promethus第一部分
prometheus
参考:https://yunlzheng.gitbook.io/prometheus-book/parti-prometheus-ji-chu/promql/prometheus-query-language
架构
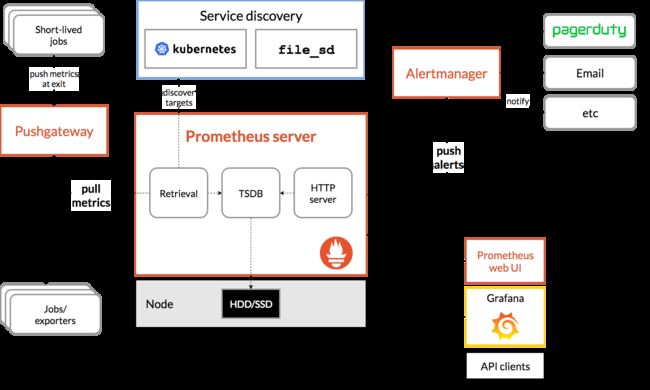
prometheus Server
负责对监控数据的获取,存储以及查询,prometheus Server可以通过静态配置管理监控的目标,也可配合使用service discovery 的当时实现动态的监控目标。prometheus本身就是一个时序的数据库,将采集到的监控数据按照时间序列的方式存储在本地磁盘当中,使用promQl可以进行数据的查询。
Exporters
将监控采集到的断电通过http的方式http的方式暴露给 prometheus Server,Prometheus Server通过访问该Exporter提供的Endpoint端点,即可获取到需要采集的监控数据。
一般来说可以将Exporter分为2类:
- 直接采集:这一类Exporter直接内置了对Prometheus监控的支持,比如cAdvisor,Kubernetes,Etcd,Gokit等,都直接内置了用于向Prometheus暴露监控数据的端点。
- 间接采集:间接采集,原有监控目标并不直接支持Prometheus,因此我们需要通过Prometheus提供的Client Library编写该监控目标的监控采集程序。例如: Mysql Exporter,JMX Exporter,Consul Exporter等。
Alter manager
在Prometheus Server中支持基于PromQL创建告警规则,如果满足PromQL定义的规则,则会产生一条告警,而告警的后续处理流程则由AlertManager进行管理。在AlertManager中我们可以与邮件,Slack等等内置的通知方式进行集成,也可以通过Webhook自定义告警处理方式。AlertManager即Prometheus体系中的告警处理中心。
pushGateway
由于prometheus数据采集基于Pull模型进行设计,因此在网络环境的配必须要让,prometheus Server能够直接与Exproter进行通信,当这种网络需求无法直接满足时,就可以利用PushGateway来进行中转。可以通过PushGateway将内部网络的监控数据主动Push到Gateway当中。而Prometheus Server则可以采用同样Pull的方式从PushGateway中获取到监控数据。
prometheus数据
样本
prometheus会将采集的样本数据已时间序列的方式保存在内存数据库中,并定时保存在磁盘当中。time=series 是按照时间戳和值的顺序进行存放,每条time-series通过指标名称(metrics-name)和一组标签集(lables) ,时间戳和values组成。
<--------------- metric ---------------------><-timestamp -><-value->
http_request_total{status="200", method="GET"}@1434417560938 => 94355
metrics
指标(metrics) 的格式,为time-series 前面的部分。
{ prometheus当中支持的metrics
为了能够帮助用户理解和区分这些不同监控指标之间的差异,Prometheus定义了4种不同的指标类型(metric type):Counter(计数器)、Gauge(仪表盘)、Histogram(直方图)、Summary(摘要)。
Counter : 只增不减的计数器
Counter类型的指标其工作方式和计数器一样,只增不减(除非系统发生重置)。常见的监控指标,如http_requests_total,node_cpu都是Counter类型的监控指标。 一般在定义Counter类型指标的名称时推荐使用_total作为后缀。
Gauge:可增可减的仪表盘
与Counter不同,Gauge类型的指标侧重于反应系统的当前状态。因此这类指标的样本数据可增可减。常见指标如:node_memory_MemFree(主机当前空闲的内容大小)、node_memory_MemAvailable(可用内存大小)都是Gauge类型的监控指标。
Histogram与summary
