cips2016+学习笔记︱简述常见的语言表示模型(词嵌入、句表示、篇章表示)
在cips2016出来之前,笔者也总结过种类繁多,类似词向量的内容,自然语言处理︱简述四大类文本分析中的“词向量”(文本词特征提取)事实证明,笔者当时所写的基本跟CIPS2016一章中总结的类似,当然由于入门较晚没有CIPS2016里面说法权威,于是把CIPS2016中的内容,做一个摘录。
CIPS2016 中文信息处理报告《第五章 语言表示与深度学习研究进展、现状及趋势》第三节 技术方法和研究现状中有一些关于语言表示模型划分的内容P33-P35,其中:
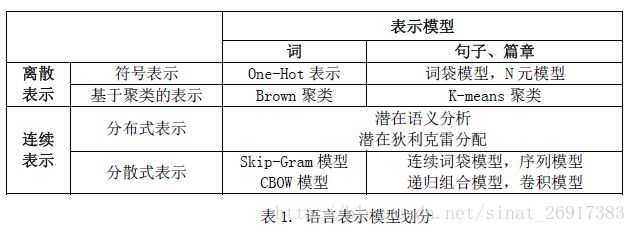
语言表示方法大体上可以从两个维度进行区分。一个维度是按不同粒度进行划分,语言具有一定的层次结构,语言表示可以分为字、词、句子、篇章等不同粒度的表示。另一个维度是按表示形式进行划分,可以分为离散表示和连续表示两类。离散表示是将语言看成离散的符号,而将语言表示为连续空间中的一个点,包括分布式表示和分散式表示。
CIPS2016 中文信息处理报告下载链接:http://cips-upload.bj.bcebos.com/cips2016.pdf
.
.
一、离散表示
1、词向量
- 一个词可以表示为One-Hot 向量(一维为1 其余维为0
的向量),也叫局部表示。离散表示的缺点是词与词之间没有距离的概念,这和事实不符。 - 一种改进的方法是基于聚类的词表示。其中一个经典的方法是Brown 聚类算法,该算法是一种层次化的聚类算法。在得到层次化结构的词类簇之后,我们可以用根节点到词之间的路径来表示该词。
2、句向量
有了词的表示之后,我们可以进一步得到句子或篇章的表示。句子或篇章的离散表示通常采用词袋模型、N 元模型等。
.
.
.
二、连续表示——分布式表示
这样就可以通过共现矩阵的方式来进行词的表示,这类方法也叫分布式表示(Distributional Representations)
1、词向量
潜在语义分析模型(Latent Semantic Analysis, LSA)、潜在狄利克雷分配模型(Latent Dirichlet Allocation,LDA)、随机索引(random indexing)等。
2、句向量
句子的表示方式对应于共现矩阵,另一列,在LDA中句子-词语矩阵中就是很好地句子表示方式。
.
.
.
