keras&tensorflow+分布式训练︱实现简易视频内容问答框架
内容来源:Keras 之父讲解 Keras:几行代码就能在分布式环境训练模型
把 Keras API 直接整合入 TensorFlow 项目中,这样能与你的已有工作流无缝结合。至此,Keras 成为了
TensorFlow 内部的一个新模块:tf.keras,它包含完整的 Keras API。用 Keras API 定义模型,用
TensorFlow estimator 和 experiments 在分布式环境训练模型。
我们有一组 10 秒短视频组成的数据集,视频内容是人从事各种活动。一个深度学习模型将会观察这些视频的每一帧画面,进行理解,然后你可以用简短的自然语言问它视频内容。

本例子中,一个男人把纸板箱放进车的行李箱里。任务是回答这个人在做什么。模型会处理该视频和问题,试图在可能的答案中挑选出正确的那一个。这次,它的回答是 “装货”。这个答案很有意思:如果仅仅看一帧画面,是得不出该结论的——这个人也有可能在卸货。所以,我们不仅要求模型能理解视频画面的内容,还要能理解每一帧画面的先后顺序。
放到三四年前,Keras 和 TensorFlow 诞生之前,这会是一个无比棘手的难题,全世界只有个位数的研究机构能处理。即便是一只由世界级专家学者、工程师组成的团队,也需要半年左右的时间来一点一点解决。而现在,所有具备基础 Python 编程技能的人都能借助工具处理该问题。我们这也是在使深度学习民主化。
下图便是我们的神经网络方案。它的结构可分为三个部分:
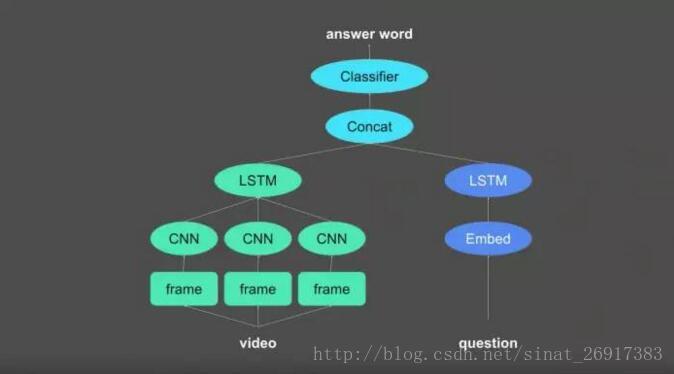
首先,一个分支会导入视频输入,把它转化为对视频内容编码的矢量。另一个分支导入问题,也把它转化为矢量。现在,你可以把视频矢量和问题矢量连结起来,在它们之上添加一个分类器。该分类器的任务,是从一堆潜在回答中,选出正确的那一个。
第一步,是把视频输入矢量转化为张量。一个视频只是一组连续的画面帧,每一帧都是一个图像。对于图像处理,你要做的全部的事,就是运行一个 CNN。
每个 CNN,会从每帧画面提取一个矢量表示。最后所得到的,是对每帧画面进行编码的矢量序列。当遇到一个序列,你会做什么?当然是用序列处理模块—— LSTM 把它跑一遍。LSTM 会把序列简化为一个单一矢量,该矢量编码了视频的所有信息,包括每一帧画面、以及它们的顺序。
下一步,使用类似的过程来处理问句。它是一个由词语组成的序列,需要用内嵌模块把每个词语映射为一个词矢量。你就获得了一个词向量序列,再用另一个 LSTM 层来简化。
当视频、问题的矢量表示都有了以后,就可以把它们连接起来,在上面添加一个用于选择正确答案的分类器。
这就是深度学习的魔力:把复杂的输入,比如视频、图像、语言、声音变成矢量,变成几何空间中的不同的点——把了信息变成了几何空间中的点,这就是深度学习的本质。
而当完成之后,你就可以用线性代数来处理几何空间,捕捉到到有趣的映射模式。在上面的例子中,该模型就是在学习一个视频、问题空间到答案空间的映射。而执行的方式,是把不同的信息处理模块组合起来。这是一个十分自然的操作:对象是图像,就用图像处理模块 CNN;对象是序列,就用序列处理模块 LSTM;如果需要从一组候选中选择一个,就用分类器。
因而,创建深度学习模型,在概念上和拼乐高积木是很相似的,前者的实现也应该这么简单。这张图,就是对我们的模型在 Keras 上的直观结构。

