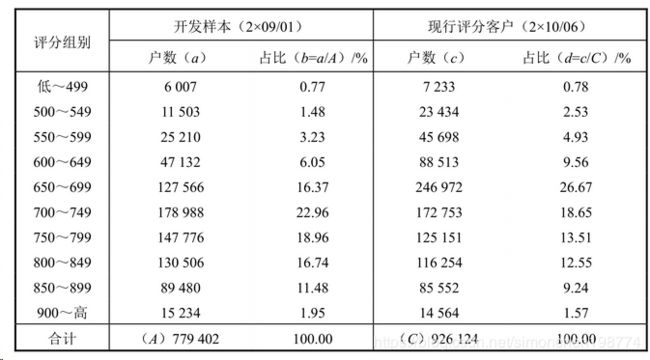 PSI:用来衡量客群的稳定度,小于0.1说明没有太大的变化,0.1到0.25说明有少许变化,超过0.25说明变化很大,需要调整评分卡
PSI:用来衡量客群的稳定度,小于0.1说明没有太大的变化,0.1到0.25说明有少许变化,超过0.25说明变化很大,需要调整评分卡
变量稳定度分析:
 此变量绝对值越大,说明变量越不稳定。如果为正,就说明用户在向好的方向增加,为负就说明坏用户的比例增加
此变量绝对值越大,说明变量越不稳定。如果为正,就说明用户在向好的方向增加,为负就说明坏用户的比例增加
人工否决分析:高分否决的比例需要监控,如果高分否决的比例太高就需要和运营人员及时沟通
好坏比例表:对观察期的用户实施log(odd)-score图,越陡峭就说明模型的区分能力越强,否则就说明模型的区分能力越弱
信用评分模型运用
申请评分卡:风险定价,初始额度给与,反欺诈
行为评分卡:风险定价,复审依据,提额管理
催收评分卡:制定催收策略
额度增加策略举例
 违约用户定义:账龄分析可以帮助了解违约成熟期是多少,滚动率可以帮助我了解到违约的什么样的标准可以定义为坏用户
违约用户定义:账龄分析可以帮助了解违约成熟期是多少,滚动率可以帮助我了解到违约的什么样的标准可以定义为坏用户
催收策略
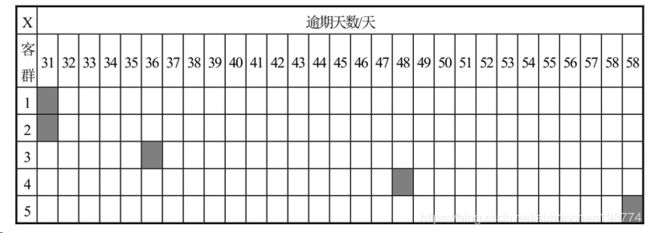
 逾期情况的报表:迁移率报表或称逾期的矩阵,比如对于M3的用户
逾期情况的报表:迁移率报表或称逾期的矩阵,比如对于M3的用户
1)任然没有还款,恶化进入M4
2)还了一期款,维持在M3
4)还了多期贷款,从M3到M2,甚至M1
不同等级的用户催收策略不同:
1、早期逾期用户分成3类:1)加强巩固类 2)介入干预类 2)治疗恢复类
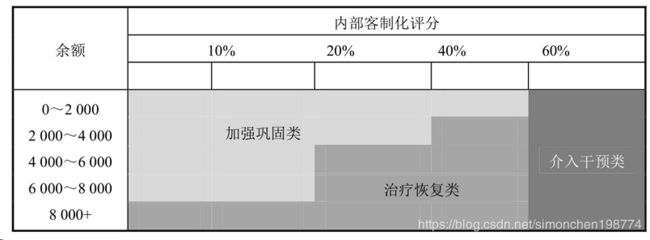 2. 中晚期客群:适度催收有还款能力但还款意愿弱的用户,对有意愿还款但还款能力差的用户提供解决方案
2. 中晚期客群:适度催收有还款能力但还款意愿弱的用户,对有意愿还款但还款能力差的用户提供解决方案
3. 核销用户:适当催收还有可能还款的客户(未失联的)
催收排期
催收排期实质上是一个多限制条件下的规划优化问题,可以将用户按照不同的风险维度划分成不同的客群(轻度,重度逾期,是否有还款意愿,还款能力如何),然后再制定相应的催收策略