★三、连续表示——分散式表示
另一种连续表示是分散式表示(Distributed Representations),即将语言表示为稠密、低维、连续的向量
1、词向量
研究者最早发现学习得到词嵌入之间存在类比关系。比如apple−apples ≈ car−cars, man−woman ≈ king – queen 等。这些方法都可以直接在大规模无标注语料上进行训练。词嵌入的质量也非常依赖于上下文窗口大小的选择。通常大的上下文窗口学到的词嵌入更反映主题信息,而小的上下文窗口学到的词嵌入更反映词的功能和上下文语义信息。
2、句向量
句子编码主要研究如何有效地从词嵌入通过不同方式的组合得到句子表示。其中,比较有代表性的方法有四种。
- (1)神经词袋模型
简单对文本序列中每个词嵌入进行平均/加总,作为整个序列的表示。
这种方法的缺点是丢失了词序信息。对于长文本,神经词袋模型比较有效。但是对于短文本,神经词袋模型很难捕获语义组合信息。
- (2)递归神经网络(Recursive Neural Network)
按照一个给定的外部拓扑结构(比如成分句法树),不断递归得到整个序列的表示。递归神经网络的一个缺点是需要给定一个拓扑结构来确定词和词之间的依赖关系,因此限制其使用范围。
- (3)循环神经网络(Recurrent Neural Network)
将文本序列看作时间序列,不断更新,最后得到整个序列的表示。
- (4)卷积神经网络(Convolutional Neural Network)
通过多个卷积层和子采样层,最终得到一个固定长度的向量。
在上述四种基本方法的基础上,很多研究者综合这些方法的优点,结合具体的任务,已经提出了一些更复杂的组合模型,例如双向循环神经网络(Bi-directional Recurrent Neural Network)、长短时记忆模型(Long-Short Term Memory)等。
同时根据上面的内容,句向量的表征在RNN、CNN之间,到底哪个更好呢? 有一篇文章在这点上讲得比较清楚,会在下面的延伸三:《NLP 模型到底选 RNN 还是 CNN?》提到。
3、篇章表示
如果处理的对象是比句子更长的文本序列(比如篇章),为了降低模型复杂度,一般采用层次化的方法,先得到句子编码,然后以句子编码为输入,进一步得到篇章的表示。具体的层次化可以采用以下几种方法:
- (1)层次化的卷积神经网络
即用卷积神经网络对每个句子进行建模,然后以句子为单位再进行一次卷积和池化操作,得到篇章表示。
- (2)层次化的循环神经网络
即用循环神经网络对每个句子进行建模,然后再用一个循环神经网络建模以句子为单位的序列,得到篇章表示。
- (3)混合模型
先用循环神经网络对每个句子进行建模,然后以句子为单位再进行一次卷积和池化操作,得到篇章表示。在上述模型中,循环神经网络因为非常适合处理文本序列,因此被广泛应用在很多自然语言处理任务上。
.
.
.
四、总结
基于深度学习的方法在自然语言处理中取得了很大的进展,因此,分散式表示也成为语言表示中最热门的方法,不但可以在特定的任务中端到端地学习字、词、句子、篇章的分散式表示,也可以通过大规模未标注文本自动学习。
分散式表示可以非常方便地应用在下游的各种自然语言处理任务上,并且可以端到端地学习,给研究者带来了很大的便利。但是分散式表示对以下几种情况还不能很好地处理,需要进一步解决。
- 语言中出现所有符号是否都需要使用统一的表示模型?比如,无意义的符号、变量、数字等。
- 新词以及低频词的表示学习方法。目前的表示学习方法很难对这些词进行很好的建模,而这些词都是极具信息量的,不能简单忽略。
- 篇章的语言表示。目前对篇章级别的文本进行建模方法比较简单,不足以表示篇章中的复杂语义。
- 语言表示的基础数据结构。除了目前的基于向量的数据结构之外是否有更好的表示结构,比如矩阵、队列、栈等。
.
.
延伸一:句向量的表示方式
参考blog:Sentence Embedding/Nishant Nikhil
在实际应用方面,可以参考google在2014发表的内容,对实际应用非常有帮助:Distributed Representations of Sentences and Documents
该博客较多是对分散表示词向量进行一定的总结与归纳。
1、词向量简单相加/平均(类似神经词袋模型)
对词向量的相加/平均,但是譬如以下的两句话质心是一致的:
You are going there to teach not play.
You are going there to play not teach
这样的方式,再来求句子距离,其实是在求句子的质心距离(centroid distance)。
另外一种改良版本,用Word Movers’ Distance

相近词之间求距离,然后把这样的相近距离相加。
参考paper1:From Word Embeddings To Document Distances
参考paper2:Using Centroids of Word Embeddings and Word Mover’s Distance for Biomedical Document Retrieval in Question Answering
.
.
