# Tensorflow 代码调试过程出现问题及解决方法
Tensorflow 代码调试过程出现问题及解决方法
@(monkey)
一. 错误
初学者很容易犯很多错误
记录一下
1.slice indices must be integers or None or have an index method
#定义这样图
with tf.name_scope("validation"):
with tf.variable_scope("weigh_biases",reuse = True):
Weights1 = tf.get_variable('Weights') #reuse
biases1 = tf.get_variable('biases') #reuse
validata = tf.placeholder(tf.float32,(30,2)) #input data 30
y = tf.matmul(validata,Weights1) + tf.matmul(tf.ones((30,1)),biases1)
#sess.run
vanum = ((step/100)%2 - 1)*30 #0 or 30 ##problem
y = sess.run(y,feed_dict={validata:validation_data[vanum:vanum+30]})#运行到这步出错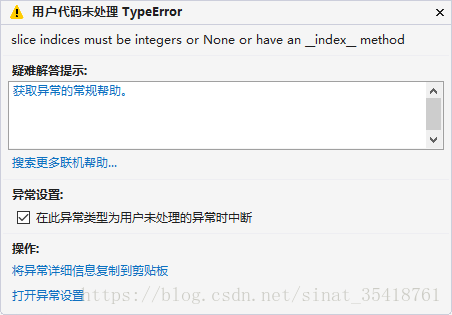
原因在于 vanum的计算涉及到除法,自动产生浮点型数据
而数据的下标必须是整型
vanum =np.int( ((step/100)%2 - 1)*30 ) #0 or 30 ##problem
2.Fetch argument array … has invalid type
y = sess.run(y,feed_dict={validata:validation_data[vanum:vanum+30]})这条代码出现错误
原因是y与要fetch的y重名,将y改成y1就行勒
3.Parent directory of my-model doesn’t exist, can’t save.
saver = tf.train.Saver()
saver.save(sess,'my-model',global_step = 100)
第二个参数错误,应该是路径
‘my-model’ 改为* ./checkpoints/mymodel.ckpt
4.tf.get_default_graph().get_tensor_by_name()
KeyError: “The name ‘validation/weigh_biases/validata:0’ refers to a Tensor which does not exist. The operation, ‘validation/weigh_biases/Placehoder’, does not exist in the graph.”
在错误1中的代码中定义的placeholder定义如下:
#在训练存储模型.py【只是形象表示】定义这样图
...#其中某个占位符
validata = tf.placeholder(tf.float32,(30,2)) #input data 30
...
#在再到训练存储模型.py中【只是形象表示不同.py文件】
y1 = sess.run(tf.get_default_graph().get_tensor_by_name('validation/weigh_biases/add:0'),
feed_dict={tf.get_default_graph().get_tensor_by_name('validation/weigh_biases/Placeholder:0'):test_data[num:num+30]})我以为validate这个占位符的名字是validation/weigh_biases/validata:0
但是有错误:显示没有该tensor
然后再到训练存储模型.py中单步调试发现,上句代码未给validate命名[validata = tf.placeholder(tf.float32,(30,2),name=’XXX’)]
在命名空间中 自动给validate这个占位符命名为:validation/weigh_biases/Placeholder:0
这也说明了tf.placeholder()函数中name的作用。
二、敲代码中不懂的
1.variable与get_variable的区别
variable与get_variable的区别
tf.Variable(initial_value=None, trainable=True, collections=None, validate_shape=True, caching_device=None, name=None, variable_def=None, dtype=None, expected_shape=None, import_scope=None)
tf.get_variable(name, shape=None, dtype=None, initializer=None, regularizer=None, trainable=True, collections=None, caching_device=None, partitioner=None, validate_shape=True, custom_getter=None)
使用Variable函数时,如果参数name有冲突,相同的,系统会自己处理.
使用Get_variable时,如果参数name有冲突,那会报错。
由于Variable() 每次都在创建新对象,所有reuse=True 和它并没有什么关系。对于get_variable(),来说,如果已经创建的变量对象,就把那个对象返回,如果没有创建变量对象的话,就创建一个新的。
所以需要参数共享时,使用Get_Variable(),其余情况下两者都是一样的,如何参数共享请见下面第二条。
w_1 = tf.Variable(3,name="w_1")
w_2 = tf.Variable(1,name="w_1")#same Variable name
print w_1.name
print w_2.name
#输出
#w_1:0
#w_1_1:0
w_3 = tf.get_variable(name="w_1",initializer=1)
w_4 = tf.get_variable(name="w_1",initializer=2)
#错误信息
#ValueError: Variable w_1 already exists, disallowed. Did
#you mean to set reuse=True in VarScope?可以从错误信息中看出来,提醒我们Get_Variable创建变量对象有冲突的时候,提醒是否在不同变量空间(VarScope)中进行参数的共享。
2.name_scope&variable_scope的区别
name&variable scope
以下的例子:
with tf.name_scope("hello") as name_scope:
arr1 = tf.get_variable("arr1", shape=[2,10],dtype=tf.float32)
1.模型的存储与加载
1)存储
train.py中存储了训练出的模型:
saver = tf.train.Saver()
saver.save(sess,'./checkpoints/mymodel.ckpt',global_step = 100)
含义解释
a)meta图
这是一个拟定的缓存,包含了这个TF图完整信息;如所有变量等等。文件以.meta结束。
b)检查点文件:
这个文件是一个二进制文件,包含所有权重、偏移、梯度和所有其它存储的变量的值。这个文件以.ckpy结束。
然而,TF已经在0.11版本后不再以这个形式了。
转而使用以下格式 :
mymodel.data-00000-of-00001
mymodel.index
.data文件包含训练变量。
除此之外 ,TF还包含一个名为“checkpoint”的文件 ,保存最后检查点的文件。
所以,综上,TF模型包含如下文件 :
my_test_model.data-00000-of-00001
my_test_model.index
my_test_model.meta
checkpoint**
2)加载存储模型:
saver = tf.train.import_meta_graph("./checkpoints/mymodel.ckpt-100.meta")
new_saver.restore(sess, tf.train.latest_checkpoint('./'))