keras系列︱seq2seq系列相关实现与案例(feedback、peek、attention类型)
之前在看《Semi-supervised Sequence Learning》这篇文章的时候对seq2seq半监督的方式做文本分类的方式产生了一定兴趣,于是开始简单研究了seq2seq。先来简单说一下这篇paper的内容:
创立的新形式Sequence AutoEncoder LSTM(SA-LSTM),Pre-trained RNNs are more stable, generalize better, and achieve state-of-the-art results on various text classification tasks. The authors show that unlabeled data can compensate for a lack of labeled data(来源dennybritz/deeplearning-papernotes).

创新之处:
- (1)第一种模型Sequence autoencoder(SA-LSTM):The objective is to reconstruct the input sequence itself,其中output序列就是Input序列,输出的结果作为下一个LSTM的初始值
- (2)第二种模型称为Language Model LSTM(LM-LSTM),encoder部分去掉就是LM模型。
- (3)jointly training模式.一般用LSTM中的最后一个hidden state作为输出,但本文也尝试用了每个hidden state权重递增的线性组合作为输出。
这两种思路都是将无监督和有监督分开训练,本文也提供了一种联合训练的思路作为对比,称为joint learning。
优势:
- (1)unsupervised,不用标签
- (2)large quantities of unlabeled data to improve its quality,不用标签之外,用大量无标注数据反而还可以增强模型的泛化能力
- (3)相较于LSTM的随机初始化,可以fine-tuning过来别的整个部分的weight作为初始化权重
想要阅读的童鞋可看原版论文 + 一份大牛的解读,当然作者好像没开源他的做法以及实验详细数据,笔者折腾了几天没做出效果也就放弃了….
.
一、seq2seq几类常见架构
不累述seq2seq的原理,来看看《漫谈四种神经网络序列解码模型【附示例代码】》中总结的四类:
1、模式一:普通作弊 basic encoder-decoder
编码时RNN每个时刻除了自己上一时刻的隐层状态编码外,还有当前时刻的输入字符,而解码时则没有这种输入。那么,一种比较直接的方式是把编码端得到的编码向量做为解码模型的每时刻输入特征。如下图所示:
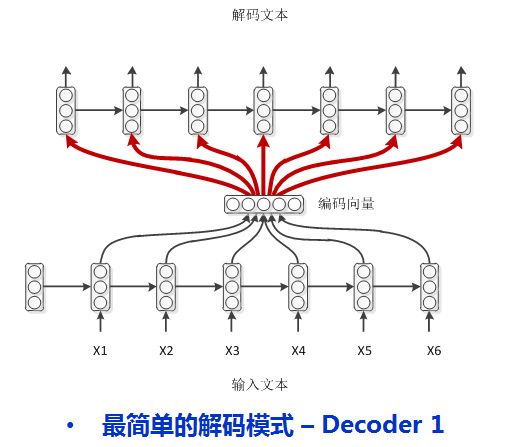
简单直观而且解码模型和编码模型并没有任何区别
.
2、模式二: 学霸模式 encoder-decoder with feedback
编码端则是对课本的理解所整理的课堂笔记。解码端的隐层神经网络则是我们的大脑,而每一时刻的输出则是考试时要写在卷子上的答案。在上面最简单的解码模型中,可以考虑成是考试时一边写答案一边翻看课堂笔记。如果这是一般作弊学生的做法,学霸则不需要翻书,他们有一个强大的大脑神经网络,可以记住自己的课堂笔记。解码时只需要回顾一下自己前面写过什么,然后依次认真的把答案写在答卷上,就是下面这种模型了:

.
3、模式三:学弱作弊 encoder-decoder with peek
很多学弱,他们不只需要作弊,而且翻看笔记的时候还需要回顾自己上一时刻写在答卷上的答案

.
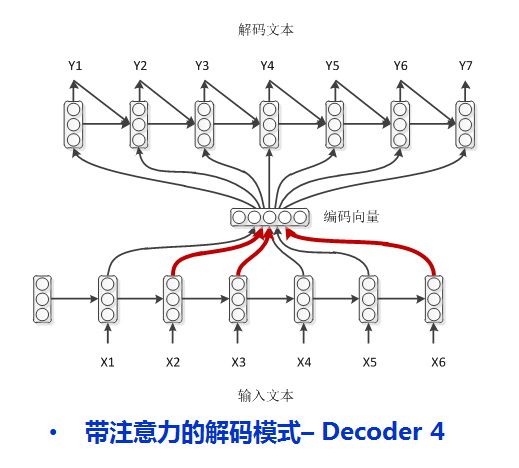
4、模式四:学渣作弊 encoder-decoder with attention
然而学渣渣也是存在的,他们不只需要作弊,不只需要回顾自己上一时刻卸载答卷上的答案,还需要老师在课本上画出重点才能整理出自己的课题笔记(这就是一种注意力机制Attention,记笔记的时候一定要根据考题画出重点啊!)
