基于weka的中文文本分类(java版)
本demo已上传github 地址:https://github.com/CharlsShan/word-classify/tree/master/src/main
本例子是用springboot完成,基于weka实现中文文本分类 , 本例子只是一个简单版,可以在简单版基础上进行扩展分词后再分类,最后达到程序帮我们分词、分类,大大提高效率、简化了人工分类的成本。
首先什么是weka,百度给了解释:是一款免费的,非商业化(与之对应的是SPSS公司商业数据挖掘产品--Clementine )的,基于JAVA环境下开源的机器学习(machine learning)以及数据挖掘(data mining)软件。
但是软件使用java写的,软件中有部分是做文本分类的,我们可以把它提取出来自己用,首先先创建一个springboot项目,如果不清楚springboot如何创建,先看我的博客 https://blog.csdn.net/sinat_23225111/article/details/77984344
weka是怎么实现文本分类的呢? 其实可以简单理解为把所有分类、和每一类具体包括哪些词存到一个文件 weka称这个文件叫ARFF文件,然后把这个ARFF文件进行训练、成一个压缩版的模型,一个新词来了,就和模型就行比对,如果模型中有这个词,weka就把这个新词分到对应的分类中,举个例子 城市是一类,城市包括:深圳、北京、上海,先把这些词写到ARFF中,然后训练模型, 如果有个词是深圳的话 ,根据训练好的模型比对,程序就知道它属于城市这一分类。
那ARFF文件是什么格式?见博客 https://blog.csdn.net/sinat_23225111/article/details/77983583
再简单说就是机器是不知道怎么分类的,但是如果我们告诉他什么词属于什么类,当那个词再次被输入的时候,机器就知道它属于哪一类了。下面我们来看具体怎么实现。
首先现在springboot中导入依赖,重要的是weka的依赖(已标红)
org.springframework.boot
spring-boot-starter-parent
1.5.9.RELEASE
UTF-8
UTF-8
1.8
org.mybatis.spring.boot
mybatis-spring-boot-starter
1.3.1
org.springframework.boot
spring-boot-starter-web
org.springframework.boot
spring-boot-starter-logging
mysql
mysql-connector-java
runtime
org.projectlombok
lombok
true
org.springframework.boot
spring-boot-starter-test
test
org.springframework.boot
spring-boot-starter-log4j2
org.apache.commons
commons-lang3
3.3.2
nz.ac.waikato.cms.weka
weka-stable
3.8.1
com.alibaba
druid
1.0.11
配置文件如下
################################server################################
server.port=8601
server.session.timeout=30
server.tomcat.max-threads=5000
server.tomcat.uri-encoding=UTF-8
################################datasource-druid################################
spring.datasource.driverClass=com.mysql.jdbc.Driver
spring.datasource.url=jdbc:mysql://localhost:3306/test?useUnicode=true&characterEncoding=utf-8
spring.datasource.username=root
spring.datasource.password=12345
spring.datasource.platform=mysql
spring.datasource.type=com.alibaba.druid.pool.DruidDataSource
spring.datasource.initialSize=1
spring.datasource.minIdle=3
spring.datasource.maxActive=20
spring.datasource.maxWait=60000
spring.datasource.timeBetweenEvictionRunsMillis=60000
spring.datasource.minEvictableIdleTimeMillis=30000
spring.datasource.validationQuery=select 'x'
spring.datasource.testWhileIdle=true
spring.datasource.testOnBorrow=false
spring.datasource.testOnReturn=false
spring.datasource.poolPreparedStatements=true
spring.datasource.maxPoolPreparedStatementPerConnectionSize=20
spring.datasource.filters=stat,wall,slf4j
spring.datasource.connectionProperties=druid.stat.mergeSql=true;druid.stat.slowSqlMillis=5000
#########################################weka#########################################
model.path=E://model.arff
接下来我们要把词和分类写入ARFF中 ,但是那么多词事先些好吗?太多了吧,而且后期为了让机器知道更到的词怎么分,要不断的往模型中加入,怎么实现动态扩展?
