数据结构的排序算法总结与分析(完整代码)
此文涉及的算法包括
1.插入排序
1.1直接插入排序
直接插入排序算法三点
(1)R[i]向前顺序查找,设置监视哨在R[0]位置
R[0]=R[i];
for(int j=i;R[0].Key
(2)对于那些查找中的关键字不小于R[i]的,向后移动
for(int j=(i-1);R[0].Key
(3)i←1 to n 实现所有数据的遍历
所以在实际代码中借用数组b[],亦可以数组写一个Key属性。我们选用借用数组b[n+1]来存储新的排序数列,之后用将b[]的内容写会到a[]即可。
代码实现如下:
#includeprintf("%3d",a[i]);
printf("\n");
}
void insertionSort(int *a,int n){
for(int i=1;i//key :a[i]
int temp=a[i];
int j;
for(j=(i-1);temp1]=a[j];
}
a[j+1]=temp;
printf("第%d次遍历",i);
printfSort(a,7);
}
}
int main(){
int a[7]={71,60,49,11,24,3,66};
printf("初始值:");
printfSort(a,7);
insertionSort(a,7);
//for(int i=0;i<7;i++)
//printf("%5d",a[i]);
return 0;
} 1.2折半插入排序
折半插入是与排序好的中间数比较,大于中间数则在右边,小于中间数则在左边,再进行左边那部分或者右边那部分中间比较直到(l==r)此时比较,大于则在这个数的右边,小于则就是这个数的位置,且这个数的位置右移一位。
void printfSort(int *a,int n){
for(int i=0;iprintf("%3d",a[i]);
printf("\n");
}
void TwoSort(int *a,int n){
for(int i=1;iint temp=a[i];
int l=0,r=i;
int p=0;
while(l2;
if(a[p]>temp){
for(int k=(r-1);a[k]>temp;k--){
a[k+1]=a[k];}
r=p-1;
}
else
{
l=p+1;
}
}
a[l]=temp;
printfSort(a,7);
}
}
int main(){
int a[7]={71,60,49,11,24,3,66};
printf("初始值:");
printfSort(a,7);
TwoSort(a,7);
return 0;
} 2.冒泡排序
冒泡排序将一个数组分成无序和有序队列,有序队列的长度随着外循环增大而增大,无序队列随着外循环的增大而减小。无序队列长度为i,有序队列为n-i;
以71,60,49,11,24,3,66为例
初始值:
| i | 数组 |
|---|---|
| 7 | 71 60 49 11 24 3 66 |
| 6 | 60 71 49 11 24 3 66 |
| 6 | 60 49 71 11 24 3 66 |
| 6 | 60 49 11 71 24 3 66 |
| 6 | 60 49 11 24 71 3 66 |
| 6 | 60 49 11 24 3 71 66 |
| 6 | 60 49 11 24 3 66 71 |
| 5 | 49 60 11 24 3 66 71 |
| 5 | 49 11 60 24 3 66 71 |
| 5 | 49 11 24 60 3 66 71 |
| 5 | 49 11 24 3 60 66 71 |
| 5 | 49 11 24 3 60 66 71 |
| 3 | 11 49 24 3 60 66 71 |
| 3 | 11 24 49 3 60 66 71 |
| 3 | 11 24 3 49 60 66 71 |
| 2 | 11 24 3 49 60 66 71 |
| 2 | 11 3 24 49 60 66 71 |
| 1 | 3 11 24 49 60 66 71 |
代码如下:
void BubbleSort(int *a,int n){
int i=(n-1);
int lastExchange;
while(i>0){
lastExchange=0;
for(int j=0;jif(a[j+1]int temp=a[j+1];
a[j+1]=a[j];
a[j]=temp;
lastExchange=j;
}
printfSort(a,7);
}
i=lastExchange;
}
} 总比较次数:
3.简单选择排序
其实我认为这个的算法复杂度是
void SelectSort(int *a,int n){
for(int i=0;i<(n-1);i++){
int temp=a[i],k=i;
for(int j=(i+1);jif(temp>a[j]){
temp=a[j];
k=j;
}
}
a[k]=a[i];
a[i]=temp;
printfSort(a,7);
}
} 4.希尔排序
希尔排序的思路是先将待排序列分组成若干个子序列分别进行直接插入排序。待整个序列中进行直接插入排序。这个算法想了很久,参考了一些人写的有些不是很理解,以下为根据定义自己想的方法,假设每次是分成一半(gap/2)。有的将gap分成(gap/3+1).
我刚开始一直纠结gap%2 如果是7个数据,那么会分成 1 4 7,2 5,3 6这三组数据。第一个是3个其他是2个。而如果是8个数据则是 1 3 5 7,2 4 6 8。数据是奇数第一组数据会比其他几组多1个数据。然后考虑的是不是分类,后面发现其实用个int number=0;while(1){
if(number*gap+i>n){break;}else{number++;}
}
这样每次的number就是的该组元素的个数,第一次循环gap=3 (7/2) .i的取值是0,1,2. 对应的number是3 2 2 .就可知第一次分三组对应的是
a[0] a[3] a[6],
a[1] a[4],
a[2] a[5].
