计算机二级Python易忘考点整理
事先声明,这里记录的是我刷二级题时遇到的不熟悉的问题时记录下来的笔记。可能并不适合所有人,仅供参考。
任何问题请联系邮箱:[email protected] (因为不常上网站,所以留言和私信可能无法及时回复)
个人介绍:业余“开发者”一枚,Python为其启蒙语言,但已经很久没有认真写过Python直到不久前突然想考计算机二级,于是慢慢开始刷二级Python题库。
##一、语法或函数
本项主要记录刷题时经常遇到,但我使用较少,或完全没有使用过的语法或函数
以下函数解释多来自于:菜鸟教程
- id([object])
- 获取对象内存地址
- object – 对象
- 返回对象的内存地址。
- 例:
x = "abc"
y = "abc"
print(id(x)==id(y))
输出:True
- list.extend(seq)
- 添加列表内容
- seq – 元素列表。
- 该方法没有返回值,但会在已存在的列表中添加新的列表内容。
- 例:
aList = [123, 'xyz', 'zara', 'abc', 123];
bList = [2009, 'manni'];
aList.extend(bList)
print "Extended List : ", aList ;
输出:
Extended List : [123, 'xyz', 'zara', 'abc', 123, 2009, 'manni']
- list.insert(index, obj)
- 函数用于将指定对象插入列表的指定位置。
- index – 对象 obj 需要插入的索引位置。
obj – 要插入列表中的对象。 - 该方法没有返回值,但会在列表指定位置插入对象。
aList = [123, 'xyz', 'zara', 'abc']
aList.insert( 3, 2009)
print "Final List : ", aList
输出:
Final List : [123, 'xyz', 'zara', 2009, 'abc']
-
lambda 语法
详见:lambda -
三元运算:
val = 1 if 条件 else 2
条件为True时val=1
否则=2
- Python程序语言指定任何非0和非空(null)值为true,0 或者 null为false。
下列对象的布尔值都是False:
NONE;
False(布尔类型)
所有的值为零的数
0(整型)
0.0(浮点型)
0L(长整型)
0.0+0.0j(复数)
""(空字符串)
[](空列表)
()(空元组)
{}(空字典)
- divmod(a, b)
- 函数把除数和余数运算结果结合起来,返回一个包含商和余数的元组(a // b, a % b)。
- a-- 数字
b–数字 - 例:
>>>divmod(7, 2)
(3, 1)
>>> divmod(8, 2)
(4, 0)
>>> divmod(1+2j,1+0.5j)
((1+0j), 1.5j)
- str.strip([chars])
- 用于移除字符串头尾指定的字符(默认为空格或换行符)或字符序列。
注意:该方法只能删除开头或是结尾的字符,不能删除中间部分的字符。 - chars – 移除字符串头尾指定的字符序列。
- 返回移除字符串头尾指定的字符生成的新字符串。
- str.count(sub, start= 0,end=len(string))
- 用于统计字符串里某个字符出现的次数。可选参数为在字符串搜索的开始与结束位置。
- sub – 搜索的子字符串
start – 字符串开始搜索的位置。默认为第一个字符,第一个字符索引值为0。
end – 字符串中结束搜索的位置。字符中第一个字符的索引为 0。默认为字符串的最后一个位置。 - 该方法返回子字符串在字符串中出现的次数。
- str.join(sequence)
- 用于将序列中的元素以指定的字符连接生成一个新的字符串。
- sequence – 要连接的元素序列。
- 返回通过指定字符连接序列中元素后生成的新字符串。
str = "-";
seq = ("a", "b", "c"); # 字符串序列
print str.join( seq );
输出:a-b-c
- str.upper()
- 方法将字符串中的小写字母转为大写字母。
- 返回小写字母转为大写字母的字符串。
- list.sort(cmp=None, key=None, reverse=False)