2、深度学习方面
以上的方法并没有关照到句子的序列信息。
1、CNN
用CNN来句子表示(paper:Convolutional Neural Networks for Sentence Classification),操作流程是:
padding句子让其长度一致 -> 使用词表示技术成为方阵 -> 使用CNN -> 使用Max-overtime pooling -> 全连接层 -> 获得句向量。
2、GRU
Dynamic Memory Networks for Visual and Textual Question Answering
通过GRU进行编码,生成上下文向量+更新记忆。
当然还有用双向GRUs(Efficient Summarization With Read-Again And Copy Mechanism)
.
.
3、fasttext表示
可见NLP︱高级词向量表达(二)——FastText(简述、学习笔记)
.
.
延伸二:句向量表达:Sentence 2 vec
跟眼神一中词向量简单相加减类似,是通过PCA/SVD的加权得到了句向量,同时作者在实验过程中,发现这一表征方式,可以跟LSTM表征的效果媲美。
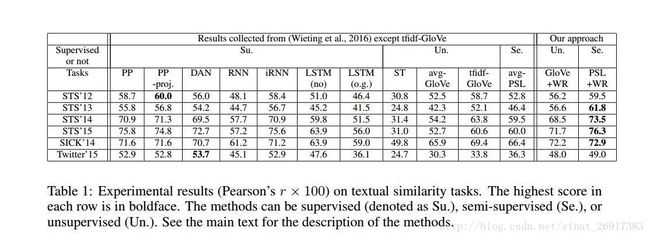
github地址:https://github.com/peter3125/sentence2vec
paper地址:《A SIMPLE BUT TOUGH-TO-BEAT BASELINE FOR SENTENCE EMBEDDINGS》
# test
embedding_size = 4 # dimension of the word embedding
w1 = Word('Peter', [0.1, 0.2, 0.3, 0.4])
w2 = Word('was', [0.2, 0.1, 0.3, 0.4])
w3 = Word('here', [0.1, 0.4, 0.1, 0.4])
sentence1 = Sentence([w1, w2, w3])
sentence2 = Sentence([w2, w3, w1])
sentence3 = Sentence([w3, w1, w2])
# calculate and display the result
print(sentence_to_vec([sentence1, sentence2, sentence3], embedding_size)).
延伸三:NLP 模型到底选 RNN 还是 CNN?
本文来源于文章《AI技术讲座精选:NLP 模型到底选 RNN 还是 CNN?》,不过实质上并没有得出非常建设性的答案。
paper地址:https://arxiv.org/pdf/1702.01923.pdf
CNN 是分层架构,RNN 是连续结构。一般靠常规直觉来判断:
- 倾向于为分类类型的任务选择 CNN,例如情感分类,因为情感通常是由一些关键词来决定的;
- 对于顺序建模任务,我们会选择 RNN,例如语言建模任务,要求在了解上下文的基础上灵活建模。
在实践中,得到的结论:
- CNN 和 RNN 为文本分类任务提供补充信息。至于哪个架构的执行效果更好一点,取决于对整个序列的语义理解的重要程度。
- 目前来看,RNN 在文本级别的情感分类表现得很好(Tang et al., 2015),对于LSTM,封闭的 CNN
在语言建模任务上同比 LSTM 更胜一筹 - RNN 表现较好并且在大范围内的任务中都较为稳健。除了以下种情况:当前的任务本质上是一项在一些情感探测和问答匹配设置中识别关键词的任务。
- 隐藏层尺寸hidden size和批尺寸batch size会使 DNN 的性能变得非常不稳定,波动较大,从实践来看这两个参数对结果的影响非常大。
.
延伸四:对词向量干预,可以提高效率
paper:All-but-the-Top: Simple and Effective Postprocessing for Word Representations
本文来源于paperweekly,《本周值得读(2017.02.06-2017.02.10)》
本文提出了一种对已有的词向量进行预处理的方法,用来对学习到的词向量降噪。基于词向量自身的几何结构 — 均值非零以及各项不同性,本文提出了一个反直观的处理方法:从所有的词向量中移除均值,以及移除部分导致各项不同性的方向。虽然这种处理方式忽略了词向量中的部分信息,但是它可以使多种通过不同方式训练出来的词向量加强词向量中包含的语义信息。经过预处理之后的词向量在一系列intrinsic衡量方式上(similarity, analogy, concept categorization)得到了一致性地提高。同时,我们通过了不同的应用上进行了测试,试验结果表明该预处理已经在诸多neural network中有所体现,进一步证实了对词向量进行预处理的重要性。
.
