Win10系统VS2015上配置YOLOv3运行训练环境(包含OpenCv3.40安装配置,cuda9.2安装配置)
前言
第一次写博客,迟迟不敢下笔,只怕在言语之间有所纰漏。在下区区学生一枚,在此斗胆写下在win10上搭建yolo_v3环境的过程与感受。博文部分安装配置过程将会引用其他博文,如有侵权,通知立删。
1.原材料
- IDE:VS2015 社区版 https://pan.baidu.com/s/19PdBDoX7hpfVMlsrYp8hwQ 密码:rh46
- 视觉库:OpenCV3.4 https://opencv.org/releases.html
- 运算平台:cuda9.2 https://developer.nvidia.com/cuda-toolkit-archive
- 加速器:cudnn7.14 https://developer.nvidia.com/rdp/cudnn-archive
- yolo:yolo_v3 https://github.com/AlexeyAB/darknet
- yolo_v3 weights: https://pjreddie.com/media/files/yolov3.weights
2.安装VS2015
链接中的版本也就是本文所用的版本,安装简单,无需破解。我原本选择的VS2017社区版作为IDE,但是在安装cuda9.2时遇到了问题。因为VS2017现在是在线安装的模式,从官网下载的IDE都是15.9版本的,而cuda最高只支持到15.6。再者,网上很难找到15.6及其以下的VS2017版本,而且很大,动辄20-30G。
对于其安装过程https://blog.csdn.net/guxiaonuan/article/details/73775519?locationNum=2&fps=1这篇文章里已经做了详细的介绍,但是在自定义安装是至少应选择Visual C++和Visual Studio 2015 Update 3。其它就看心情,看喜好勾。我在VS2015的安装上没有遇到什么问题,所以也没有什么好说的。
3.配置OpenCv3.40
现在OpenCv已经更新到了3.42,但是据说3.41以后及其以后的有bug,所以就懦弱的选择了OpenCv3.40.其配置过程也就是配置环境变量和建立与VS2015的连接。https://blog.csdn.net/greenhandcgl/article/details/80505701这篇文章详细的介绍了debug x64的配置方法,x86于此相似,不过最后的依赖项改成opencv_world340.lib。另外包含目录中只需添加添加opencv安装目录下build\include便可使用。如果可以加载出图片就可以说明OpenCv配置成功。如果没有错误而加载不出图片,有可能是图片路径的原因。如果出错,先查看debug是不是选择的配置过的,如果配置的x64,而选择的是x86就会出错,如果debug没有选错,那考虑是否路径有错。
4.配置cuda9.2
为什么选择cuda9.2?因为他最新,这是我最开始的想法,而后这篇文章给了我答案https://www.cnblogs.com/joxon/p/cuda91-incompatibility-with-vs2017.html。作者在写的时候,VS最新版是15.7,此时VS已经出了15.9,而cuda依旧只支持到15.6。所以在官网上下的VS2017与会出现cuda不兼容的情况。
cuda的安装过程比较简单,但是配置过程可能会遇到些问题。https://blog.csdn.net/u013165921/article/details/77891913这篇文章给了详细的安装配置过程,还有测试代码。其实在https://github.com/AlexeyAB/darknet中已经对平台的选择做了一定的推荐。

