详解 HashMap 中的 hash 函数
阅读本文,你需要花费 16 分钟。相对应的,你将获得以下知识:
- 什么是 hash 函数
- 为什么要使用 hash 函数
- 常见的 hash 算法及冲突解决
- hash 函数在 hashMap 中的运用
1. 什么是 hash 函数
hash 函数,即散列函数,或叫哈希函数。它可以将不定长的输入,通过散列算法转换成一个定长的输出,这个输出就是散列值。需要注意的是,不同的输入通过散列函数,也可能会得到同一个散列值。因此我们不能使用散列函数来获取唯一值。
2. HashMap 为什么要使用 hash 函数
Java 的 HashMap 中使用的是数组 + 链表的结构,但在保存时,一个 K - V 键值对应该被存放到数组的哪个位置?
通常我们都会想到:按照存入顺序存放。但是,按照这种策略,在取值时势必需要遍历整个数组,然后一个个去比较它们的 key 是否相等,这对于性能的损耗无疑是很大的。也许你已经猜到了,解决这个问题的办法就是散列函数。
3. 常见的 hash 算法及冲突的解决
在具体介绍 HashMap 如何使用散列函数之前,先简单介绍一下常见的 hash 算法,以便于你可以更加系统地了解它。
a. 直接定址法:直接以关键字k或者k加上某个常数(k+c)作为哈希地址(H(k)=ak+b)。
b. 数字分析法:提取关键字中取值比较均匀的数字作为哈希地址(如一组出生日期,相较于年-月,月-日的差别要大得多,可以降低冲突概率)
c. 分段叠加法:按照哈希表地址位数将关键字分成位数相等的几部分,其中最后一部分可以比较短。然后将这几部分相加,舍弃最高进位后的结果就是该关键字的哈希地址。
d. 平方取中法:如果关键字各个部分分布都不均匀的话,可以先求出它的平方值,然后按照需求取中间的几位作为哈希地址。
e. 伪随机数法:选择一随机函数,取关键字的随机值作为散列地址,通常用于关键字长度不同的场合。
f. 除留余数法:用关键字k除以某个不大于哈希表长度m的数p,将所得余数作为哈希表地址(H(k)=k%p, p<=m; p一般取m或素数)。
上文已经说到,不同的输入通过散列函数,有可能会得到相同的输出。既然通过不同的输入可以得到相同的输出,那么如果发生冲突了怎么办?比如在 HashMap 中,如果两个不同的 key 计算得出的散列值相同,后来的岂不是会覆盖先来的?不用担心,解决 hash 冲突的方法也是有的,常见的有:
a. 链地址法:将哈希表的每个单元作为链表的头结点,所有哈希地址为 i 的元素构成一个同义词链表。即发生冲突时就把该关键字链在以该单元为头结点的链表的尾部。
b. 开放定址法:即发生冲突时,去寻找下一个空的哈希地址。只要哈希表足够大,总能找到空的哈希地址。
c. 再哈希法:即发生冲突时,由其他的函数再计算一次哈希值。
d. 建立公共溢出区:将哈希表分为基本表和溢出表,发生冲突时,将冲突的元素放入溢出表。
可能你已经注意到,HashMap 就是使用链地址法来解决冲突的(jdk8中采用平衡树来替代链表存储冲突的元素,但hash() 方法原理相同)。数组中的每一个单元都会指向一个链表,如果发生冲突,就将 put 进来的 K- V 插入到链表的尾部。
4. HashMap 是如何使用 hash 函数的
首先,我们来看一下在 HashMap 中,最常用的 put() 和 get() 是怎么使用 hash() 的。以下源码均为 jdk7。
// put()
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
// get()
int hash = hash(key.hashCode());
for (Entry<K,V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k)))
return e.value;
}
可以看到,HashMap 中都是先使用 hash 函数获取一个 hash 值,然后利用得到的 hash 值和容器容量(table.length)计算对象的存放位置(indexFor() 方法)。我们再详细看一下 hash() 和 indexFor() 两个方法。
static int hash(int h) {
return h ^ (h >>> 7) ^ (h >>> 4);
}
static int indexFor(int h, int length) {
return h & (length-1);
}
通过 put() 方法和 get() 方法,我们可以知道,hash() 方法中的参数 h, h = key.hashCode,hash() 方法对 hashCode 分别无符号右移 (>>>) 7 位和 4 位,再与自身进行异或(^)处理。 这么做的目的是什么?
由于 indexFor() 返回的是 h(hash 值) 与 length - 1(容器容量 - 1) 进行按位与运算的结果,若不进行扰动,即 h = key.hashCode(注意,这里的 h 是 indexFor() 方法的参数,即 hash() 方法的返回值,而非 hash() 方法的参数 h),这将会很容易发生冲突。如下图所示,当低位相同时, h & (length - 1) 结果也会是一样的。即 indexFor() 的计算结果只与 hashCode 的低位相关。
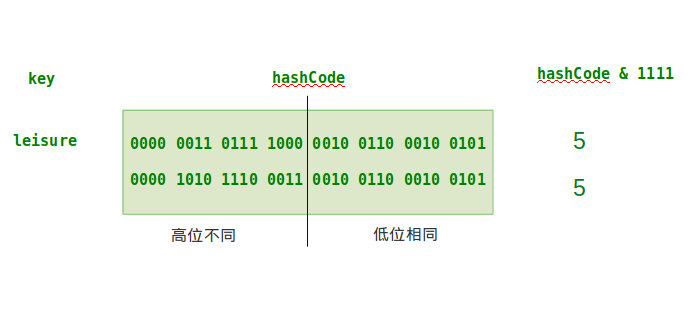
在经过扰动算法后,结果如下:

可以明显看到,计算出来的 hash 值不一样了,即二者不会再发生冲突。这就是为什么 hash() 方法中要使用扰动算法:可以有效降低冲突概率。
既然已经解决了 hash() 的计算问题,那么接下来就是计算索引了。
HashMap 通过 hash 值与 length-1 (容器长度-1)进行取模(%)运算。可能有人会问:明明源码中 indexFor() 方法进行的 按位与(&)运算,而非取模运算。
实际上,HashMap 中的 indexFor() 方法就是在进行取模运算。利用位运算代替取模运算,可以大大提高程序的计算效率。位运算可以直接对内存数据进行操作,不需要转换成十进制,因此效率要高得多。
需要注意的是,只有在特定情况下,位运算才可以转换成取模运算(当 b = 2^n 时,a % b = a & (b - 1) )。也是因此,HashMap 才将初始长度设置为 16,且扩容只能是以 2 的倍数(2^n)扩容。
5. 总结
a. hash 函数并不能保证得到唯一的输出值,不同的输入也有可能得到相同的输出。
b. HashMap 中的 hash() 方法,将 hashCode 的高位和低位混合起来,降低冲突概率。
c. HashMap 中解决冲突的办法是采用链地址法(jdk7)。
d. HashMap 的初始长度为 16,且每次扩容都必须以 2 的倍数(2^n)扩充。因为在 HashMap 中,采用按位与运算(&)代替取模运算(&),当 b = 2^n 时,a % b = a & (b - 1) 。
觉得有用就关注一下我的公众号 Java白痴 吧,一个只做干货的微信公众号