延伸五:NLP+Skip-Thoughts-Vectors︱基于TensorFlow的带语义特征的句向量编码方式
本篇转载于新智元,题为《TensorFlow 自动句子语义编码,谷歌开源机器学习模型
Skip-Thoughts》
笔者觉得是高层次的
github地址(新换):https://github.com/tensorflow/models/tree/master/research/skip_thoughts
Skip-Thoughts 模型概要
Skip-Thoughts 模型是一个句子编码器。它学习将输入的句子编码成固定维度的向量表示,这些向量表示能够对许多任务有用,例如检测释义,或对产品评论进行积极或消极的分类等等。有关模型架构和更多示例应用的详细信息,可以参阅Ryan Kiros 等人的 NIPS 论文 Skip-Thought Vectors。
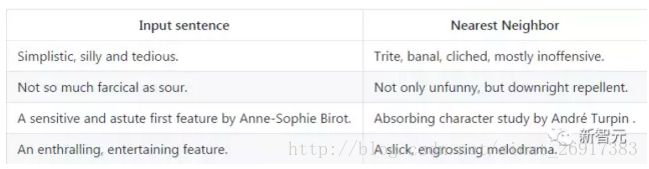
一个训练好的 Skip-Thoughts 模型会在嵌入的向量空间中对相互临近的相似句子进行编码。以下示例展示了对电影评论数据集中的一些句子的余弦相似性的最近邻域。
我们描述了一种通用、分布式句子编码器的无监督学习方法。使用从书籍中提取的连续文本,我们训练了一个编码器-解码器模型,试图重建编码段落周围的句子。语义和语法属性一致的句子因此被映射到相似的向量表示。我们接着引入一个简单的词汇扩展方法来编码不再训练预料内的单词,令词汇量扩展到一百万词。同时建立word2vec到skip-thoughts向量之间的映射关系。
在训练模型后,我们用线性模型在8个任务上提取和评估我们的向量,包括:语义相关性,释义检测,图像句子排序,问题类型归类,以及4个基准情绪和主观性数据集。最终的结果是一个非专门设计的编码器,能够生成高度通用性的句子表示,在实践中表现良好。
Skip-Thought 模型是 NIPS 2015论文 Skip-Thought Vectors 中描述的模型的一个 TensorFlow 实现,学习对句子的语义属性进行编码。
引用:Ryan Kiros, Yukun Zhu, Ruslan Salakhutdinov, Richard S. Zemel, Antonio Torralba, Raquel Urtasun, Sanja Fidler. Skip-Thought Vectors. In NIPS, 2015.
论文下载地址:https://papers.nips.cc/paper/5950-skip-thought-vectors.pdf

编码句子示例
该示例的句子来自电影评论数据集(Movie Review Data)。
ipython # Launch iPython.
In [0]:
# Imports.
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import numpy as np
import os.path
import scipy.spatial.distance as sd
from skip_thoughts import configuration
from skip_thoughts import combined_encoder
In [1]:
# Set paths to the model.
VOCAB_FILE = "/path/to/vocab.txt"
EMBEDDING_MATRIX_FILE = "/path/to/embeddings.npy"
CHECKPOINT_PATH = "/path/to/model.ckpt-9999"
# The following directory should contain files rt-polarity.neg and
# rt-polarity.pos.
MR_DATA_DIR = "/dir/containing/mr/data"
In [2]:
