python多线程爬取ts文件并合成mp4视频
python多线程爬取ts文件并合成mp4视频
声明:仅供技术交流,请勿用于非法用途,如有其它非法用途造成损失,和本博客无关
目录
- python多线程爬取ts文件并合成mp4视频
- 前言
- 一、分析页面
- 二、整体思路逻辑
- 三、开始编写代码
- 四、一些技巧
- 写在最后
前言
在我看来,爬取视频可以分为简单、中等以及困难三种级别。
- 简单级别:网页直接给出了mp4格式的视频链接,所以可以像下载图片一样发个请求就可以轻松获得
- 中等级别:就是网页给出的是ts文件,所有的ts文件会存储在一个m3u8文件中,我们请求这个m3u8文件即可拿到全部的ts文件的请求网址,然后把全部的ts都下载下来,最后再将它们合成一个mp4格式的视频就行
- 困难级别:其实就是在中等级别的基础上,网站给出的m3u8文件不会明文给你看到所有的ts文件,而是会利用一些加密的算法,将其加密
那么,本文爬取视频的级别是中等。爬取的视频网址:点击跳转
废话不多说,下面直接开始吧
一、分析页面
首先打开开发者工具,可以看到每一集对应的url存在一个li的列表当中
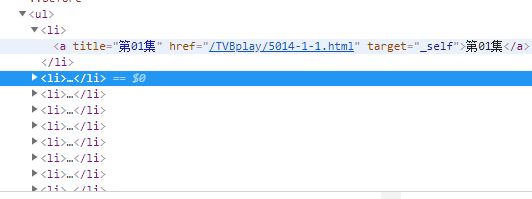
然后点开到第一集视频播放页面,再次打开开发者工具,点击network之后刷新页面,可以看到在第二个m3u8文件中出现了所有的ts文件,那么,这就是我们要找的东西了,只是这个ts文件的网址不全
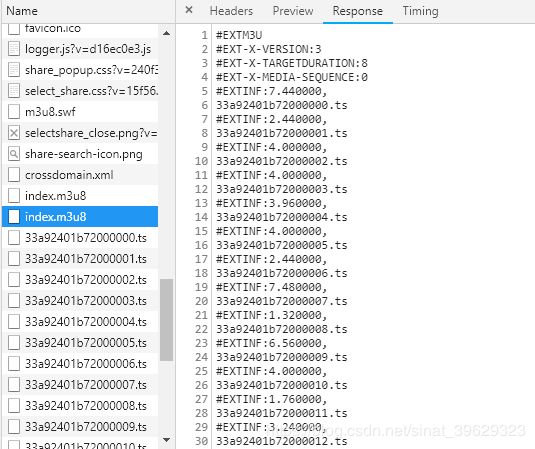
再看看第一个m3u8的文件响应中有1024k/hls/index.m3u8这么个字符串,可以知道,这个其实是第二个m3u8文件网址的末尾部分,并且ts文件网址也只是修改了第二个m3u8文件的末尾而已。ok,到这里已经知道全部的ts文件网址了,只要拿到第一个m3u8文件的网址即可。
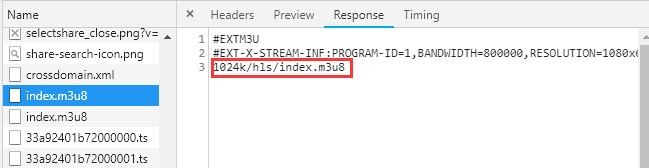
第一个m3u8:https://mojing.huoyanzuida.com/20200424/2487_d0fc7191/index.m3u8
第二个m3u8:https://mojing.huoyanzuida.com/20200424/2487_d0fc7191/1024k/hls/index.m3u8
第一个ts:https://mojing.huoyanzuida.com/20200424/2487_d0fc7191/1024k/hls/33a92401b72000000.ts
接下来,就是要找出第一个m3u8跟之前的网址存在什么联系,首先全局搜索一下“m3u8”,发现在5014.js这个文件中发现了一个用base64加密了的字符串,
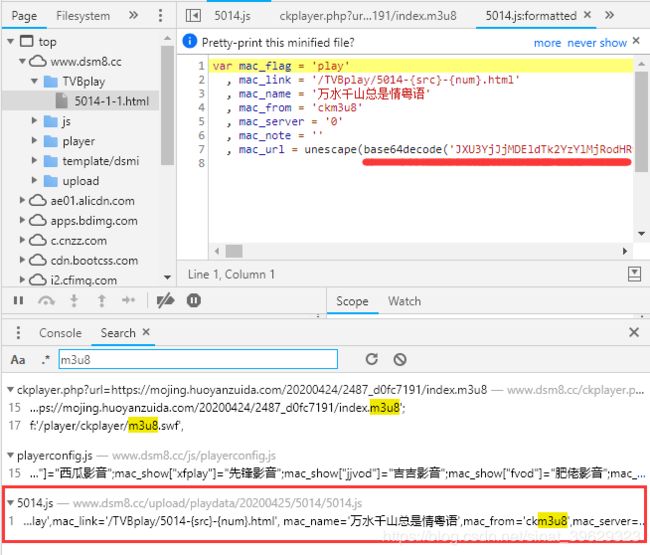
将其解密之后得到:
%u7b2c01%u96c6%24https%3A%2F%2Fmojing.huoyanzuida.com%2F20200424%2F2487_d0fc7191%2Findex.m3u8%23%u7b2c02%u96c6%24https%3A%2F%2Fmojing.huoyanzuida.com%2F20200424%2F2484_640df7e0%2Findex.m3u8%23%u7b2c03%u96c6%24https%3A%2F%2Fmojing.huoyanzuida.com%2F20200424%2F2490_0b2ee7ab%2Findex.m3u8%23%u7b2c04%u96c6%24https%3A%2F%2Fmojing.huoyanzuida.com%2F20200424%2F2485_029c4007%2Findex.m3u8%23%u7b2c05%u96c6%24https%3A%2F%2Fmojing.huoyanzuida.com