有一个不成熟的小建议就是,在配置属性的时候直接在属性管理器中配置,就行配OpenCv那样。这样可以在下一次新建工程时直接继承原先的配置,而不用重新配。如下图所示。
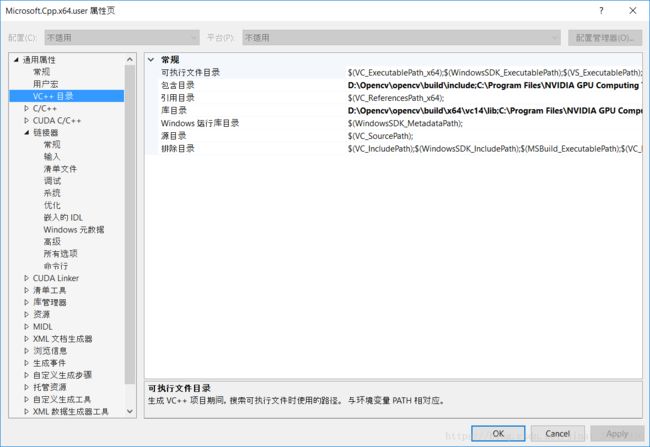
加速器的只是cuda的一个部分,只用下载与cuda匹配的版本,然后解压,把相应文件拷到cuda安装路径下的对应位置就可以了。即将文件夹
cudnn-9.2-windows10-x64-v7.1\cuda\bin
cudnn-9.2-windows10-x64-v7.1\cuda\include
cudnn-9.2-windows10-x64-v7.1\cuda\lib
里的文件分别拷到
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.2\bin
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.2\include
C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.2\lib\x64
中,以上三个路径是cuda的默认路径。
至此OpenCv与cuda都已经安装配置完毕。可以用如下的一个小程序来综合测试一下:
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include
#include
#include
#include
using namespace cv;
cudaError_t addWithCuda(int *c, const int *a, const int *b, unsigned int size);
__global__ void addKernel(int *c, const int *a, const int *b)
{
int i = threadIdx.x;
c[i] = a[i] + b[i];
}
int pecture(void) {
Mat src = imread("12.jpg");
if (src.empty()) {
printf("文件不存在");
return -1;
}
namedWindow("test", CV_WINDOW_AUTOSIZE);
imshow("test", src);
waitKey(0);
return 0;
}
int main()
{
pecture();
const int arraySize = 5;
const int a[arraySize] = { 1, 2, 3, 4, 5 };
const int b[arraySize] = { 10, 20, 30, 40, 50 };
int c[arraySize] = { 0 };
// Add vectors in parallel.
cudaError_t cudaStatus = addWithCuda(c, a, b, arraySize);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "addWithCuda failed!");
return 1;
}
printf("{1,2,3,4,5} + {10,20,30,40,50} = {%d,%d,%d,%d,%d}\n",
c[0], c[1], c[2], c[3], c[4]);
// cudaDeviceReset must be called before exiting in order for profiling and
// tracing tools such as Nsight and Visual Profiler to show complete traces.
cudaStatus = cudaDeviceReset();
system("pause");
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaDeviceReset failed!");
return 1;
}
return 0;
}
// Helper function for using CUDA to add vectors in parallel.
cudaError_t addWithCuda(int *c, const int *a, const int *b, unsigned int size)
{
int *dev_a = 0;
int *dev_b = 0;
int *dev_c = 0;
cudaError_t cudaStatus;
// Choose which GPU to run on, change this on a multi-GPU system.
cudaStatus = cudaSetDevice(0);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaSetDevice failed! Do you have a CUDA-capable GPU installed?");
goto Error;
}
// Allocate GPU buffers for three vectors (two input, one output) .
cudaStatus = cudaMalloc((void**)&dev_c, size * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_a, size * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
cudaStatus = cudaMalloc((void**)&dev_b, size * sizeof(int));
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMalloc failed!");
goto Error;
}
// Copy input vectors from host memory to GPU buffers.
cudaStatus = cudaMemcpy(dev_a, a, size * sizeof(int), cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
cudaStatus = cudaMemcpy(dev_b, b, size * sizeof(int), cudaMemcpyHostToDevice);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
// Launch a kernel on the GPU with one thread for each element.
addKernel << <1, size >> >(dev_c, dev_a, dev_b);
// Check for any errors launching the kernel
cudaStatus = cudaGetLastError();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "addKernel launch failed: %s\n", cudaGetErrorString(cudaStatus));
goto Error;
}
// cudaDeviceSynchronize waits for the kernel to finish, and returns
// any errors encountered during the launch.
cudaStatus = cudaDeviceSynchronize();
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaDeviceSynchronize returned error code %d after launching addKernel!\n", cudaStatus);
goto Error;
}
// Copy output vector from GPU buffer to host memory.
cudaStatus = cudaMemcpy(c, dev_c, size * sizeof(int), cudaMemcpyDeviceToHost);
if (cudaStatus != cudaSuccess) {
fprintf(stderr, "cudaMemcpy failed!");
goto Error;
}
Error:
cudaFree(dev_c);
cudaFree(dev_a);
cudaFree(dev_b);
return cudaStatus;
}
如果配置成功先会出现一幅图片,我想那应该是你喜欢的一幅图。
然后你轻轻关掉图片,你会发现如下结果,这就证明我们配置成功了。

5.配置YOLO
有了前面的铺垫,现在直接用VS打开darknet工程。最开始我无法打开工程,然后通过查阅资料然后得到了这个解决方法,打开工程文件darknet-master\build\darknet\darknet.vcxproj(gpu版),找到两处cuda版本的代码,修改为你的版本,然后保存。现在在尝试用VS打开这个工程,然后就正常打开工程了。这个错误在https://github.com/AlexeyAB/darknet里也有所描述

