python中MySQLdb使用中踩过的坑
1. 导入MySQLdb模块
import MySQLdb
2. 连接数据库
conn= MySQLdb.connect(
host='localhost',
port = 3306,
user='root',
passwd='123456',
db ='SWH',
charset='utf8',
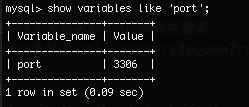
)port:数据库使用的端口号,可以在数据库中执行show variables like 'port';命令获取到;如图
user:登录数据库的用户名
passwd:很明显是登录数据库的密码
db:使用数据库中的那个库,类似于文件夹,数据库中的表类似于文件夹中的文件
charset:用什么编码形式连接数据库,如果不声明utf8,默认整个数据库是Latin1的编码方式,写入的时候会报错UnicodeEncodeError: 'latin-1' codec can't encode characters in position 108-128: ordinal not in range(256)
3.执行数据库命令
由于这里不是主要讲MySQLdb的,只是讲典型的坑的我这里只执行数据库写入命令,这里是正确的,在错误示范里面写错误的
cur.execute("insert into lianjia \
(des,name,room_type,size,region,loucheng,chaoxiang,price,price_union,builtdate) \
values('%s','%s','%s','%s','%s','%s','%s','%s','%s','%s')" % (des\
,name,room_type,size,region,loucheng,chaoxiang,price,price_union,builtdate))3.1 第一个坑,数据库指令写入的值必须用‘’单引号包括,会报错误"Unknown column 'xxx' in 'field list'"
cur.execute("insert into lianjia \
(des,name,room_type,size,region,loucheng,chaoxiang,price,price_union,builtdate) \
values(des,name,room_type,size,region,loucheng,chaoxiang,price,price_union,builtdate))3.2 第二个坑,把变量括起来了,这样写入变量名就被写入数据库了,也是错误的,python中必须使用字符串格式化
cur.execute("insert into lianjia \
(des,name,room_type,size,region,loucheng,chaoxiang,price,price_union,builtdate) \
values('des','name','room_type','size,region','loucheng','chaoxiang,price',\
'price_union','builtdate'))3.3 编码错误,由于没用过数据库,数据库安装后默认是latin1编码,写入utf8编码会报错(1366, "Incorrect string value: '\\xE5\\xB9\\xB4\\xE5\\xBB\\xBA' for column 'builtdate' at row 1")
3.1.1 查看数据库编码
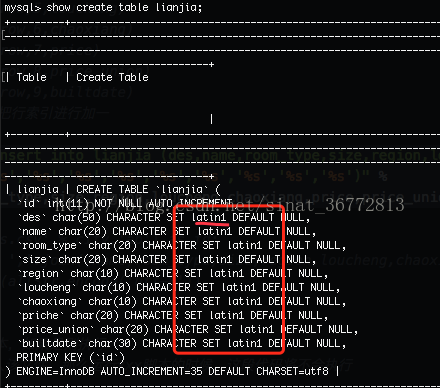
3.1.2 怎么办呢?改编码方式吧,网上查找了一个sql指令 alter table lianjia change des des char(50) character utf8;
一运行报错:ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'utf8' at line 1
坑逼了,多次验证不对,经过资料查证alter table lianjia change des des char(50) character set utf8;丢了一个set,所以建议各位以后学习的时候不要懒,多动手,网上的东西不一定都对,有时候作者编辑博客的时候就不小心丢东西了,切记!!!!!!