- 用于对原列表进行排序,如果指定参数,则使用比较函数指定的比较函数。
- cmp – 可选参数, 如果指定了该参数会使用该参数的方法进行排序。
key – 主要是用来进行比较的元素,只有一个参数,具体的函数的参数就是取自于可迭代对象中,指定可迭代对象中的一个元素来进行排序。
reverse – 排序规则,reverse = True 降序, reverse = False 升序(默认)。 - 该方法没有返回值,但是会对列表的对象进行排序。
- chr(i)
- chr() 用一个范围在 range(256)内的(就是0~255)整数作参数,返回一个对应的字符。
- i – 可以是10进制也可以是16进制的形式的数字。
- 返回值是当前整数对应的ascii字符。
注:在3.x 中,chr() 和 ord() 默认支持unicode
ord() 函数是 chr() 函数(对于8位的ASCII字符串)或 unichr() 函数(对于Unicode对象)的配对函数,它以一个字符(长度为1的字符串)作为参数,返回对应的 ASCII 数值,或者 Unicode 数值,如果所给的 Unicode 字符超出了你的 Python 定义范围,则会引发一个 TypeError 的异常。
- raise [Exception [, args [, traceback]]]
- 使用raise语句自己触发异常
- Exception 异常的类型(例如,NameError)参数标准异常中任一种
args 自已提供的异常参数。
traceback 在实践中很少使用该参数,跟踪异常对象。
一个异常可以是一个字符串,类或对象。 Python的内核提供的异常,大多数都是实例化的类,这是一个类的实例的参数。
定义一个异常非常简单,如下所示:
def functionName( level ):
if level < 1:
raise Exception("Invalid level!", level)
# 触发异常后,后面的代码就不会再执行
s = None
if s is None:
raise NameError
print 'is here?' #如果不使用try......except这种形式,那么直接抛出异常,不会执行到这里
- str.center(width[, fillchar])
- 返回一个原字符串居中,并使用空格填充至长度 width 的新字符串。默认填充字符为空格。
- width – 字符串的总宽度。
fillchar – 填充字符 - 该方法返回一个原字符串居中,并使用空格填充至长度 width 的新字符串。
>>>str = 'runoob'
>>> str.center(20, '*')
'*******runoob*******'
>>> str.center(20)
' runoob '
- format
print("{0:{2}^{1}}".format("a", 10, "*"))
输出:
****a*****
- 字符串的比较
1、比较字符串是否相同:
==:使用==来比较两个字符串内的value值是否相同
is:比较两个字符串的id值。
2、字符串的长度比较
len():显示字符串的长度,返回数字整型。可以进行长度的比较。
3、使用比较运算符
>、<、> = 、< =、比较的规则为:从第一个字符开始比较,排序在前边的字母为小,当一个字符串全部字符和另一个字符串的前部分字符相同时,长度长的字符串为大。
-
转义字符:
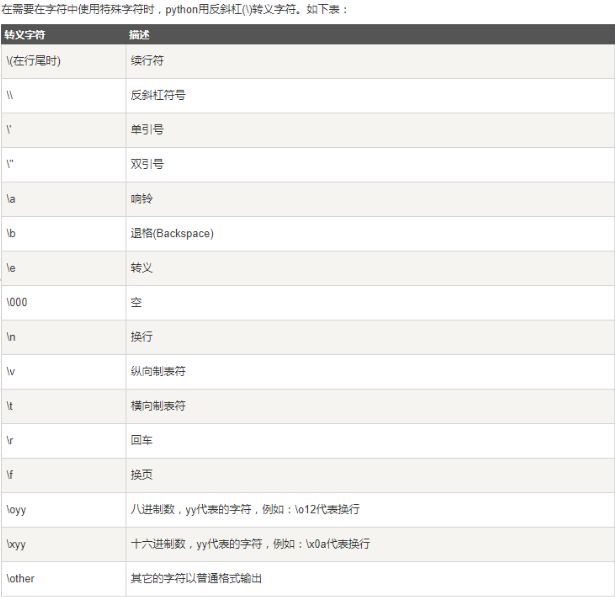
-
** 运算是右结合的:
>>> 2**2**3
256
而非:
>>> 2**2**3
64
运算时先运算 2**3 = 8
再运算 2**8 = 256
-
file.isatty()
判断文件是否连接到一个终端设备,如果是,返回True,如果否,返回False。 -
a = [0,1,2,3,4,5,6,7,8,9]
b = a[i:j] 表示复制a[i]到a[j-1],以生成新的list对象
b = a[1:3] 那么,b的内容是 [1,2]
当i缺省时,默认为0,即 a[:3]相当于 a[0:3]
当j缺省时,默认为len(alist), 即a[1:]相当于a[1:10]
当i,j都缺省时,a[:]就相当于完整复制一份a了
b = a[i:j:s]这种格式呢,i,j与上面的一样,但s表示步进,缺省为1.
