Self-Attention Generative Adversarial Networks解读+部分代码
引言
这篇是文章是Ian goodfellow他们的新工作,在GAN中引入Attention。
在文章的摘要中作者主要突出了三点。
Self-Attention Generative Adversarial Network(SAGAN)是一个注意力驱动,长范围 关联模型(attention-driven, long-range dependency modeling )。
传统的GAN在生成高分辨率的细节时,是基于低分辨率的feature map中的某一个小部分的。而SAGAN是基于所有的特征点(all feature locations).
在训练时使用了光谱归一化(spectral normalization )来提升训练强度(training dynamics)。
SAGAN的优势
- 可以很好的处理长范围、多层次的依赖(可以很好的发现图像中的依赖关系)
- 生成图像时每一个位置的细节和远端的细节协调好
- 判别器还可以更准确地对全局图像结构实施复杂的几何约束
因为文章提到了long range 所以这里的远端,个人的理解是前几层卷积的output。
SAGAN
作者提到,大多数的GAN都使用了卷积,但是在处理long range依赖时,卷积的效率很低,所以他们采用了non-local model
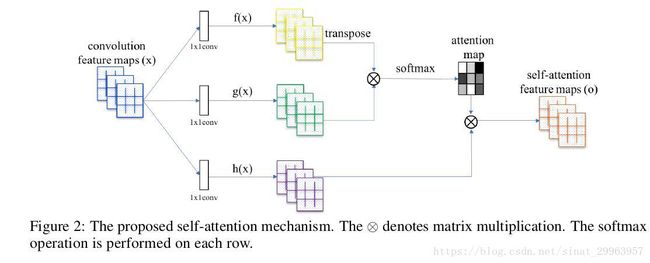

x 被送入两个特征空间f,g去计算attention。

Bij 表示在生成第j个区域时,是否关注第i个位置。
![]()
上面是每个可学习矩阵的纬度,都是用1X1卷积实现的。
![]()
在文章的所有实验中都用到了上面这个超参。
之后再带权相加,得到融合了attention的feature map

γ的值初始化为0,这是因为在最开始,只需要依赖于局部信息,之后在慢慢增大权重加入non-local evidence.
在训练过程中还使用了光谱归一化(spectral normalization)和two-timescale update rule(TTUR)来稳定训练。
部分代码
attention 具体实现
def attention(self, x, ch, sn=False, scope='attention', reuse=False):
with tf.variable_scope(scope, reuse=reuse):
f = conv(x, ch // 8, kernel=1, stride=1, sn=sn, scope='f_conv') # [bs, h, w, c']
g = conv(x, ch // 8, kernel=1, stride=1, sn=sn, scope='g_conv') # [bs, h, w, c']
h = conv(x, ch, kernel=1, stride=1, sn=sn, scope='h_conv') # [bs, h, w, c]
# N = h * w
s = tf.matmul(hw_flatten(g), hw_flatten(f), transpose_b=True) # # [bs, N, N]
beta = tf.nn.softmax(s, axis=-1) # attention map
o = tf.matmul(beta, hw_flatten(h)) # [bs, N, C]
gamma = tf.get_variable("gamma", [1], initializer=tf.constant_initializer(0.0))
o = tf.reshape(o, shape=x.shape) # [bs, h, w, C]
x = gamma * o + x
return x
生成器
def generator(self, z, is_training=True, reuse=False):
with tf.variable_scope("generator", reuse=reuse):
ch = 1024
x = deconv(z, channels=ch, kernel=4, stride=1, padding='VALID', use_bias=False, sn=self.sn, scope='deconv')
x = batch_norm(x, is_training, scope='batch_norm')
x = relu(x)
for i in range(self.layer_num // 2):
if self.up_sample:
x = up_sample(x, scale_factor=2)
x = conv(x, channels=ch // 2, kernel=3, stride=1, pad=1, sn=self.sn, scope='up_conv_' + str(i))
x = batch_norm(x, is_training, scope='batch_norm_' + str(i))
x = relu(x)
else:
x = deconv(x, channels=ch // 2, kernel=4, stride=2, use_bias=False, sn=self.sn, scope='deconv_' + str(i))
x = batch_norm(x, is_training, scope='batch_norm_' + str(i))
x = relu(x)
ch = ch // 2
# Self Attention
x = self.attention(x, ch, sn=self.sn, scope="attention", reuse=reuse)
for i in range(self.layer_num // 2, self.layer_num):
if self.up_sample:
x = up_sample(x, scale_factor=2)
x = conv(x, channels=ch // 2, kernel=3, stride=1, pad=1, sn=self.sn, scope='up_conv_' + str(i))
x = batch_norm(x, is_training, scope='batch_norm_' + str(i))
x = relu(x)
else:
x = deconv(x, channels=ch // 2, kernel=4, stride=2, use_bias=False, sn=self.sn, scope='deconv_' + str(i))
x = batch_norm(x, is_training, scope='batch_norm_' + str(i))
x = relu(x)
ch = ch // 2
if self.up_sample:
x = up_sample(x, scale_factor=2)
x = conv(x, channels=self.c_dim, kernel=3, stride=1, pad=1, sn=self.sn, scope='G_conv_logit')
x = tanh(x)
else:
x = deconv(x, channels=self.c_dim, kernel=4, stride=2, use_bias=False, sn=self.sn, scope='G_deconv_logit')
x = tanh(x)
return x
判别器
def discriminator(self, x, is_training=True, reuse=False):
with tf.variable_scope("discriminator", reuse=reuse):
ch = 64
x = conv(x, channels=ch, kernel=4, stride=2, pad=1, sn=self.sn, use_bias=False, scope='conv')
x = lrelu(x, 0.2)
for i in range(self.layer_num // 2):
x = conv(x, channels=ch * 2, kernel=4, stride=2, pad=1, sn=self.sn, use_bias=False, scope='conv_' + str(i))
x = batch_norm(x, is_training, scope='batch_norm' + str(i))
x = lrelu(x, 0.2)
ch = ch * 2
# Self Attention
x = self.attention(x, ch, sn=self.sn, scope="attention", reuse=reuse)
for i in range(self.layer_num // 2, self.layer_num):
x = conv(x, channels=ch * 2, kernel=4, stride=2, pad=1, sn=self.sn, use_bias=False, scope='conv_' + str(i))
x = batch_norm(x, is_training, scope='batch_norm' + str(i))
x = lrelu(x, 0.2)
ch = ch * 2
x = conv(x, channels=4, stride=1, sn=self.sn, use_bias=False, scope='D_logit')
return x
更多细节请参考SAGAN
上面贴的代码是 tensorflow版的没有用spectral normalization。
这个pytorch版使用了spectral normalization。
spectral normalization的具体实现可以看这里