# Set up the encoder. Here we are using a single unidirectional model.
# To use a bidirectional model as well, call load_encoder() again with
# configuration.ModelConfig(bidirectional_encoder=True) and paths to the
# bidirectional model's files. The encoder will use the concatenation of
# all loaded models.
encoder = combined_encoder.CombinedEncoder()
encoder.load_encoder(configuration.ModelConfig(),
vocabulary_file=VOCAB_FILE,
embedding_matrix_file=EMBEDDING_MATRIX_FILE,
checkpoint_path=CHECKPOINT_PATH)
In [3]:
# Load the movie review dataset.
data = []
with open(os.path.join(MR_DATA_DIR, 'rt-polarity.neg'), 'rb') as f:
data.extend([line.decode('latin-1').strip() for line in f])
with open(os.path.join(MR_DATA_DIR, 'rt-polarity.pos'), 'rb') as f:
data.extend([line.decode('latin-1').strip() for line in f])
In [4]:
# Generate Skip-Thought Vectors for each sentence in the dataset.
encodings = encoder.encode(data)
In [5]:
# Define a helper function to generate nearest neighbors.
def get_nn(ind, num=10):
encoding = encodings[ind]
scores = sd.cdist([encoding], encodings, "cosine")[0]
sorted_ids = np.argsort(scores)
print("Sentence:")
print("", data[ind])
print("\nNearest neighbors:")
for i in range(1, num + 1):
print(" %d. %s (%.3f)" %
(i, data[sorted_ids[i]], scores[sorted_ids[i]]))
In [6]:
# Compute nearest neighbors of the first sentence in the dataset.
get_nn(0)输出:
Sentence:
simplistic , silly and tedious .
Nearest neighbors:
1. trite , banal , cliched , mostly inoffensive . (0.247)
2. banal and predictable . (0.253)
3. witless , pointless , tasteless and idiotic . (0.272)
4. loud , silly , stupid and pointless . (0.295)
5. grating and tedious . (0.299)
6. idiotic and ugly . (0.330)
7. black-and-white and unrealistic . (0.335)
8. hopelessly inane , humorless and under-inspired . (0.335)
9. shallow , noisy and pretentious . (0.340)
10. . . . unlikable , uninteresting , unfunny , and completely , utterly inept . (0.346)延伸六:Doc2Vec的情感分析以及相似性
Tutorial for Sentiment Analysis using Doc2Vec in gensim (or “getting 87% accuracy in sentiment analysis in under 100 lines of code”)
github:https://github.com/linanqiu/word2vec-sentiments
也可以用doc2vec来做相似性分析,其他办法有:
第一种方法,使用docsim;第二种办法,使用doc2vec;第三种方式:使用LSH。
博客里面也有code
详细可见:用docsim/doc2vec/LSH比较两个文档之间的相似度
.
延伸七:能够表征相似的:基于CNN的短文本表达模型及相似度计算的全新优化模型
来源:LSF-SCNN:一种基于CNN的短文本表达模型及相似度计算的全新优化模型
LSF-SCNN,即基于词汇语义特征的跳跃卷积模型 (Lexical Semantic Feature based Skip Convolution neural network ),基于卷积神经网络模型引入三种优化策略:词汇语义特征 (Lexical Semantic Feature, LSF)、跳跃卷积 (Skip Convolution, SC)和K-Max均值采样 (K-Max Average Pooling, KMA) ,分别在词汇粒度、短语粒度、句子粒度上抽取更加丰富的语义特征,从而更好的在向量空间构建短文本语义表达模型,并广泛的适用于问答系统 (question answering)、释义识别 (paraphrase identification) 和文本蕴含 (textual entailment)等计算成对儿出现的短文本的相似度的任务中。
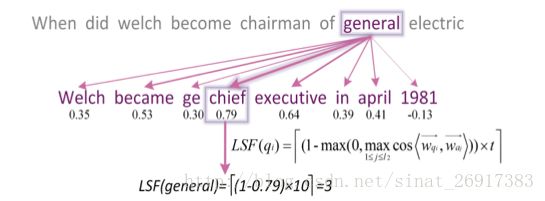
LSF特征怎样计算得到?