我们可以把分类以及每一类都有那些词放到数据库中、用java代码自动生成ARFF文件,具体见https://blog.csdn.net/sinat_23225111/article/details/78022802
目前只讲解关键部分代码,如需要全部代码请访问最上面的github地址,modelPath为ARFF生成模型的地址,如果是本地,可以放在任何一个盘中,我是从配置文件中读出,放在E盘,如果是服务器,模型需要放在服务器的特定路径下
@Service
public class ClassifyService {
private static final Logger logger = getLogger(ClassifyService.class);
@Autowired
private ClassifyMapper classifyMapper;
@Autowired
private KeyWordMapper keyWordMapper;
@Value("${model.path}")
private String modelPath;
@Transactional
public void createWekaModel() {
// 从数据库查找到所有的收入分类数据
List allClassifyList = classifyMapper.selectAll();
if (allClassifyList == null || allClassifyList.isEmpty()) {
logger.error("没有从数据库查找到分类数据");
return;
}
logger.info("分类模型训练开始");
generateInstanceAndModelLearn(allClassifyList);
}
private void generateInstanceAndModelLearn(List allClassifyList) {
// 生成Instances(每个Instances对应一个ARFF)
Instances trainData = generateInstance(allClassifyList);
// 模型学习
FilteredClassifier evaluateAndLearn = WekaUtil.evaluateAndLearn(trainData);
WekaUtil.saveModel(modelPath, evaluateAndLearn);
logger.info("收入分类模型训练完毕并存储到硬盘");
}
/**
* 程序构建Arff文件
*
* @param allClassifyList
* @return
*/
private Instances generateInstance(List allClassifyList) {
// 得到所有的分类名
List varietyOfClassify = new ArrayList<>(100);
for (Classify classify : allClassifyList) {
varietyOfClassify.add(classify.getClassifyName());
}
// 构建@data数据
List entities = createArffData(allClassifyList);
ArrayList attributes = new ArrayList<>();
attributes.add(new Attribute("@@class@@", varietyOfClassify));
attributes.add(new Attribute("text", true));
// 构建instances
Instances instances = new Instances("classify", attributes, 500);
// 设置分类的索引
instances.setClassIndex(instances.numAttributes() - 1);
// 添加数据到@data
for (CreateData secRepoEntity : entities) {
Instance instance = new DenseInstance(attributes.size());
// 必须放在创建一个新的instance后 否则会报没加入Dataset异常
instance.setDataset(instances);
if (varietyOfClassify.contains(secRepoEntity.getClassifyName())) {
instance.setValue(0, secRepoEntity.getClassifyName());
instance.setValue(1, secRepoEntity.getTestValue());
}
instances.add(instance);
}
instances.setClassIndex(0);
return instances;
}
/**
* 准备ArffData数据
*
* @param allClassifyList
* @return
*/
private List createArffData(List allClassifyList) {
List createArffData = new ArrayList<>();
for (Classify classify : allClassifyList) {
List classifyKeywordByClassifyId = keyWordMapper.selectByClassifyId(classify.getId());
for (int i = 0; i < classifyKeywordByClassifyId.size(); i++) {
createArffData.add(new CreateData(classify.getClassifyName(), classifyKeywordByClassifyId.get(i).getKeywordName()));
}
}
return createArffData;
}
@Transactional
public String getResultByExecuteParticipleAndClassify(String word) {
try {
if (StringUtils.isBlank(word)) {
return "";
}
logger.info("需要分类的词是" + word);
// 加载词库模型
FilteredClassifier model = WekaUtil.loadModel(modelPath);
List allClassifyList = classifyMapper.selectAll();
List nameString= allClassifyList.stream().map(Classify::getClassifyName).collect(Collectors.toList());
// 得到分类结果
String result = makeInstance(model, nameString,word);
logger.info("分类结果" + result);
return result;
} catch (Exception e) {
logger.error("wordclassify error , detail message:{}", e);
}
return "";
}
/**
* 生成一个新的instance用于得出结果
*
* @param evaluateAndLearn
* @param varietyOfClassify
*/
public String makeInstance(FilteredClassifier evaluateAndLearn, List varietyOfClassify,String word) {
// 添加第一个分类值
FastVector fvNominalVal = new FastVector(50);
for (String classify : varietyOfClassify) {
fvNominalVal.addElement(classify);
}
Attribute attribute1 = new Attribute("@@class@@", fvNominalVal);
Attribute attribute2 = new Attribute("text", (FastVector) null);
FastVector fvWekaAttributes = new FastVector(2);
