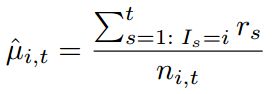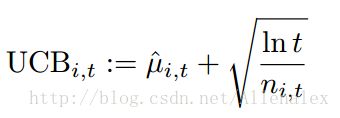面试总结——强化学习
强化学习和监督式学习的区别:
监督式学习就好比你在学习的时候,有一个导师在旁边指点,他知道怎么是对的怎么是错的,但在很多实际问题中,例如 chess,go,这种有成千上万种组合方式的情况,不可能有一个导师知道所有可能的结果。
而这时,强化学习会在没有任何标签的情况下,通过先尝试做出一些行为得到一个结果,通过这个结果是对还是错的反馈,调整之前的行为,就这样不断的调整,算法能够学习到在什么样的情况下选择什么样的行为可以得到最好的结果。
就好比你有一只还没有训练好的小狗,每当它把屋子弄乱后,就减少美味食物的数量(惩罚),每次表现不错时,就加倍美味食物的数量(奖励),那么小狗最终会学到一个知识,就是把客厅弄乱是不好的行为。
两种学习方式都会学习出输入到输出的一个映射,监督式学习出的是之间的关系,可以告诉算法什么样的输入对应着什么样的输出,强化学习出的是给机器的反馈 reward function,即用来判断这个行为是好是坏。
另外强化学习的结果反馈有延时,有时候可能需要走了很多步以后才知道以前的某一步的选择是好还是坏,而监督学习做了比较坏的选择会立刻反馈给算法。
而且强化学习面对的输入总是在变化,每当算法做出一个行为,它影响下一次决策的输入,而监督学习的输入是独立同分布的。
通过强化学习,一个 agent 可以在探索和利用(exploration and exploitation)之间做权衡,并且选择一个最大的回报。
exploration 会尝试很多不同的事情,看它们是否比以前尝试过的更好,exploitation 会尝试过去经验中最有效的行为。一般的监督学习算法不考虑这种平衡,就只是是 exploitative。
强化学习和非监督式学习的区别:
非监督式不是学习输入到输出的映射,而是模式。例如在向用户推荐新闻文章的任务中,非监督式会找到用户先前已经阅读过类似的文章并向他们推荐其一,而强化学习将通过向用户先推荐少量的新闻,并不断获得来自用户的反馈,最后构建用户可能会喜欢的文章的“知识图”。
强化学习算法的2大分类
这2个分类的重要差异是:智能体是否能完整了解或学习到所在环境的模型
有模型学习(Model-Based)对环境有提前的认知,可以提前考虑规划,但是缺点是如果模型跟真实世界不一致,那么在实际使用场景下会表现的不好。先理解真实世界是怎样的, 并建立一个模型来模拟现实世界的反馈,通过想象来预判断接下来将要发生的所有情况,然后选择这些想象情况中最好的那种,并依据这种情况来采取下一步的策略。它比 Model-free 多出了一个虚拟环境,还有想象力。
免模型学习(Model-Free)放弃了模型学习,在效率上不如前者,但是这种方式更加容易实现,也容易在真实场景下调整到很好的状态。所以免模型学习方法更受欢迎,得到更加广泛的开发和测试。不尝试去理解环境, 环境给什么就是什么,一步一步等待真实世界的反馈, 再根据反馈采取下一步行动。
强化学习on-policy跟off-policy的区别
on-policy:生成样本的policy(value function)跟网络更新参数时使用的policy(value function)相同。典型为SARAS算法,基于当前的policy直接执行一次动作选择,然后用这个样本更新当前的policy,因此生成样本的policy和学习时的policy相同,算法为on-policy算法。该方法会遭遇探索-利用的矛盾,光利用目前已知的最优选择,可能学不到最优解,收敛到局部最优,而加入探索又降低了学习效率。epsilon-greedy 算法是这种矛盾下的折衷。优点是直接了当,速度快,劣势是不一定找到最优策略。
off-policy:生成样本的policy(value function)跟网络更新参数时使用的policy(value function)不同。典型为Q-learning算法,计算下一状态的预期收益时使用了max操作,直接选择最优动作,而当前policy并不一定能选择到最优动作,因此这里生成样本的policy和学习时的policy不同,为off-policy算法。先产生某概率分布下的大量行为数据(behavior policy),意在探索。从这些偏离(off)最优策略的数据中寻求target policy。当然这么做是需要满足数学条件的:假設π是目标策略, µ是行为策略,那么从µ学到π的条件是:π(a|s) > 0 必然有 µ(a|s) > 0成立。两种学习策略的关系是:on-policy是off-policy 的特殊情形,其target policy 和behavior policy是一个。
劣势是曲折,收敛慢,但优势是更为强大和通用。其强大是因为它确保了数据全面性,所有行为都能覆盖。


多臂老虎机和强化学习算法的差别
策略:是强化学习机的核心,代表着决策进行的方式。它可能是一个表格,一个函数或者一个复杂的深度神经网络。
奖励信号:一个数值,代表着强化学习机采取行动后的即时奖励。最大化所得奖励是强化学习机的最终目标,为了完成这个目标,我们不断地调整策略。
价值函数:一个函数,用于描述给定状态下的可能获得的远期奖励。这样看来,一个较小的但恒定的常数有可能会优于浮动范围很大的结果。当然,也可能是相反的情况。
相比于目前流行的深度学习以及类似的需要大量训练数据来生成模型的监督学习方法,强化学习一个重要的不同点是利用训练的数据去评估下一步的行动(action),而不是仅仅指示(instruct)出正确的行动。
多臂老虎机本质上是一类简化的强化学习问题,这类问题具有非关联的状态(每次只从一种情况输或赢中学习),而且只研究可评估的反馈。假设有一台N个摇臂老虎机,每拉一个摇臂都会有一定的概率获得回报,这样我们有了N种可能的行动(每个摇臂对应一种action),并且每次行动的结果只和当前的状态关联而不受历史行动的结果影响(每次拉摇臂的回报只和老虎机设置的概率相关,之前输赢的结果不会影响本次行动)。定义这种问题是具有单一状态的马尔科夫决策过程。
单步强化学习任务对应了一个理论模型,即" K-摇臂赌博机",K-摇臂赌博机有K 个摇臂,赌徒在投入一个硬币后可选择按下其中一个摇臂,每个摇臂以一定的概率吐出硬币?但这个概率赌徒并不知道.赌徒的目标是通过一定的策略最大化自己的奖赏,即获得最多的硬币.