问题和答案中的每一个单词都会有一个LSF特征,具体来说是一个[0,t]上的整数值。LSF的计算过程可通过下面一个例子说明,当我们想要求解问题中general一词的LSF特征时,第一步我们需要计算general与答案中每一个词的余弦相似度并选取其中的最大值,因此chief被选取出来。第二步,余弦相似度值的最大值0.79将通过一个映射函数映射为一个[0,t]区间的整数,当我们假定t=10,最终计算得到general的LSF特征为3。这是合理的,general和chief一定程度上是近义词。
.
延伸八:473个模型试验告诉你文本分类中的最好编码方式
论文地址:https://arxiv.org/pdf/1708.02657.pdf
来源机器之心:学界 473个模型试验告诉你文本分类中的最好编码方式
本论文实证研究了在文本分类模型中汉语、日语、韩语(CJK)和英语的不同编码方式。该研究讨论了不同层面的编码,包括 UTF-8 bytes、字符级和词汇级。对于所有的编码层面,我们都提供了线性模型、fastText (Joulin et al., 2016) 和卷积网络之间的对比。对于卷积网络,我们使用字符字形(character glyph)图像、one-hot(或 one-of-n)编码和嵌入方法比较了不同的编码机制。总的来说,该实验涉及 473 个模型,并使用了四种语言(汉语、英语、日语和韩语)的 14 个大规模文本分类数据集。该研究所得出来的一些结论:基于 UTF-8 字节层面的 one-hot 编码在卷积网络中始终生成优秀结果;词层面的 N 元线性模型即使不能完美地分词,它也有强大的性能;fastText 使用字符层面的 N 元模型进行编码取得了最好的性能,但当特征太多时容易过拟合。
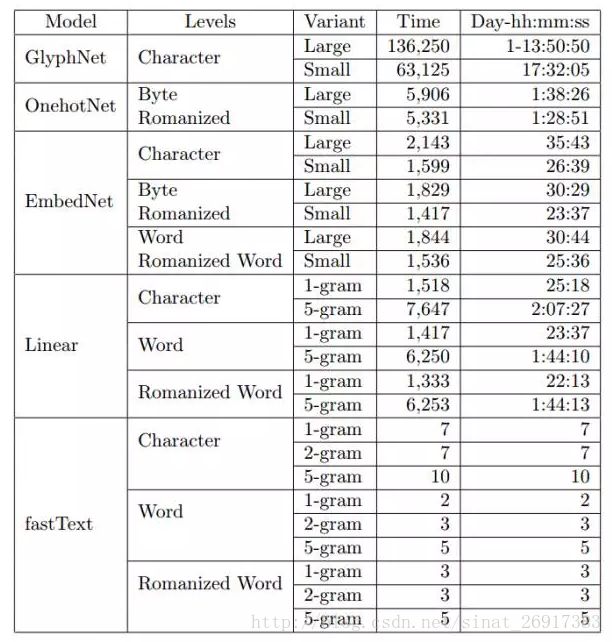
通过比较以上表格中的误差率,作者得出以下结论:
- 1、fastText模型对中、日、韩文本(CJK语言文本)在character级编码的处理结果更好;而对英语文本则在word级编码的处理结果更好;
- 2、对于fastText和线性模型,CJK语言的word级编码在没有完美分割的情况下效果相当;
- 3、卷积网络的最佳编码机制是byte级独热编码(byte-level one-hot encoding)。
这表明卷积网络能够从低级别的表示中理解文本,并提供了一致的和统一的方式来处理多种语言。 - 4、fastText相比于卷积网络更倾向于过拟合,而相比于线形模型也并没有表现出更多的表示能力(representation
capacity)。
当然,尽管作者在此列了473种模型进行对比,但仍不是全部。例如深度学习模型本文只用了卷积网络模型,但其实还有别的一些有意思的模型,例如周期性网络(recurrent networks)等。作者似乎计划在之后会对周期性网络进行研究,同时还会改进卷积网络模型,看会有什么样的效果。