fvWekaAttributes.addElement(attribute1);
fvWekaAttributes.addElement(attribute2);
Instances instances = new Instances("cardniu_text_classify", fvWekaAttributes, 1);
// 设置索引
instances.setClassIndex(0);
// 创造一个新instance
DenseInstance instance = new DenseInstance(2);
instance.setValue(attribute2, word);
instances.add(instance);
double pred;
try {
pred = evaluateAndLearn.classifyInstance(instances.instance(0));
return instances.classAttribute().value((int) pred);
} catch (Exception e) {
logger.info(e.getMessage());
}
return "";
}
} WekaUtil如下,里面重要的是算法,我这里经过测试,选择了一种分类效果比较好的算法(已标红)
public class WekaUtil {
private static final Logger logger = getLogger(WekaUtil.class);
private WekaUtil() {
}
/**
* 以ARFF格式加载数据生成Instances
*
* @param fileName
* @return
*/
public static Instances loadDataset(String fileName) {
try (BufferedReader reader = new BufferedReader(new FileReader(fileName))) {
ArffReader arff = new ArffReader(reader);
Instances trainData = arff.getData();
// 设置分类索引为0 必须在训练库之前加上这条代码
trainData.setClassIndex(0);
return trainData;
} catch (IOException e) {
logger.error(e.getMessage(), e);
}
return null;
}
/**
* 这个方法构建了一个分类器,然后分类器根据读到的数据进行训练、学习,生成模型
*
* @param trainData
* @return FilteredClassifier
*/
public static FilteredClassifier evaluateAndLearn(Instances trainData) {
try {
StringToWordVector filter = new StringToWordVector();
filter.setAttributeIndices("last");
FilteredClassifier classifier = new FilteredClassifier();
classifier.setFilter(filter);
// 可选择不同算法 这里选择效率比较高的算法
classifier.setClassifier(new RandomTree());
classifier.buildClassifier(trainData);
Evaluation eval = new Evaluation(trainData);
eval.crossValidateModel(classifier, trainData, 2, new Random(1));
trainData.setClassIndex(0);
return classifier;
} catch (Exception e) {
logger.error(e.getMessage(), e);
}
return null;
}
/**
* 把分类器模型存储到文件中
*
* @param fileName
* @param classifier
*/
public static void saveModel(String fileName, FilteredClassifier classifier) {
try (ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream(fileName))) {
out.writeObject(classifier);
} catch (IOException e) {
logger.error(e.getMessage(), e);
}
}
/**
* 这个方法加载分类器模型
*
* @param fileName
* @return
*/
public static FilteredClassifier loadModel(String fileName) {
try (ObjectInputStream in = new ObjectInputStream(new FileInputStream(fileName))) {
Object tmp = in.readObject();
return (FilteredClassifier) tmp;
} catch (Exception e) {
logger.error(e.getMessage(), e);
}
return null;
}
}数据库设计如下:service层把这些数据写入weka的ARFF文件中。
DROP TABLE IF EXISTS `classify`;
CREATE TABLE `classify` (
`id` int(4) NOT NULL AUTO_INCREMENT,
`classify_name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=4 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of classify
-- ----------------------------
INSERT INTO `classify` VALUES ('1', '人名');
INSERT INTO `classify` VALUES ('2', '地名');
INSERT INTO `classify` VALUES ('3', '省份');
DROP TABLE IF EXISTS `key_word`;
CREATE TABLE `key_word` (
`id` int(4) NOT NULL AUTO_INCREMENT,
`classify_id` int(4) DEFAULT NULL,
`keyword_name` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=7 DEFAULT CHARSET=utf8;
-- ----------------------------
-- Records of key_word
-- ----------------------------
INSERT INTO `key_word` VALUES ('1', '1', '张三');
INSERT INTO `key_word` VALUES ('2', '1', '李四');
INSERT INTO `key_word` VALUES ('3', '2', '超市');
INSERT INTO `key_word` VALUES ('4', '2', '学校');
INSERT INTO `key_word` VALUES ('5', '3', '广东省');
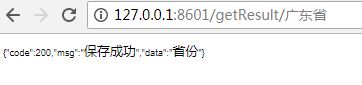
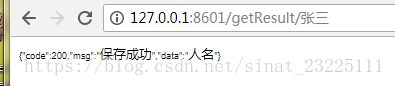
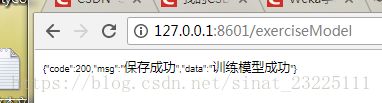
INSERT INTO `key_word` VALUES ('6', '3', '黑龙江省');验证结果 ,首先启动项目,第一步训练模型(把数据库中数据写入ARFF并生成模型存储在本地)
第二部,验证结果,我输入数据库的广东省,对应数据库中的省份,所以weka分类结果为省份;如果我输入张三,则对应的是人名,可想而知,当你把大量数据放入数据库,weka就能分类的越来越准,机器在不断地学习,模型在不断地完善。我们可以把训练模型变为定时任务,或者再加上分类,就可以对句子进行分类了。