语义分割 | 新SOTA,Cityscapes 85.1%mIoU!分层多尺度注意力超越HRNetV2+OCR+SegFix
点击上方“AI算法修炼营”,选择“星标”公众号
精选作品,第一时间送达

论文地址:https://arxiv.org/pdf/2005.10821.pdf
代码地址:尚未开源
发布团队:英伟达
主要贡献
1、本文提出一种有效的分层多尺度注意机制,通过允许网络学习如何最佳地组合来自多个推理尺度的预测,从而有助于避免不同类之间的混淆,处理更加精细的细节。
2、提出一种基于硬阈值的自动标记策略,可利用未标记的图像提高IOU。
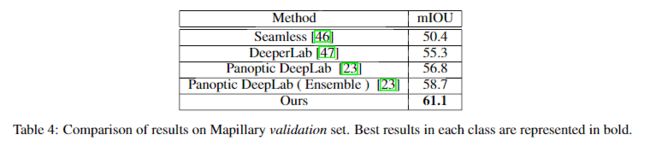
3、在Cityscapes test上可达85.1% mIoU,在Mapillary val上高达61.1% mIoU,表现真SOTA!性能优于SegFix、HRNetV2-OCR等网络。
动机
类别混淆问题:
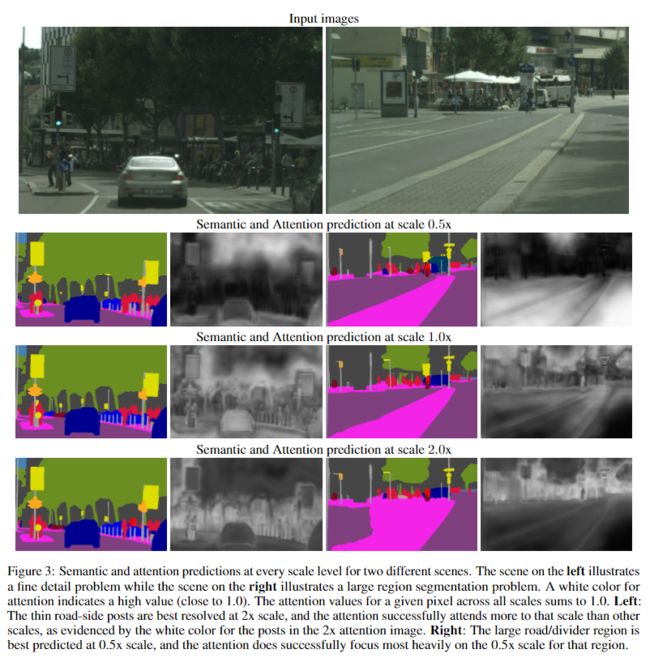
语义分割的任务是将图像中的所有像素标记为属于N类之一。在这项任务中有一个折衷,就是某些类型的预测最好在较低的推理分辨率下处理,而其他任务最好在较高的推理分辨率下处理。精细的细节(例如物体的边缘或薄的结构)通常可以通过放大图像尺寸来更好地预测。同时,对于较大结构的预测(需要更多的全局上下文),在缩小图像尺寸时通常会做得更好,因为网络的感受野可以观察到更多必要的上下文。我们将后一个问题称为类别混淆问题。
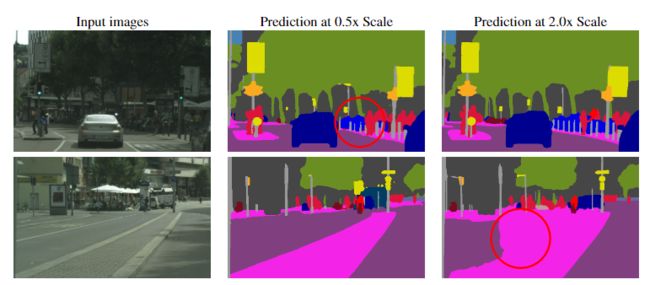
在第一行中,细杆在缩小(0.5x)图像中被不一致地分割,但在放大(2.0x)图像中得到更好的预测。在第二行中,较大的道路/分隔线区域以较低的分辨率(0.5x)进行了更好的分割。
多尺度推理:
使用多尺度推理是解决这种折衷的常用方法。预测在一定范围内进行,并将结果与平均或最大合并合并。使用平均值组合多个尺度通常可以改善结果,但是会遇到将最佳预测与较差预测相结合的问题。例如,如果对于给定的像素,最佳预测来自2倍大小的像素图,而更差的预测来自0.5倍大小的像素图,则平均将合并这些预测,从而导致输出低于标准。另一方面,最大池化仅选择N个标度中的一个用于给定像素,而最佳答案可能是跨不同标度的预测的加权组合。
本文方法:Hierarchical multi-scale attention
在本文工作中,提出了一种基于注意力的方法来组合多尺度预测。实验表明,在一定尺度上的预测更适合解决特定的类别混淆问题,并且使得网络更容易在此类情况下倾向于使用这些尺度以生成更好的预测。
换句话说,作者认为不同大小的物体应该由不同分辨率的网络来做推理,比如大物体或者场景类物体应该缩小分辨率,相当于扩大感受野,而小的物体应该使用大的分辨率,这样有利保持细节。这也是一种多尺度预测的改进,其思路非常合理。
