【论文学习总结】Shape Robust Text Detection with Progressive Scale Expansion Network
推荐学习理由:旷世18年6月提出的PSENET,论文被CVPR2019接收。整体上沿用主流的像素的语义分割的方法,提出利用不同尺寸的shrinking产生文本“核”再用渐进的尺度扩展算法来有效区分相邻文本。作者在19年3月重新发布论文,并正式开源了代码。在FMeasure指标上,ICDAR2015获得了87.21(resnet152),在ICDAR2017 MLT获得了72.45(resnet152).
代码:
https://github.com/whai362/PSENet(作者复现pytorch版本)
https://github.com/liuheng92/tensorflow_PSENet(他人复现tf版本)
参考:
https://arxiv.org/abs/1903.12473
https://arxiv.org/abs/1806.02559
https://blog.csdn.net/liuxiaoheng1992/article/details/87646951
https://blog.csdn.net/weixin_43624538/article/details/88630494
https://blog.csdn.net/qq_19655645/article/details/88949796
https://www.wengbi.com/thread_77336_1.html
一、整体介绍:
PSENET沿用主流的像素的语义分割的方法,同样采用U形的网络框架,但并没有像EAST和pixel-Anchor那样回归bounding box的顶点和角度,而是纯粹地使用更多通道的融合像素特征图来预测每个像素是否为文本实例,使多方向文字和扭曲文字的检测均适用。文章的两个亮点在于:1、基于shrinking方法提出利用多个不同尺寸大小的文本“核”(易于预测和分割),逐步向外扩展得到文本实例(不受文本形状限制);2、基于宽度优先搜索(BFS)提出利用渐进的尺度扩展算法来解决临近文本实例的分割问题。整体上看结构清晰优雅,易于理解。在FMeasure指标上,ICDAR2015获得了87.21(resnet152),在ICDAR2017 MLT获得了72.45(resnet152)。 作者在18年6月发布了论文,在19年3月进行了更新,在原版基础上补充了更多的实验部分,因此阅读最新的论文即可。
二、网络结构:
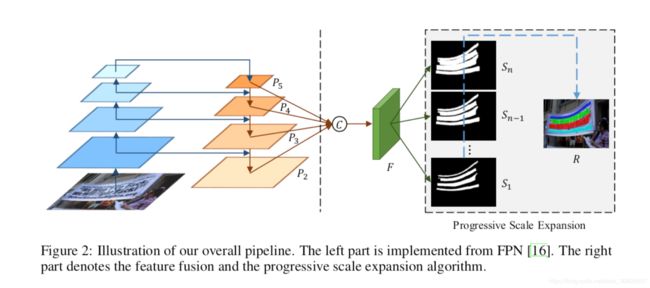
主干网络采用resnet,网络框架类似于FPN的结构,将低层特征映射与高级特征映射连接起来,利用resnet提取出四层256通道的feature maps:P2,P3,P4,P5,将得到的四层特征图进行融合得到1024通道的特征图,用F表示。融合公式:

“||”表示的是concatenation操作,Up×2,Up×4,Up×8分别表示的是将feature map进行上采样,上采样的倍数分别是2,4,8倍。特征图F送入3×3大小的卷积中输出通道数为256的特征图,将此特征图再送入1×1大小的卷积层中输出n个最终的结果,这n个结果用S1,S2,…,Sn表示Si是图像文字的分割结果,不同点在于分割出的文字区域大小不同,例如S1给出的是最小的文字区域分割结果,而Sn给出的是最大的文字区域分割结果(理想情况下就是GroundTruth)
三、Progressive Scale Expansion Algorithm-PSE算法

实际文章中n=6,为了更方便解释,假设n=3,即网络最终输出了3张分割结果S={S1,S2,S3},首先从最小的分割结果S1开始,如上图(a)所示,能够找出四个分割区域C={c1,c2,c3,c4}。这四个分割区域用四种不同的颜色表示,这样能得到所有文本的中心区域,然后将这些区域与S2,S3进行合并得到最终结果,结果分别如上图(c)和图(d)所示。上述依次合并的规则如上图(g)所示(Breadth-First-Search algorithm)。在合并的过程中可能会遇到如上图(g)中的冲突情况,在遇到冲突的情况下,采用"先到先得"的方式。更为详细的合并规则用下面的伪代码表示,其中T,P表示的中间结果,Q表示的是队列,Neighbor(⋅)表示像素的邻域,GroupByLabel(⋅)表示属于某一类的中间结果的label。Si[q]=True表示预测的Si中的像素q是文字。