对于离散状态空间、离散动作空间上的多步强化学习任务,一种直接的办法是将每个状态上动作的选择看作-个K-摇臂赌博机问题,用强化学习任务的累积奖赏来代替K-摇臂赌博机算法中的奖赏数,即可将赌博机算法用于每个状态:对每个状态分别记录各动作的尝试次数、当前平均累积奖赏等信息?基于赌博机算法选择要尝试的动作.然而这样的做法有很多局限,因为它没有考虑强化学习任务马尔可夫决策过程的结构,若能有效考虑马尔可夫决策过程的特性,则可有更聪明的办法.
多臂老虎机算法的分类
有一个赌博机,一共有 k 个摇臂,玩家每次投一个游戏币后可以按一个摇臂,每个摇臂按下后都有可能吐出硬币作为奖励,但是每个摇臂吐出硬币的概率分布是未知的,玩家的目标是获得最大化的累积奖赏。
有选择的去调整策略: MAB 中的每个摇臂都是一个选项,因此它是一个有条件的选择问题,目标是获得最大化的累积奖赏,限制是已有的选择分支。
Bandit算法
Bandit算法是指一类算法。 要比较不同Bandit算法的优劣, 可以用累积遗憾这个概念来衡量。
它顾名思义, 是指T次选择, 将每次选择的实际收益 WB_i与此次选择如果选择最好的策略带来的最大收益之差, 将T次差的加总就得到了累积遗憾。假设用最简单的伯努利实验来模拟这个过程:我们有K个选择, 其中每次选择时最优收益是1, 其余非优收益为0. 我们进行了T次选择, 则最差的情况下我们的累积遗憾就是T,而最好情况是每次选择都是1, 遗憾为0.
几种Bandit算法:
1、Epsilon-Greedy算法
初始化选择一个(0, 1)之间 较小的正数, epsilon。每次以 (0, epsilon )均分分布产生一个比epsilon小的数, 选择所有臂中随机选一个, 否则选择截止当前平均收益最大的那个臂。每次尝试时,以ε 的概率进行探索,即以均匀概率随机选取一个摇臂;以1-ε 的概率进行利用,即选择当前平均奖赏最高的摇臂(若有多个,则随机选取一个).
Epsilon-Greedy 是看上去非常简单直接的算法。 通过控制epsilon的值控制对 Exploit和Explore的偏好程度。
越接近0, 越保守, 反之越激进。
2、Softmax
基于当前已知的摇臂平均奖赏来对探索和利用进行折中。若各摇臂的平均奖赏相当,则选取各摇臂的概率也相当;若某些摇臂的平均奖赏明显高于其他摇臂,则它们被选取的概率也明显更高。
总结ϵ-greedy算法和softmax算法的共有属性:
(1)两种算法在每一轮选择时,默认都是选择到目前为止最好的臂;
(2)除此之外,算法会尝试去探索一些目前看起来不是最好的臂:
- ϵ-greedy算法探索的时候完全是随机的。
- softmax算法探索是基于到当前时刻臂的收益概率。收益概率越高,选择的概率越高。(3)两种算法都能够通过随着时间动态修改基本参数来实现更好的性能。
这种随机性,或者仅仅考虑收益回报的算法有一个很明显的缺点就是健壮性比较差,很容易受噪音数据影响。
3、UCB算法 (Upper Confidence Bound)UCB算法,是一种完全不同的算法。首先,它是完全不使用随机性的;其次,它除了要考虑收益回报外,还要考虑一点,这个收益回报的置信度有多高。
问题来了,怎么来定义这个置信度呢?这是UCB算法的核心(UCB实Upper Confidence Bounds的首字母缩写)。实际UCB算法包括很多种。本文介绍的只是其中一种。现在,让我们来正式定义这个置信度以及整个UCB算法。
首先,考虑置信后定义的收益回报为:
4、Thompson sampling
原理: 假设每个臂是否产生收益,服从概率分布, 产生收益的概率为p。
不断试验,得到一个置信度较高的概率p的概率分布, 就能近似解决这个问题了。
如何估计概率p的概率分布?
答案是假设概率p的分布符合 beta分布 ~~ beta(wins, loses) 参数wins, loses
每个臂都对应着一组beta分布的参数。 每次试验后, 选中一个摇臂, 有收益则该臂的wins+1, 否则 loses+1。
选择摇臂的方式是: 用每个臂现有beta分布产生一个随机数b, 选择所有臂产生的随机数中最大的摇臂去展开策略。