除了Counter和Gauge类型的监控指标以外,Prometheus还定义了Histogram和Summary的指标类型。Histogram和Summary主用用于统计和分析样本的分布情况。
在大多数情况下人们都倾向于使用某些量化指标的平均值,例如CPU的平均使用率、页面的平均响应时间。这种方式的问题很明显,以系统API调用的平均响应时间为例:如果大多数API请求都维持在100ms的响应时间范围内,而个别请求的响应时间需要5s,那么就会导致某些WEB页面的响应时间落到中位数的情况,而这种现象被称为长尾问题。
PromQL
PromQL是Prometheus内置的数据查询语言,其提供对时间序列数据丰富的查询,聚合以及逻辑运算能力的支持。并且被广泛应用在Prometheus的日常应用当中,包括对数据查询、可视化、告警处理当中。可以这么说,PromQL是Prometheus所有应用场景的基础。
示例:
process_cpu_seconds_total{instance="localhost:9090"}[5d]
查询 instance="localhost:9090" 5天内的所有监控的进程使用cpu情况。
标签的可以使用= ,!=, =~(取反) 进行匹配
process_cpu_seconds_total{instance!="localhost:9090"}[5d]
process_cpu_seconds_total{instance=~"localhost:9090|localhost:00"}[5d]
时间区间可以偏移量
process_cpu_seconds_total{instance!="localhost:9090"} offset
数学运算
PromQL支持算数运算。
node_memory_CmaFree_bytes/ (1024*1024)
PromQL支持的所有数学运算符如下所示:
+(加法)-(减法)*(乘法)/(除法)%(求余)^(幂运算
BOOL运算
在PromQL通过标签匹配模式,用户可以根据时间序列的特征维度对其进行查询。而布尔运算则支持用户根据时间序列中样本的值,对时间序列进行过滤。
(node_memory_bytes_total - node_memory_free_bytes_total) / node_memory_bytes_total > 0.95
#磁盘的使用率
目前,Prometheus支持以下布尔运算符如下:
==(相等)!=(不相等)>(大于)<(小于)>=(大于等于)<=(小于等于)
逻辑操作
and(并且)or(或者)unless(排除)
聚合函数
Prometheus还提供了下列内置的聚合操作符,这些操作符作用域瞬时向量。可以将瞬时表达式返回的样本数据进行聚合,形成一个新的时间序列。
sum(求和)min(最小值)max(最大值)avg(平均值)stddev(标准差)stdvar(标准方差)count(计数)count_values(对value进行计数)bottomk(后n条时序)topk(前n条时序)quantile(分位数
altermanager
告警能力在Prometheus的架构中被划分成两个独立的部分。如下所示,通过在Prometheus中定义AlertRule(告警规则),Prometheus会周期性的对告警规则进行计算,如果满足告警触发条件就会向Alertmanager发送告警信息。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YiQtdmfi-1591796075874)(https://gblobscdn.gitbook.com/assets%2F-LBdoxo9EmQ0bJP2BuUi%2F-LVMF4RtPS-2rjW9R-hG%2F-LPS9QhUbi37E1ZK8mXF%2Fprometheus-alert-artich.png?alt=media)]
Prometheus告警处理
在Prometheus中一条告警规则主要由以下几部分组成:
- 告警名称:用户需要为告警规则命名,当然对于命名而言,需要能够直接表达出该告警的主要内容
- 告警规则:告警规则实际上主要由PromQL进行定义,其实际意义是当表达式(PromQL)查询结果持续多长时间(During)后出发告警
ometheus告警处理
在Prometheus中一条告警规则主要由以下几部分组成:
- 告警名称:用户需要为告警规则命名,当然对于命名而言,需要能够直接表达出该告警的主要内容
- 告警规则:告警规则实际上主要由PromQL进行定义,其实际意义是当表达式(PromQL)查询结果持续多长时间(During)后出发告警