所以a[i:j:1]相当于a[i:j]
当s<0时,i缺省时,默认为-1. j缺省时,默认为-len(a)-1
所以a[::-1]相当于 a[-1:-len(a)-1:-1],也就是从最后一个元素到第一个元素复制一遍。所以你看到一个倒序的东东 -
链式比较:
a < b < c 等价于 a < b and b < c
而非 (a < b) < c -
for else
当迭代的对象迭代完并为空时,位于else的子句将执行,而如果在for循环中含有break时则直接终止循环,并不会执行else子句。
for i in range(10):
if i == 5:
print 'found it! i = %s' % i
else:
print 'not found it ...'
输出:
found it! i = 5
not found it ...
for i in range(10):
if i == 5:
print 'found it! i = %s' % i
break
else:
print 'not found it ...'
输出:
found it! i = 5
- str.isdigit()
- 检测字符串是否只由数字组成。
- 如果字符串只包含数字则返回 True 否则返回 False。
- str.isalpha()
- 检测字符串是否只由字母组成。
- 如果字符串至少有一个字符并且所有字符都是字母则返回 True,否则返回 False
- pow()
- math.pow( x, y ) 或内置
- pow(x, y[, z])
- 函数是计算x的y次方,如果z在存在,则再对结果进行取模,其结果等效于pow(x,y) %z
注意:pow() 通过内置的方法直接调用,内置方法会把参数作为整型,而 math 模块则会把参数转换为 float。
>>> type(pow(2, 3))
>>> type(pow(2.0, 3))
>>> pow(2, 3)
8
>>> pow(2.0, 3)
8.0
>>> 8 == 8.0
True
>>> 8.0 == 8
True
- dict.get(key, default=None)
- 返回指定键的值,如果值不在字典中返回默认值
- key – 字典中要查找的键。
default – 如果指定键的值不存在时,返回该默认值值。 - 返回指定键的值,如果值不在字典中返回默认值None。
dict = {'Name': 'Zara', 'Age': 27}
print "Value : %s" % dict.get('Age')
print "Value : %s" % dict.get('Sex', "Never")
输出:
Value : 27
Value : Never
- str.split(str="", num=string.count(str))
- 通过指定分隔符对字符串进行切片,如果参数 num 有指定值,则分隔 num+1 个子字符串
- str – 分隔符,默认为所有的空字符,包括空格、换行(\n)、制表符(\t)等。
num – 分割次数。默认为 -1, 即分隔所有。 - 返回分割后的字符串列表。
str = "Line1-abcdef \nLine2-abc \nLine4-abcd";
print str.split( ); # 以空格为分隔符,包含 \n
print str.split(' ', 1 ); # 以空格为分隔符,分隔成两个
输出:
['Line1-abcdef', 'Line2-abc', 'Line4-abcd']
['Line1-abcdef', '\nLine2-abc \nLine4-abcd']
ls =list({'shandong':200, 'hebei':300, 'beijing':400})
print(ls)
输出:
['shandong', 'hebei', 'beijing']
二、常见 Python 框架
- caffe:是一个清晰,可读性高,快速的深度学习框架
- RoboBrowser:轻量级爬虫、自动化测试库
- newspaper:python爬取新闻常用的库
- Grab:爬虫框架
- scipy:数据分析与处理
- pandas:数据分析与处理
- moviepy:视频处理
- prefile:代码性能分析
- openpyxl:读写excel
- Django:WEB框架
- PyGObject:图形界面