5、结果对比
设定一些参数如下:
(‘Vocab size:’, 51, ‘unique words’)
(‘Input max length:’, 5, ‘words’)
(‘Target max length:’, 5, ‘words’)
(‘Dimension of hidden vectors:’, 20)
(‘Number of training stories:’, 5)
(‘Number of test stories:’, 5)

.
二、seq2seq的实现
1、四类seq2seq实现-encoder_decoder
上述文章 《漫谈四种神经网络序列解码模型【附示例代码】》中总结的四类的实现在作者的github之中,由于作者用keras0.3做的,笔者在实践过程中遇到很多坑,而且py2与py3之间都会有各自的问题,所以这边只贴其输入输出的数据:
输入数据:
input_list
[['1', '2', '3', '4', '5'], ['6', '7', '8', '9', '10'], ['11', '12', '13', '14', '15'], ['16', '17', '18', '19', '20'], ['21', '22', '23', '24', '25']]tar_list
[['one', 'two', 'three', 'four', 'five'], ['six', 'seven', 'eight', 'nine', 'ten'], ['eleven', 'twelve', 'thirteen', 'fourteen', 'fifteen'], ['sixteen', 'seventeen', 'eighteen', 'nineteen', 'twenty'], ['twenty_one', 'twenty_two', 'twenty_three', 'twenty_four', 'twenty_five']]训练输入数据【en_de_model.fit(inputs_train, tars_train, batch_size=3, nb_epoch=1, show_accuracy=True)】:
inputs_train:5*5
array([[ 1, 12, 19, 20, 21],
[22, 23, 24, 25, 2],
[ 3, 4, 5, 6, 7],
[ 8, 9, 10, 11, 13],
[14, 15, 16, 17, 18]], dtype=int32)tars_train:5*5*51(51为单词个数 + 1)
array([[[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, True],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False]],
[[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False]],
[[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False]],
[[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False]],
[[False, False, False, ..., False, False, False],
[False, False, False, ..., False, True, False],
[False, False, False, ..., True, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False]]], dtype=bool)
来看一个完整的keras0.3版本的code:
decoder_mode = 1 # 0 最简单模式,1 [1]向后模式,2 [2] Peek模式,3 [3]Attention模式
# encoder部分
if decoder_mode == 3:
encoder_top_layer = LSTM(hidden_dim, return_sequences=True)
else:
encoder_top_layer = LSTM(hidden_dim)
# decoder部分
if decoder_mode == 0:
decoder_top_layer = LSTM(hidden_dim, return_sequences=True)
decoder_top_layer.get_weights()
elif decoder_mode == 1:
decoder_top_layer = LSTMDecoder(hidden_dim=hidden_dim, output_dim=hidden_dim
, output_length=tar_maxlen, state_input=False, return_sequences=True)
elif decoder_mode == 2:
decoder_top_layer = LSTMDecoder2(hidden_dim=hidden_dim, output_dim=hidden_dim
, output_length=tar_maxlen, state_input=False, return_sequences=True)
elif decoder_mode == 3:
decoder_top_layer = AttentionDecoder(hidden_dim=hidden_dim, output_dim=hidden_dim
, output_length=tar_maxlen, state_input=False, return_sequences=True)
# 模型构建
en_de_model = Sequential()
en_de_model.add(Embedding(input_dim=vocab_size,
output_dim=hidden_dim,
input_length=input_maxlen))
en_de_model.add(encoder_top_layer)
if decoder_mode == 0:
en_de_model.add(RepeatVector(tar_maxlen))
en_de_model.add(decoder_top_layer)
en_de_model.add(TimeDistributedDense(output_dim))
en_de_model.add(Activation('softmax'))
en_de_model.compile(loss='categorical_crossentropy', optimizer='rmsprop')
en_de_model.fit(inputs_train, tars_train, batch_size=3, nb_epoch=1, show_accuracy=True)其中遇到的报错:
from keras import activations, initializers # py3要这么写
from keras import activations, initializations # py2要这么写TypeError: build() takes exactly 1 argument (2 given) # py2无此报错.
2、keras实现farizrahman4u/seq2seq
本github里面用Keras做的seq2seq封装比较好,使用的方法有点类似上述的模式二.