非常直观的做法就是输入不同分辨率的图片,让网络学习一下,什么样的物体应该用什么样的分辨率。本文的思路和Liang-Chieh Chen大神2015年发表的《Attention to scale: Scale-aware semanticimage segmentation》类似,输入两个不同分辨率的图像,网络学习不同物体在相应分支上的权重。
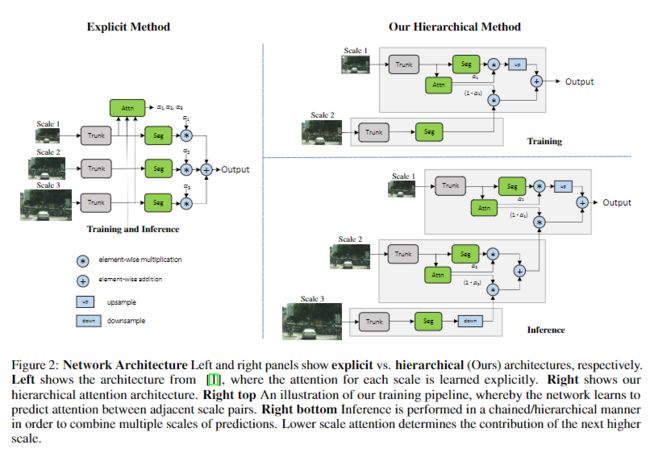
网络架构左面和右面分别显示了explicit vs.hierarchical(本文)架构。左边显示了来自Liang-Chieh Chen2015年所发表文章中的体系结构,其中对每个尺度的注意都是明确学习的。右边显示了本文的分层注意力结构。右上方是训练流程图,通过这个网络可以预测相邻尺度对之间的注意力。右下角的推理以链式/层次化的方式执行,以便结合多个预测尺度。
本文提出的网络如上图所示,网络可以通过该机制学习预测相邻尺度之间的相对权重。本文的注意力机制是分层的,因此与其他最新方法相比,其注意力训练的内存效率大约高4倍。除了可以进行更快的训练之外,这还使我们可以使用更大的crop进行训练,从而提高了模型的准确性。
为了获得一对缩放图像,将单个输入图像按比例缩小2倍,这样就只剩下一个1倍的缩放输入和一个0.5倍的缩放输入。这使得网络学会预测一个范围内的图像尺度的相对注意力。在进行推理时,可以分层次地应用所学习到的注意力,将N个预测尺度结合在一起,形成一个计算链。较低尺度的注意力决定了下一个较高尺度的贡献。
在训练过程中,给定的输入图像按因子r进行缩放,其中r= 0.5表示向下采样按因子2进行,r= 2.0表示向上采样按因子2进行,r= 1表示不进行操作。对于训练过程,选择r= 0.5和r= 1.0。因此,对于两种尺度的训练和推断,以U为双线性上采样操作,将∗和+分别作为像素级的乘法和加法,方程可以形式化为:
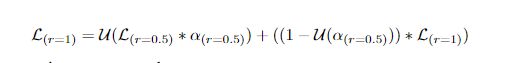
总的来说,本文的方法虽然训练的时候只用两个scale,但是测试的时候可以用多个scale hierarchically结合不同scale的结果,然后进行融合。这样相比直接训完做multiscale融合的优点:大小分辨率都同时进行训练,使用attention注意力代替了常用的average平均池化。
具体网络结构
Backbone:消融实验采用Resnet-50,正式SOTA网络采用HRNet-OCR
Segmentation Head:(3x3 conv)→(BN)→(ReLU)→(3x3 conv) →(BN) →(ReLU)→(1x1 conv)