后面想了会其实这个可以直接改写成for(int j=i;j
我们的数据还是参考71,60,49,11,24,3,66为例。
| gap | 组数 | 数据 |
|---|---|---|
| 7 | 1 | 71,60,49,11,24,3,66 |
| 3 | 1 | 71 11 66 |
| 3 | 2 | 60 24 |
| 3 | 3 | 40,3 |
此时是a[0] a[3] a[6]比较。
j=i+gap (3)
key =j (3)
temp=a[3] (11)
进入循环比较,11是小于71进入循环.a[3]=a[0],a[0]=temp.
不符合要求不会进入关于k的for循环,此时a[j]不变。
void shell_sort(int *a,int n){
int gap=n/2;//gap %2==0 else %2==1
while(gap>0){
for(int i=0;ifor(int j=i+gap;jint temp=a[j];
int key=j;
for(int k=j-gap;k>-1&&(temp2;
}
} 5.快速排序
快速排序我的另一篇文章里写过我就不再这里重复。
快速排序 跳转
6.堆排序
首先提及堆的定义:堆是满足下列性质的数列:
a[i]>=a[2i]&&a[i]>=a[2i+1]或者a[i]<=a[2i]&&a[i]<=a[2i+1]
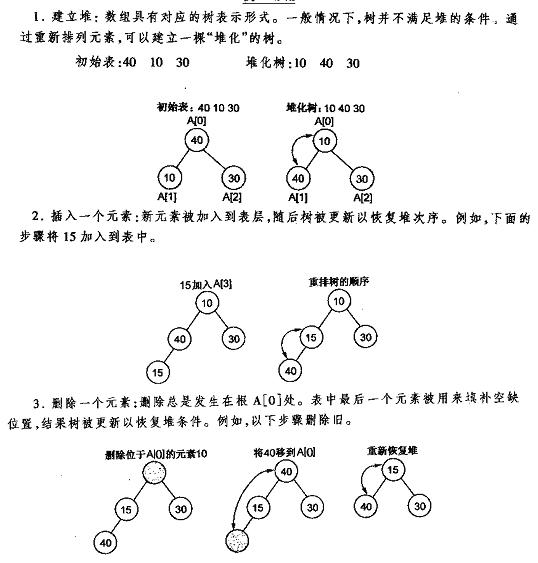
堆排序参考的文章中讲的方法和我的思路大概一致,需要解决的问题首先是如何建堆,堆分两种,大顶堆,小顶堆。此处算法是想从小到大排序,其实可以简历一个小顶堆,小顶堆的堆顶不断输出,排成的序列就是我们需要的从小到大的排序。所以第二个解决的问题是小顶堆的堆顶的输出。
建堆的方法,n个结点的完全二叉树,最后一个结点是n/2个结点的孩子。因为我可能说不太清建堆那些过程,因此涉及部分引用。
此处参考的是:http://blog.csdn.net/morewindows/article/details/6709644
MoreWindows先生的白话经典算法系列。
二叉堆是完全二叉树或者近似完全二叉树。
按照引用的方法建堆之后不断删除堆顶。
所以堆排序过程:
void MinHeapFixdown(int a[], int i, int n)
{
int j, temp;
temp = a[i];
j = 2 * i + 1;
while (j < n)
{
if (j + 1 < n && a[j + 1] < a[j]) //在左右孩子中找最小的
j++;
if (a[j] >= temp)
break;
a[i] = a[j]; //把较小的子结点往上移动,替换它的父结点
i = j;
j = 2 * i + 1;
}
a[i] = temp;
}
void MinheapsortTodescendarray(int a[], int n)
{
for (int i = n - 1; i >= 1; i--)
{
Swap(a[i], a[0]);
MinHeapFixdown(a, 0, i);
}
} 7.二路归并排序
二路归并 跳转
8.基数排序
对于数字型或字符型的单关键字,可以看成是由多个数位或多个字符构成的多关键字,此时可以采用这种“分配-收集”的办法进行排序,称作基数排数法,其好处是不需要进行关键字间的比较。
比如这组关键字{278,109,063,930,589,184,505,269,008,083}个位数分别为0,1,2,3,4,5,6…,9分配成10组,之后按从0至9的顺序将他们收集一起。930,063,083,184,505,278,008,109,589,269;十位数分成0,1,2,3,4,5…9;个位数分成0,1,2,3,4,5….9之后排序完成。
各种内部排序算法的比较
| 算法 | 时间复杂度最好 | 平均 | 最坏 | 空间复杂度 | 稳定性 | 复杂度 |
|---|---|---|---|---|---|---|
| 直接插入 | O(n) | O(n^2) | O(n^2) | O(1) | 是 | 简单 |
| 冒泡 | O(n) | O(n^2) | O(n^2) | O(1) | 是 | 简单 |
| 选择 | O(n^2) | O(n^2) | O(n^2) | O(1) | 否 | 简单 |
| 希尔 | - | O(nlogn)~O(n^2) | O(nlogn)~O(n^2) | O(1)) | 否 | 复杂 |
| 快速 | O(nlogn) | O(nlogn) | O(n^2) | O(logn) | 否 | 复杂 |
| 堆 | O(nlogn) | O(nlogn) | O(nlogn) | O(1) | 否 | 复杂 |
| 归并 | O(nlogn) | O(nlogn) | O(logn) | O(n) | 是 | 复杂 |
| 基数 | O(n+rd) | O(n+rd) | O(n+rd) | O(rd) | 是 | 复杂 |