8个月前有更新,其中还有一个练习案例可见:Training Seq2seq with movie subtitles - Thanks to Nicolas Ivanov 【20180716 添】
其中有5款seq2seq款式可以选择:
(1)A simple Seq2Seq model
import seq2seq
from seq2seq.models import SimpleSeq2Seq
model = SimpleSeq2Seq(input_dim=5, hidden_dim=10, output_length=8, output_dim=8)
model.compile(loss='mse', optimizer='rmsprop')(2)Deep Seq2Seq models
depth=3(效果为3 + 3 = 6)或者也可设置深度为(4, 5)
import seq2seq
from seq2seq.models import SimpleSeq2Seq
model = SimpleSeq2Seq(input_dim=5, hidden_dim=10, output_length=8, output_dim=8, depth=3)
model.compile(loss='mse', optimizer='rmsprop')(3)Advanced Seq2Seq models
import seq2seq
from seq2seq.models import Seq2Seq
model = Seq2Seq(batch_input_shape=(16, 7, 5), hidden_dim=10, output_length=8, output_dim=20, depth=4)
model.compile(loss='mse', optimizer='rmsprop')(4)Peeky Seq2seq model
the decoder gets a ‘peek’ at the context vector at every timestep.
打开peek=True,类似于上述的模式三
import seq2seq
from seq2seq.models import Seq2Seq
model = Seq2Seq(batch_input_shape=(16, 7, 5), hidden_dim=10, output_length=8, output_dim=20, depth=4, peek=True)
model.compile(loss='mse', optimizer='rmsprop')(5)AttentionSeq2Seq
类似于模式四,带注意力机制
import seq2seq
from seq2seq.models import AttentionSeq2Seq
model = AttentionSeq2Seq(input_dim=5, input_length=7, hidden_dim=10, output_length=8, output_dim=20, depth=4)
model.compile(loss='mse', optimizer='rmsprop')来看一个案例:
def test_Seq2Seq():
x = np.random.random((samples, input_length, input_dim))
y = np.random.random((samples, output_length, output_dim))
models = []
models += [Seq2Seq(output_dim=output_dim, hidden_dim=hidden_dim, output_length=output_length, input_shape=(input_length, input_dim))]
models += [Seq2Seq(output_dim=output_dim, hidden_dim=hidden_dim, output_length=output_length, input_shape=(input_length, input_dim), peek=True)]
models += [Seq2Seq(output_dim=output_dim, hidden_dim=hidden_dim, output_length=output_length, input_shape=(input_length, input_dim), depth=2)]
models += [Seq2Seq(output_dim=output_dim, hidden_dim=hidden_dim, output_length=output_length, input_shape=(input_length, input_dim), peek=True, depth=2)]
for model in models:
model.compile(loss='mse', optimizer='sgd')
model.fit(x, y, epochs=1)
model = Seq2Seq(output_dim=output_dim, hidden_dim=hidden_dim, output_length=output_length, input_shape=(input_length, input_dim), peek=True, depth=2, teacher_force=True)
model.compile(loss='mse', optimizer='sgd')
model.fit([x, y], y, epochs=1)其中遇到以下报错:
执行:
SimpleSeq2Seq(Input(shape=(5,), dtype='int32'), hidden_dim=10, output_length=8, output_dim=8)
报错:
/home/amax/.local/lib/python2.7/site-packages/keras/engine/topology.py:1513: UserWarning: Model inputs must come from a Keras Input layer,
they cannot be the output of a previous non-Input layer. Here,
a tensor specified as input to "model_86" was not an Input tensor, it was generated by layer dropout_17.
Note that input tensors are instantiated via `tensor = Input(shape)`.其中dropout设置不正确,加入dropout=0.3就可以执行
ValueError: Shape must be rank 2 but is rank 3 for 'lambda_272/MatMul' (op: 'MatMul') with input shapes: [?,2], [?,2,2].笔者之前一直用py2,改用了py3后就无报错了
.