%2F20200424%2F2486_957bb1f3%2Findex.m3u8%23%u7b2c06%u96c6%24https%3A%2F%2Fmojing.huoyanzuida.com%2F20200424%2F2488_06dae5ae%2Findex.m3u8%23%u7b2c07%u96c6%24https%3A%2F%2Fmojing.huoyanzuida.com%2F20200424%2F2497_4350d451%2Findex.m3u8%23%u7b2c08%u96c6%24https%3A%2F%2Fmojing.huoyanzuida.com%2F20200424%2F2489_677b9744%2Findex.m3u8%23%u7b2c09%u96c6%24https%3A%2F%2Fmojing.huoyanzuida.com%2F20200424%2F2495_3e03853a%2Findex.m3u8%23%u7b2c10%u96c6%24https%3A%2F%2Fmojing.huoyanzuida.com%2F20200424%2F2491_de7cb550%2Findex.m3u8%23%u7b2c11%u96c6%24https%3A%2F%2Fmojing.huoyanzuida.com%2F20200424%2F2492_e8221393%2Findex.m3u8%23%u7b2c12%u96c6%24https%3A%2F%2Fmojing.huoyanzuida.com%2F20200424%2F2493_5b52e7e5%2Findex.m3u8%23%u7b2c13%u96c6%24https%3A%2F%2Fmojing.huoyanzuida.com%2F20200424%2F2494_8ebe1863%2Findex.m3u8%23%u7b2c14%u96c6%24https%3A%2F%2Fmojing.huoyanzuida.com%2F20200424%2F2496_a814c3b3%2Findex.m3u8%23%u7b2c15%u96c6%24https%3A%2F%2Fmojing.huoyanzuida.com%2F20200424%2F2500_cafb68ab%2Findex.m3u8%23%u7b2c16%u96c6%24https%3A%2F%2Fmojing.huoyanzuida.com%2F20200424%2F2498_9e696bf2%2Findex.m3u8%23%u7b2c17%u96c6%24https%3A%2F%2Fmojing.huoyanzuida.com%2F20200424%2F2499_0015700c%2Findex.m3u8%23%u7b2c18%u96c6%24https%3A%2F%2Fmojing.huoyanzuida.com%2F20200424%2F2502_c39cb88d%2Findex.m3u8%23%u7b2c19%u96c6%24https%3A%2F%2Fmojing.huoyanzuida.com%2F20200424%2F2501_c12a81f8%2Findex.m3u8%23%u7b2c20%u96c6%24https%3A%2F%2Fmojing.huoyanzuida.com%2F20200424%2F2503_5fd7c956%2Findex.m3u8%23%u7b2c21%u96c6%24https%3A%2F%2Fmojing.huoyanzuida.com%2F20200424%2F2553_5efba16b%2Findex.m3u8%23%u7b2c22%u96c6%24https%3A%2F%2Fmojing.huoyanzuida.com%2F20200424%2F2510_41b6e254%2Findex.m3u8%23%u7