我们用一个按时间分布的层,把 CNN 应用于由输入视频和张量组成的时间轴上的每一帧画面。然后把输入导入 LSTM 层,前者被简化为单一张量。InceptionV3 CNN 会内置预训练的权重,这一点很重要,因为以目前的视频输入,靠我们自己是无法学习到有趣的视觉特征的。我们需要利用现有的、在大型数据集上学习到的视觉特征。这个例子里是 ImageNet。在深度学习里,这是一个常见的举措,而 Keras 使它变得更方便。问题的编码更加简单。把词语序列导入内嵌层(embedding layer),生成矢量序列,再用 LSTM 层简化为单一矢量。
.
代码演示
下面是视频编码机器人的完整代码,加起来只有几行,非常简洁。你从确认视频输入开始,高亮部分就是你的视频输入:
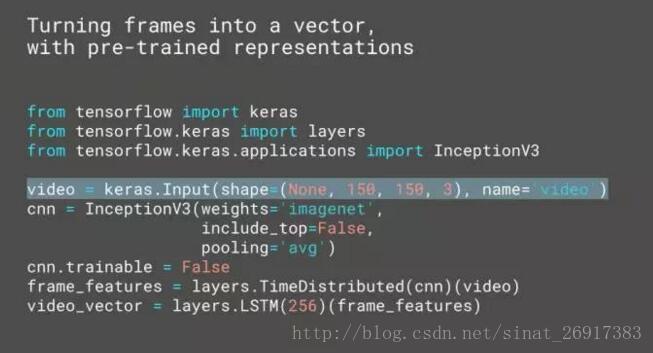
这是一个由合理帧数组成的序列。“None” 就是帧数,它没有被定义,你可以不同的 batch 进行修改。每一帧画面的分辨率是 150*150。下一步,仅用一行我们就定义了整个 InceptionV3 模型。它装满了从 ImageNet 得到的预训练权重。所有这些已经内置于 Keras 中,你不需要做任何多余操作,仅此一行代码足矣。代码并不包含顶层,因为并不相关,但在顶部加入了 pooling,使得我们能从每一帧抓取一个矢量。
下一步,CNN 被设置为不可训练,意味它的参数表示并不会在训练中更新。这一步很重要,因为该 CNN 已经有了非常不错的表示,没必要更改。再强调一遍,这是深度学习的常用操作,把封住不再改动的预训练模型添加入流水线。在 Keras 中,这项操作变得十分简便。有了不再变动的 CNN 之后,我们用一个时间分配层(time distributed layer),把它在视频输入的时间轴上均衡分配。这样做的结果,是得到所有帧的张量,再导入 LSTM 层得到单一矢量。

如上图,问题处理就更加简单。最终的问题输入,被处理为整数序列。为什么是整数呢?每一个整数,都会用某些词汇映射到一个矢量。随后把整数序列导入嵌入层,这会把每个整数映射到一个矢量上。这些训练过的嵌入是模型的一部分。再把矢量序列导入 LSTM,简化为单一矢量。
这里有一个有意思的地方。通常使用 LSTM 的时候,有许多东西需要考虑、许多套路需要参考。但在这里,除了设置输入单位的数量,我们并没有做任何其他操作配置 LSTM 层——所有 “最佳套路”,都已经成为 Keras 的默认设置。这是 Keras 的一大特点,已知的最佳方案被用于默认设置。对于开发者,这意味着模型直接就能用,不需要对所有参数都进行调参。
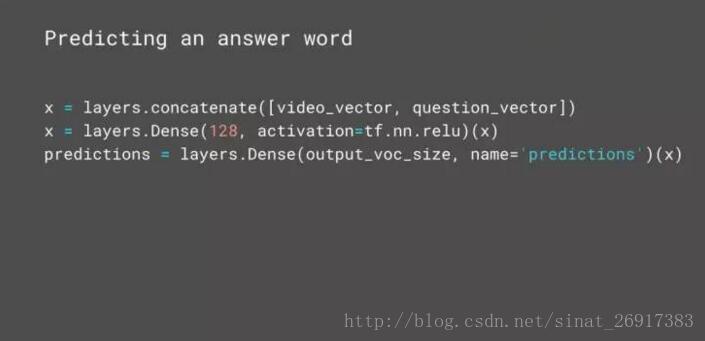
在完成对视频、问题的编码之后,你只需要用 concate up 把它们转化为单一矢量,然后在顶端加入两个密集层,它们会从备选词汇中选出一个作为答案。
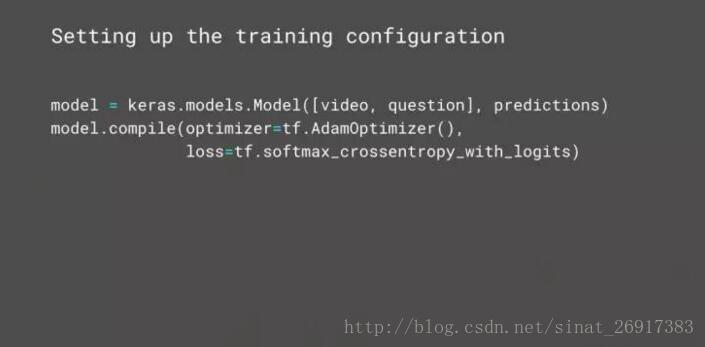
下一步,使用输入和输出初始化 Keras 模型,本质上它是一个神经网络各层的图(a graph of layers)的容器。然后要确定训练设置,比如优化器、Adam 优化器和损失函数。到现在一切都很简单,我们已经定义了模型和训练设置。下面是在分布式环境训练模型,或许在 Cloud ML 上。

只用几行代码,你就可以用 TensorFlow Estimator 和 Experiment 类训练模型。所有需要你做的事,仅仅是写 experiment 函数,用内置的 get_estimator 方法在其中定义模型,并用模型来初始化 Estimator。有了 estimator 之后,再用它创建 Experiment,在其中你确认输入数据。
仅仅用几行非常直观、具有高度可读性的 Python 代码就可以实现,我们就定义了一个相当先进的模型、在分布式环境训练它,来解决视频问答难题。而这在几年前是完全难以想象的。
到这里,你应该已经看到,像 Keras 这样的 API 是如何推动 AI 民主化。这借助两个东西实现:
其中一个,当然是 Keras API。为在 TensorFlow 中定义模型提供了易于使用、功能强大的工具。而且,每一层都有非常优秀的默认设置,让模型可以直接运行。
另外一个,则是全新的高级 TensorFlow 训练 API:Estimator 和 Experiment。
把它们结合到一起,使得开发者们能够以相当小的时间、经历代价处理任何深度学习难题。