3、keras自实现seq2seq:Pig Latin——Linusp/soph
本节参考博文《使用 Keras 实现简单的 Sequence to Sequence 模型》 相关code可见:github
train_x 和 train_y 必须是 3-D 的数据
直接上案例:
from keras.models import Sequential
from keras.layers.recurrent import LSTM
from keras.layers.wrappers import TimeDistributed
from keras.layers.core import Dense, RepeatVector
def build_model(input_size, seq_len, hidden_size):
"""建立一个 sequence to sequence 模型"""
model = Sequential()
model.add(GRU(input_dim=input_size, output_dim=hidden_size, return_sequences=False))
model.add(Dense(hidden_size, activation="relu"))
model.add(RepeatVector(seq_len))
model.add(GRU(hidden_size, return_sequences=True))
model.add(TimeDistributed(Dense(output_dim=input_size, activation="linear")))
model.compile(loss="mse", optimizer='adam')
return model- Encoder(即第一个 LSTM) 只在序列结束时输出一个语义向量,所以其 “return_sequences” 参数设置为 “False”
- Decoder(即第二个 LSTM) 需要在每一个 time step 都输出,所以其 “return_sequences” 参数设置为 “True”
- 使用 “RepeatVector” 将 Encoder 的输出(最后一个 time step)复制 N 份作为 Decoder 的 N 次输入
- TimeDistributed 是为了保证 Dense 和 Decoder 之间的一致,可以不用太关心
之所以说是 “简单的 seq2seq 模型”,就在于第 3 点其实并不符合两篇论文的模型要求,不过要将 Decoder 的每一个时刻的输出作为下一个时刻的输入,会麻烦很多,所以这里对其进行简化,但用来处理 Pig Latin 这样的简单问题,这种简化问题是不大的。
另外,虽然 seq2seq 模型在理论上是能学习 “变长输入序列-变长输出序列” 的映射关系,但在实际训练中,Keras 的模型要求数据以 Numpy 的多维数组形式传入,这就要求训练数据中每一条数据的大小都必须是一样的。针对这个问题,现在的常规做法是设定一个最大长度,对于长度不足的输入以及输出序列,用特殊的符号进行填充,使所有输入序列的长度保持一致(所有输出序列长度也一致)。
from keras.layers.recurrent import GRUfrom keras.layers.wrappers import TimeDistributedfrom keras.models import Sequential, model_from_jsonfrom keras.layers.core import Dense, RepeatVector def build_model(input_size, seq_len, hidden_size):
"""建立一个 sequence to sequence 模型"""
model = Sequential()
model.add(GRU(input_dim=input_size, output_dim=hidden_size, return_sequences=False))
model.add(Dense(hidden_size, activation="relu"))
model.add(RepeatVector(seq_len))
model.add(GRU(hidden_size, return_sequences=True))
model.add(TimeDistributed(Dense(output_dim=input_size, activation="linear")))
model.compile(loss="mse", optimizer='adam')
return model上面是一个最简单的 seq2seq 模型,因为没有将 Decoder 的每一个时刻的输出作为下一个时刻的输入。
.
三、tensorflow实现seq2seq的相关案例
1、seq2seq简单实现
相关github: https://github.com/ichuang/tflearn_seq2seq
来简单看看实现:
输入:0 1 2 3 4 5 6 7 8 9
输出:prediction=[8 8 5 3 6 5 4 2 3 1] (expected=[9 8 7 6 5 4 3 2 1 0])
[TFLearnSeq2Seq] model weights loaded from t2s__basic__sorted_1.tfl
==> For input [9, 8, 7, 6, 5, 4, 3, 2, 1, 2, 5, 1, 8, 7, 7, 3, 9, 1, 4, 6], prediction=[1 1 1 2 2 3 3 4 4 5 5 6 6 7 7 7 7 8 8 8] (expected=[1 1 1 2 2 3 3 4 4 5 5 6 6 7 7 7 8 8 9 9])2、自动标题生成案例
tensorflow实现的中文自动标题生成案例可见:https://github.com/rockingdingo/deepnlp/tree/master/deepnlp/textsum
textsum基于tensorflow (1.0.0) 实现的Seq2Seq-attention模型, 来解决中文新闻标题自动生成的任务。
Example:
Output examples
news: 中央 气象台 TAG_DATE TAG_NUMBER 时 继续 发布 暴雨 蓝色 预警 TAG_NAME_EN 预计 TAG_DATE TAG_NUMBER 时至 TAG_DATE TAG_NUMBER 时 TAG_NAME_EN 内蒙古 东北部 、 山西 中 北部 、 河北 中部 和 东北部 、 京津 地区 、 辽宁 西南部 、 吉林 中部 、 黑龙江 中部 偏南 等 地 的 部分 地区 有 大雨 或 暴雨 。
headline: 中央 气象台 发布 暴雨 蓝色 预警 华北 等 地 持续 暴雨
news: 美国 科罗拉多州 山林 大火 持续 肆虐 TAG_NAME_EN 当地 时间 TAG_DATE 横扫 州 内 第二 大 城市 科罗拉多斯 普林斯 一 处 居民区 TAG_NAME_EN 迫使 超过 TAG_NUMBER TAG_NAME_EN TAG_NUMBER 万 人 紧急 撤离 。 美国 正 值 山火 多发 季 TAG_NAME_EN 现有 TAG_NUMBER 场 山火 处于 活跃 状态 。
headline: 美国 多地 山火 致 TAG_NUMBER 人 死亡
参考自:seq2seq 的 keras 实现