3.1.3 附上各种修改编码方式的sql命令
命令链接:http://blog.csdn.net/sinat_36772813/article/details/73649956
现在就可以正常保存数据了
3.1.4 附上抓取上海链家网数据并写入到数据库的源码
#_*_coding:utf-8_*_
# 导入开发模块
import requests
# 用于解析html数据的框架
from bs4 import BeautifulSoup
import MySQLdb
conn= MySQLdb.connect(
host='localhost',
port = 3306,
user='root',
passwd='123456',
db ='SWH',
charset='utf8',
)
cur = conn.cursor()
def getHtml(city):
url = 'http://sh.lianjia.com/ershoufang/%s/' % city
headers = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}
request = requests.get(url=url,headers=headers)
# 获取源码内容比request.text好,对编码方式优化好
respons = request.content
# 使用bs4模块,对响应的链接源代码进行html解析,后面是python内嵌的解释器,也可以安装使用lxml解析器
soup = BeautifulSoup(respons,'html.parser')
# 获取类名为c-pagination的div标签,是一个列表
page = soup.select('div .c-pagination')[0]
# 如果标签a标签数大于1,说明多页,取出最后的一个页码,也就是总页数
if len(page.select('a')) > 1:
alist = int(page.select('a')[-2].text)
else:#否则直接取出总页数
alist = int(page.select('span')[0].text)
# 调用方法解析每页数据
saveData(city,url,alist+1)
# for i in range(1,alist + 1):
# urlStr = '%sd%s' % (url,i)
# 调用方法解析每页数据,并且保存到表格中
def saveData(city,url,page):
headers = {
'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36'
}
for i in range(1,page):
html = requests.get(url='%sd%s' % (url,i),headers=headers).content
soup = BeautifulSoup(html,'html.parser')
infos = soup.select('.js_fang_list')[0].select('li')
for info in infos:
# print '*'*50
des = info.find('a',class_="text link-hover-green js_triggerGray js_fanglist_title").text
dd = info.find('div',class_='info-table')
nameInfo = dd.find('a',class_='laisuzhou')
name = nameInfo.text # 每套二手房的小区名称
fangL = dd.find('span').contents[-1].strip().split('|')
room_type = fangL[0].strip() # 每套二手房的户型
size = fangL[1].strip() # 每套二手房的面积
if len(fangL[2].split('/')) == 2:
region = fangL[2].split('/')[0].strip() # 每套二手房所属的区域
loucheng = fangL[2].split('/')[1].strip() # 每套二手房所在的楼层
else:
region = '' # 每套二手房所属的区域
loucheng = fangL[2].strip() # 每套二手房所在的楼层
if len(fangL) != 4:
chaoxiang = '*'
else:
chaoxiang = fangL[3].strip() # 每套二手房的朝向
timeStr = info.find('span',class_='info-col row2-text').contents[-1].strip().lstrip('|')
builtdate = timeStr # 每套二手房的建筑时间
# 每套二手房的总价
price = info.find('span',class_='total-price strong-num').text.strip()+u'万'
# 每套二手房的平方米售价
jun = info.find('span',class_='info-col price-item minor').text
price_union = jun.strip()
cur.execute("insert into lianjia (des,name,room_type,size,region,loucheng,chaoxiang,price,price_union,builtdate) values('%s','%s','%s','%s','%s','%s','%s','%s','%s','%s')" % (des,name,room_type,size,region,loucheng,chaoxiang,price,price_union,builtdate))
# 判断当前运行的脚本是否是该脚本,如果是则执行
# 如果有文件xxx继承该文件或导入该文件,那么运行xxx脚本的时候,这段代码将不会执行
if __name__ == '__main__':
getHtml('jinshan')
cur.close()
conn.commit()
conn.close()
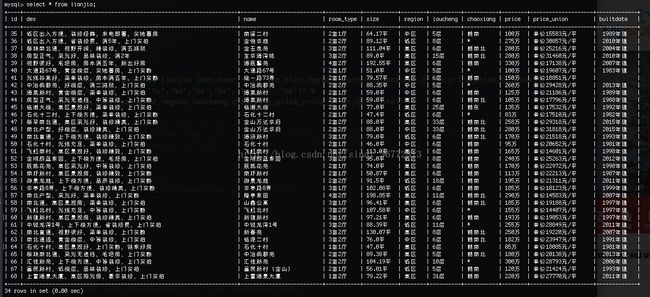
说明:具体mysql如何创建表,如何给表添加字段设置字段数据类型等请自行学习完成。