这个代码里是默认路径,我们配了环境的不需要管这个。

然后点击ctrl+F5运行代码,很幸运的是在debug x64通过了,然后在cmd上找到darknet-master\build\darknet\x64\darknet.exe的路径D:\>cd D:\darknet-master\build\darknet\x64我的是这个。然后输入darknet.exe detector test data/coco.data yolov3.cfg yolov3.weights -i 0 -thresh 0.25 dog.jpg。更多的命令在https://github.com/AlexeyAB/darknet里也可以找到。
darknet.exe detector test data/coco.data yolov3.cfg yolov3.weights -i 0 -thresh 0.25 dog.jpg然后得到了如下结果,可以看到网络运行成功,预测图像被保存起来了,而没有显示出来。只是因为没有加载opencv的原因,源码当中有#ifdef OPENCV这样的代码,而OPENCV却不在源码中定义。
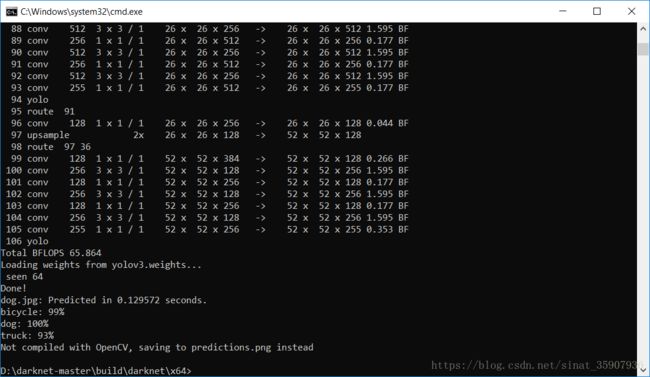
查阅资料得到,这个值在makefile里,默认值是0,GPU,CUDNN的默认值也是0,改成1之后,保存重新打开工程,继续在debug x64下运行,依旧没有图片。说明这个方法是错误的,https://github.com/AlexeyAB/darknet里有明确说明,这是在Linux上的编译方式,这个才是windows上的。原来饶了一大圈的问题只是编译平台的原因。

最后修改运行平台成Release x64之后,奇迹发生了。
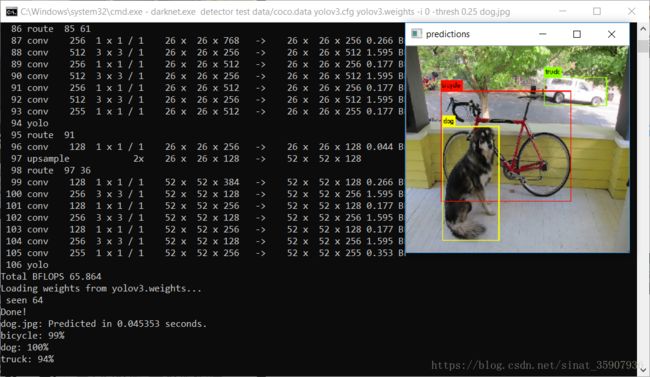
文章到此结束,第一次写,如果对你有所帮助就最好啦,如果没有还请不要苛责。如果有错,不吝指教。
更新1
如果是没有GPU,直接下下来就打开darknet_no_gpu.vcxproj编译完成之后就可以跑,如果想要显示预测结果,配一个opencv就可以。
更新2
darknet.vcxproj用记事本打开后可见,
错误 MSB3721 The command ""C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.2\bin\nvcc.exe" -gencode=arch=compute_30,code=\"sm_30,compute_30\" -gencode=arch=compute_75,code=\"sm_75,compute_75\" --use-local-env -ccbin "C:\Program Files (x86)\Microsoft Visual Studio 14.0\VC\bin\x86_amd64" -x cu -I\include -IC:\opencv_3.0\opencv\build\include -I..\..\include -I..\..\3rdparty\stb\include -I..\..\3rdparty\pthreads\include -I"C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.2\include" -I"C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.2\include" -I\include -I\include -I"C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v9.2\include" --keep-dir x64\Release -maxrregcount=0 --machine 64 --compile -cudart static -DOPENCV -DCUDNN_HALF -DCUDNN -D_TIMESPEC_DEFINED -D_SCL_SECURE_NO_WARNINGS -D_CRT_SECURE_NO_WARNINGS -D_CRT_RAND_S -DGPU -DWIN32 -DNDEBUG -D_CONSOLE -D_LIB -D_MBCS -Xcompiler "/EHsc /W3 /nologo /O2 /Fdx64\Release\vc140.pdb /FS /Zi /MD " -o x64\Release\activation_kernels.cu.obj "G:\daek\darknet-master\src\activation_kernels.cu"" exited with code 1. darknet C:\Program Files (x86)\MSBuild\Microsoft.Cpp\v4.0\V140\BuildCustomizations\CUDA 9.2.targets 712
删除如下图所示的两项就可以解决此问题。