四、标签生成
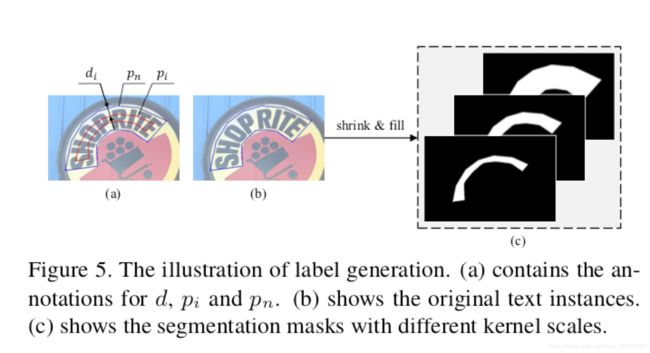
因为网络输出有n个分割结果,所以对于一张输入图片来说groundtruth也要有n个。这里groundtruth就是简单的将标定的文本框进行不同尺度的缩小,如上图所示。图中(b)就是标定框也是最大的groundtruth Sn,图(c)的最右侧图所示。为了获得图(c)中的其他图,文章采用Vatti clipping算法将原多边形pn缩小di 个像素得到pi 。最终得到的n个groundtruth用G1,G2,…,Gn
表示。需要缩小的像素通过下面式子得到:
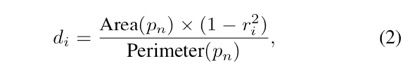
上式中,di表示要缩小的像素值,Area(⋅)表示多边形的面积,Perimeter(⋅)表示多边形的周长,ri表示缩小的比例。缩小比例ri的计算方式如下所示:
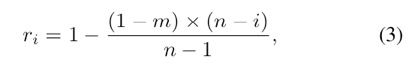
上式中,m
m表示最小的缩放比例,是一个超参数,取值范围为(0,1],本文取m=0.5。n为最终输出多少个尺度的分割结果,文章设为6。
【补充】Vatti clipping algorithm用于计算机图形学。它允许任意数量任意形状的主体多边形裁剪成任意数量任意形状的剪辑多边形。该算法不限制可用作主体或剪辑的多边形类型,即使是复杂的(自交)多边形和有孔的多边形也可以被处理。该算法一般只适用于二维空间。
五、损失函数
网络的整体损失函数可以表示为:

L c表示没有收缩的分割图像Gn对应的损失complete text instances,Ls表示其余的收缩的label对应的损失{G1,G2,...Gn−1}
因为文字区域一般占图像中的很小一部分,如果直接做像素级的分类,网络趋向于将预测为非文字类别,所以文中引用一种类别均衡方式dice coefficient来解决这一问题。

从公式中可以看出,当Si和Gi完全相同时D(Si,Gi)=1,完全不同时D(Si,Gi)=0 引入了难样本挖掘(OHEM)提升分割性能,假设由OHEM求到的训练mask为M所以:

因为其他缩小框的分割结果会被原始大小的框包围,文章说为了避免冗余,在计算缩小框Ls的损失函数时去除了Sn结果中为非文本的区域:

【补充】在线难例挖掘(online hard example miniing,OHEM)OHEM算法的核心思想是根据输入样本的损失进行筛选,筛选出难例,表示对分类和检测影响较大的样本,然后将筛选得到的这些样本应用在随机梯度下降中训练。在实际操作中是将原来的一个ROI Network扩充为两个ROI Network,这两个ROI Network共享参数。其中前面一个ROI Network只有前向操作,主要用于计算损失;后面一个ROI Network包括前向和后向操作,以hard example作为输入,计算损失并回传梯度。具体的关于OHEM的内容请参见OHEM算法及Caffe代码详解:https://blog.csdn.net/u014380165/article/details/73148073
六、为什么采用多核渐进尺度展开

从图中可以看出,如果只采用两级分割图(一个较小的收缩的预测图和一个完整的分割图),那么两个相邻但大小不同的文本行的检测结果将有一定的误差。而增加渐进的级数可以使检测结果更加精确。