转载自个人博客
前一篇文章 JStorm:概念与编程模型 介绍了JStorm的基本概念以及编程模型方面的知识,本篇主要介绍自己对JStorm的任务调度方面的认识,主要从三个方面介绍:
- 调度角色
- 调度方法
- 自定义调度
1 调度角色
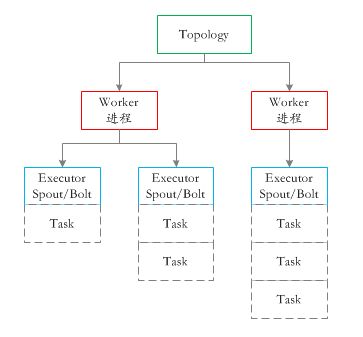
上图是JStorm中一个topology对应的任务执行结构,其中worker是进程,executor对应于线程,task对应着spout或者bolt组件。
1.1 Worker
Worker是task的容器, 同一个worker只会执行同一个topology相关的task。 一个topology可能会在一个或者多个worker(工作进程)里面执行,每个worker执行整个topology的一部分。比如,对于并行度是300的topology来说,如果我们使用50个工作进程来执行,那么每个工作进程会处理其中的6个tasks。Storm会尽量均匀的工作分配给所有的worker。
1.2 Executor
Executor是在worker中的执行线程,在同一类executor中,要么全部是同一个bolt类的task,要么全部是同一个spout类的task,需要注意的是, 一个executor只能同时运行一个task,创建时将多个task设置在一个executor中,在前期Storm中主要考虑的是后期线程扩展(待验证),但是在JStorm中可以在rebalance时改变Task的数量,所以不需要将task数量大于executor。
1.3 Task
Task是真正任务的执行者,对应创建topology时建立的一个bolt或者spout组件。每一个spout和bolt会被当作很多task在整个集群里执行。可以调用TopologyBuilder类的setSpout和setBolt来设置并行度(也就是有多少个task)。
2 调度方法
2.1 默认调度算法
默认调度算法遵循以下的原则:
- 任务调度算法以worker为维度,尽量将平均分配到各个supervisor上;
- 以worker为单位,确认worker与task数目大致的对应关系(注意在这之前已经其他拓扑占用利用的worker不再参与本次动作);
- 建立task-worker关系的优先级依次为:尽量避免同类task在同一work和supervisor下的情况,尽量保证task在worker和supervisor基准上平均分配,尽量保证有直接信息流传输的task在同一worker下。
- 调度过程中正在进行的调度动作不会对已发生的调度动作产生影响
2.2 调度示例
如下是一个topology创建时配置代码,以及运行时的示意图。
//创建topology配置代码
Config conf = new Config();
conf.setNumWorkers(2); // use two worker processes
topologyBuilder.setSpout("blue-spout", new BlueSpout(), 2);
topologyBuilder.setBolt("green-bolt", new GreenBolt(), 2)
.setNumTasks(4)
.shuffleGrouping("blue-spout");
topologyBuilder.setBolt("yellow-bolt", new YellowBolt(), 6)
.shuffleGrouping("green-bolt");
StormSubmitter.submitTopology("mytopology", conf,
topologyBuilder.createTopology());
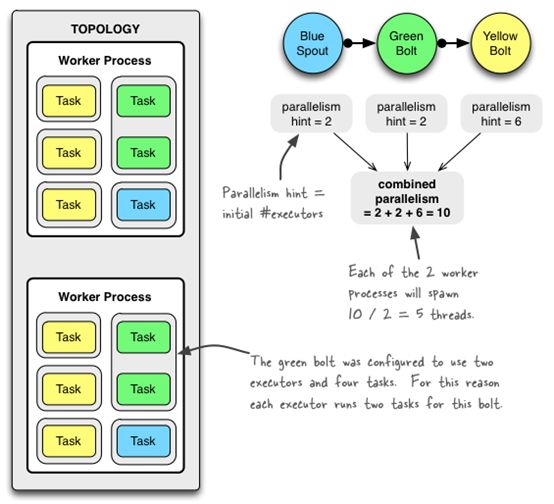
参考以上代码,以及任务调度算法,该拓扑中,设为worker为2,蓝色Spout并发设置为2,task默认与并发相同为2;绿色Bolt执行并发为2,但设置其task为4,所以每个executor中有两个Task,黄色Bolt并发为6,task默认与并发相同为6。
图中两个worker是一致的,可以认为是JStorm分配任务时做的权衡,尽量分配的均匀,不代表所有情况都是如此。
2.3 分发过程
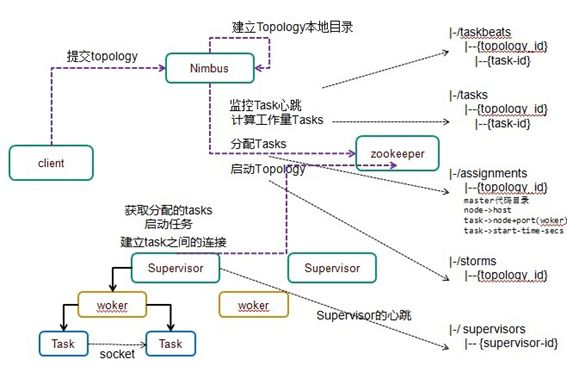
上图是storm的示例,JStorm雷同。
JStorm任务分发过程:
- 客户端提交拓扑到nimbus,并开始执行;
- Nimbus针对该拓扑建立本地的目录,根据topology的配置计算task,分配task,在zookeeper上建立assignments节点存储task和supervisor机器节点中woker的对应关系;
- 在zookeeper上创建taskbeats节点来监控task的心跳;启动topology。
- 各Supervisor去zookeeper上获取分配的tasks,启动多个woker进行,每个woker生成task;根据topology信息初始化建立task之间的连接。
3 自定义调度
JStorm支持一下自定义调度设置:
- 设置每个worker的默认内存大小
ConfigExtension.setMemSizePerWorker(Map conf, long memSize)
- 设置每个worker的cgroup,cpu权重
ConfigExtension.setCpuSlotNumPerWorker(Map conf, int slotNum)
- 设置是否使用旧的分配方式
ConfigExtension.setUseOldAssignment(Map conf, boolean useOld)
- 设置强制某个component的task 运行在不同的节点上
ConfigExtension.setTaskOnDifferentNode(Map componentConf, boolean isIsolate)
注意,这个配置componentConf是component的配置, 需要执行addConfigurations 加入到spout或bolt的configuration当中
- 自定义worker分配
WorkerAssignment worker = new WorkerAssignment();
worker.addComponent(String compenentName, Integer num);//在这个worker上增加一个task
worker.setHostName(String hostName);//强制这个worker在某台机器上
worker.setJvm(String jvm);//设置这个worker的jvm参数
worker.setMem(long mem); //设置这个worker的内存大小
worker.setCpu(int slotNum); //设置cpu的权重大小
ConfigExtension.setUserDefineAssignment(Map conf, List userDefines)
注:每一个worker的参数并不需要被全部设置,worker属性在合法的前提下即使只设置了部分参数也仍会生效
- 强制topology运行在一些supervisor上
在实际应用中, 常常一些机器部署了本地服务(比如本地DB), 为了提高性能, 让这个topology的所有task强制运行在这些机器上
conf.put(Config.ISOLATION_SCHEDULER_MACHINES, List isolationHosts)
conf 是topology的configuration
转载请标明出处