- wxPython:图形界面
三、常用第三方库–jieba
###基本用法
- 精准模式:
将字符串分割成等量的中文词组,返回结果是列表类型。
>>>import jieba
>>>ls = jieba.lcut("全国计算机等级考试Python科目")
>>>print(ls)
['全国','计算机','等级','考试','Python','科目']
- 全模式:
将字符串的所有分词可能均列出来,返回结果是列表
类型,冗余性最大。
>>>import jieba
>>>ls = jieba.lcut("全国计算机等级考试Python科目", cut_all=True)
>>>print(ls)
['全国','国计','计算','计算机','算机','等级','考试','Python','科目']
- 搜索引擎模式:
该模式首先执行精确模式,然后再对其中长词进一步切分获得最终结果。
>>>import jieba
>>>ls = jieba.lcut_for_search("全国计算机等级考试Python科目")
>>>print(ls)
['全国','计算','算机','计算机','等级','考试','Python','科目']
- 增加单词:
>>>import jieba
>>>jieba.add_word("Python科目")
>>>ls = jieba.lcut("全国计算机等级考试Python科目")
>>>print(ls)
['全国,'计算机','等级','考试','Python科目']
###模式选择
搜索引擎模式更倾向于寻找短词语,这种方式具有一定冗余度,但冗余度相比全模式较少。 如果希望对文本准确分词,不产生冗余,只能选择jieba.lcut(s)函数,即精确模式。如果希望对文本分词更准确,不漏掉任何可能的分词结果,请选用全模式。如果没想好怎么用,可以使用搜索引擎模式。
###实例
统计红楼梦词频,并输出前十五的词语和词频
import jieba
f = open("红楼梦.txt", "r")
txt = f.read()
f.close()
words = jieba.lcut(txt)
counts = {}
for word in words:
if len(word) == 1: #排除单个字符的分词结果
continue
else:
counts[word] = counts.get(word,0) + 1
items = list(counts.items())
items.sort(key=lambda x:x[1], reverse=True)
for i in range(15):
word, count = items[i]
print ("{0} {1}".format(word, count))
输出:
宝玉 3748
什么 1613
一个 1451
贾母 1228
我们 1221
那里 1174
凤姐 1100
王夫人 1011
你们 1009
如今 999
说道 973
知道 967
老太太 966
起来 949
姑娘 941
排除无用词语:
excludes = {"什么","一个","我们","那里","你们","如今", \
"说道","知道","老太太","起来","姑娘","这里", \
"出来","他们","众人","自己","一面","太太", \
"只见","怎么","奶奶","两个","没有","不是", \
"不知","这个","听见"}
for word in excludes:
del(counts[word])
四、数据结构与储存
###数据结构
- 数据结构包括存储结构和逻辑结构。
- 同一种逻辑结构的数据可以采用不同的存储结构,但影响数据处理的效率。
- 数据结构:
逻辑结构:线性结构{顺序、链表、栈、队列}、非线性结构{树、二叉树、图}〉、
存储结构〈顺序、链接、索引〉 - 在树的结构中,一个结点所拥有的后件(子树)的个数称为该结点的度;所有结点中最大的度称为树的度;树的最大层次称为树的深度。
例题:一棵树的度为4,其中度为4,3,2,1的结点的个数分别为2,3,3,求叶子结点的个数
答案:16个(树状图法求解) - 在二叉树的第k层上最多有2的(k-1)次方(k≥1)个结点。
满二叉树的叶子节点数为 2的(n-1)次方个。
深度(层数)为m的二叉树最多有2的m次方-1个结点。
在任意一棵二叉树中,度数为0的结点(即叶子结点)总比度为2的结点多一个。 - 二叉树遍历:
前序遍历:根左右
中序遍历:左根右
后序遍历:左右根
参见 - 二分法查找最坏情况下,需要比较的次数为(log以2为底n的对数)次
- 树的根结点数量可以为0或1
- 关系表中的每一横行称为一个元组
- 相对于数据库系统,文件系统的主要缺陷有数据关联差、数据不一致性和冗余性
###数据库 - 数据库系统(DBS) :由数据座(数据)、数据库管理系统(软件)、数据库管理员(人员)、硬件平台(硬件)、软件平台(软件)五个部分构成的运行实体。
- 数据库系统的三级模式
概念模式:数据库系统中全局数据逻辑结构的描述,是全体用户(应用)公共数据视图。
外模式:也称子模式或用户模式,它是用户的数据视图,也就是用户所见到的数据模式,它由概念模式推导而出。
内模式:又称物理模式,它给出了数据库物理存储结构与物理存取方法。 - 在数据库技术中, 为提高数据库的逻辑独立性和物理独立性, 数据库的结构被划分为用户级、 存储级和概念级。
- 数据库技术的根本目标是要解决数据的共享问题
- 数据结构作为计算机的一门学科,主要研究数据的逻辑结构、对各种数据结构进行的运算,以及数据的储存结构
- 数据库设计的四个阶段是:需求分析、概念设计、逻辑设计和物理设计
- 对于数据库系统,负责定义数据库内容,决定存储结构和存取策略及安全授权等工作的是:数据库管理员
- 数据库系统依靠模式分级,各级模式之间的映射支持数据的独立性。
五、杂项(公共基础知识)
-
Python是一种解释型、面向对象、动态数据类型的高级程序设计语言
-
程序设计风格:清晰第一,效率第二。
结构化程序设计原则:自顶向下,逐步求精,模块化,限制使用goto语句(Python无 goto 语句)。
模块设计要求:高内聚,低耦合。 -
面对对象基本特点:继承性、多态性、封装性
-
软件的概念:
软件包括程序、数据、及相关文档的完整集合。
机器能执行的是程序、数据,不能执行的是文档。
工程化的3个要素:方法、工具、过程
软件的生命周期:提出、实现、使用、维护、停止使用、退役
原则:抽象、信息屏蔽、模块化
具有:局部化、确定性、一致性、完备性、可验证性 -
在程序流程图中,用带有箭头的线段表示控制流;在数据流程图中,用带有箭头的线段表示数据流。
-
软件测试目的:尽可能多地发现程序中的错误,不能也不可能证明程序没有错误。
-
测试方法:白盒测试(测试软件内部方法:逻辑覆盖基本路径测试)黑盒测试(测试软件外部即在软件接口处进行,主要完成软件功能验证方法:等价步、划分法、边界值、分析法、错误推断法、因果图等)
-
软件设计包括软件的结构、数据接口和过程设计(系统结构部件转换成软件的过程描述)
-
软件开发模型包括 Ⅰ、瀑布模型 Ⅱ、扇形模型 Ⅲ、快速原型法模型 Ⅳ、螺旋模型Ⅰ、Ⅲ、Ⅳ
-
软件生命周期的主要活动阶段:需求分析
-
pip升级pip:pip install -U pip
-
忘记模块用法?使用 dir(模块名) 即可查看该模块包含的函数;使用help(模块名)即可查看详细文档


-
整数类型有4种进制表示,十进制、二进制(0b)、八进制(0o)、十六进制(0x)
-
软件需求规格说明书的作用不包括:软件可行性研究的依据
-
将E—R图转换到关系模式时,实体与联系都可以表示成
-
数据处理的最小单位是数据项
-
软件设计包括软件的结构、数据接口和过程设计,其中软件的过程设计是指:系统结构部件转换成软件的过程描述
-
软件开发离不开系统环境资源的支持,其中必要的测试数据属于:辅助资源
-
下列路径表示错误的是:F:\PythonTest\abc.txt
可用表示方式:F:\PythonTest\abc.txt F:/PythonTest/abc.txt F://PythonTest//abc.txt -
映射类型是“键值”数据项的组合,每个元素是一个键值对,元素之间是无序的。
-
binary 二进制的
octal 八进制的
hexadecimal 十六进制的
decimal 十进制的 -
如果改变一个数值类型变量的值,变量的内存地址就会改变
-
单分支结构指只有if语句,没有else语句的分支结构
-
以下选项,不属于程序流程图基本元素的是:
A.判断框
B.循环框
C.连接点
D.起始框
答案:B -
函数:
函数是一种功能抽象
使用函数后,代码的维护难度降低了
函数名可以是任何有效的Python标识符
使用函数的目的只是为了增加代码复用(错误) -
软件开发的结构化生命周期方法将软件生命周期划分成:
定义、开发、运行维护