Attention head:Resnet-50做backbone时候,语义头和注意头是由ResNet-5最后阶段的特征提供的。HRNet-OCR做backbone时,语义头和注意头是由OCR block提供的。
使用HRNet-OCR时候还存在一个auxiliary semantic head:由(1x1 conv)→(BN)→(ReLU)→(1x1 conv)构成。在将注意力机制用到语义逻辑之后,再用双线性上采样将预测结果上采样到目标图像的大小。
Auto Labelling on Cityscapes
受最近关于图像分类任务自动标记工作的启发,本文采用了一种用于Cityscapes的自动标记策略来增加有效数据集大小和标签质量。在Cityscapes中,有2万张带有粗糙标签的图片,以及3500张带有精细标签的图片。粗图像的标签质量非常适中,包含大量未标记的像素,如图所示。通过使用自动标签方法,可以提高标签的质量,这反过来又有助于模型IOU。
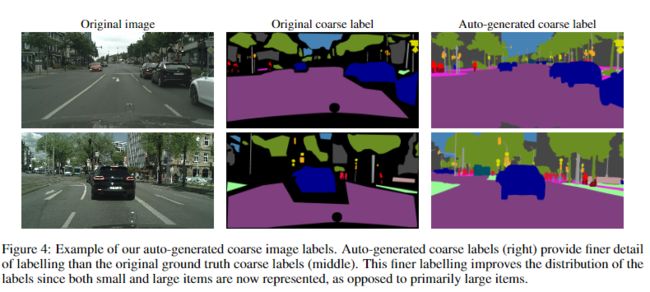
在图像分类中自动标记的常用技术是使用连续的软标记,从而教师网络为每个图像的每个像素为N个类的每一个提供目标(软)概率。这种方法的挑战是磁盘空间和训练速度:存储标签大约需要3.2TB磁盘空间:20000张图像* 2048w * 1024h * 19类* 4B = 3.2TB。即使选择存储此类标签,在训练过程中读取如此大量的标签也可能会大大减慢训练速度。
相反,本文采用了硬标签策略,即对于给定的像素,选择了教师网络的顶级预测。我们根据教师网络的输出概率来确定标签的阈值。超出阈值的教师预测将成为真实的标签,否则像素将被标记为信号等级。在实践中,使用0.9的阈值。
实验与结果分析
消融实验
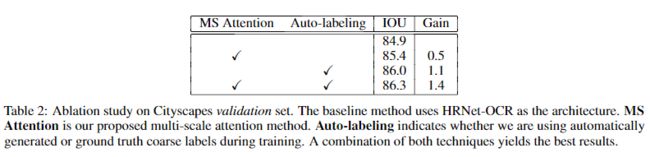
为了说明本文方法的有效性,以Resnet-50为backbone,训练DeepLabV3+架构进行比较,可以发现本文方法具有更高的精度。

还观察到,使用baseline的平均多尺度方法,简单地添加0.25x尺度会对精度产生不利影响,因为它会导致IOU降低0.7,而对于本文的方法,额外的0.25x尺度将提高精度0.6IOU。因为本文的网络能够以最合适的方式应用0.25倍预测,而不会在边缘使用它。
可以在下图中观察到这样的示例,其中对于左侧图像中的精细物体,只有0.5x的预测会涉及到很少的信息,但是在2.0x尺度中会出现非常强烈的注意力信号。相反,对于右侧非常大的区域,注意力机制将学会最大程度地利用较低的比例(0.5x)和很少的错误2.0x预测。
Cityscapes数据集上的实验

Mapillary Vistas数据集上的实验
具体实验细节可以参考原文。
扫描上方微信号,进入学习群。
目标检测、图像分割、自动驾驶、机器人、面试经验。
福利满满,名额已不多…