b2c23%u96c6%24https%3A%2F%2Fmojing.huoyanzuida.com%2F20200424%2F2508_92bd89a2%2Findex.m3u8%23%u7b2c24%u96c6%24https%3A%2F%2Fmojing.huoyanzuida.com%2F20200424%2F2504_02863479%2Findex.m3u8%23%u7b2c25%u96c6%24https%3A%2F%2Fmojing.huoyanzuida.com%2F20200424%2F2505_45f36385%2Findex.m3u8%23%u7b2c26%u96c6%24https%3A%2F%2Fmojing.huoyanzuida.com%2F20200424%2F2506_307718a8%2Findex.m3u8%23%u7b2c27%u96c6%24https%3A%2F%2Fmojing.huoyanzuida.com%2F20200424%2F2507_2d365300%2Findex.m3u8%23%u7b2c28%u96c6%24https%3A%2F%2Fmojing.huoyanzuida.com%2F20200424%2F2509_2c9d20a5%2Findex.m3u8%23%u7b2c29%u96c6%24https%3A%2F%2Fmojing.huoyanzuida.com%2F20200424%2F2512_47a6b558%2Findex.m3u8%23%u7b2c30%u96c6%24https%3A%2F%2Fmojing.huoyanzuida.com%2F20200424%2F2511_da5c4e6f%2Findex.m3u8
然后在通过urllib.parse.unquote方法解析得到:
b'%u7b2c01%u96c6$https://mojing.huoyanzuida.com/20200424/2487_d0fc7191/index.m3u8#%u7b2c02%u96c6$https://mojing.huoyanzuida.com/20200424/2484_640df7e0/index.m3u8#%u7b2c03%u96c6$https://mojing.huoyanzuida.com/20200424/2490_0b2ee7ab/index.m3u8#%u7b2c04%u96c6$https://mojing.huoyanzuida.com/20200424/2485_029c4007/index.m3u8#%u7b2c05%u96c6$https://mojing.huoyanzuida.com/20200424/2486_957bb1f3/index.m3u8#%u7b2c06%u96c6$https://mojing.huoyanzuida.com/20200424/2488_06dae5ae/index.m3u8#%u7b2c07%u96c6$https://mojing.huoyanzuida.com/20200424/2497_4350d451/index.m3u8#%u7b2c08%u96c6$https://mojing.huoyanzuida.com/20200424/2489_677b9744/index.m3u8#%u7b2c09%u96c6$https://mojing.huoyanzuida.com/20200424/2495_3e03853a/index.m3u8#%u7b2c10%u96c6$https://mojing.huoyanzuida.com/20200424/2491_de7cb550/index.m3u8#%u7b2c11%u96c6$https://mojing.huoyanzuida.com/20200424/2492_e8221393/index.m3u8#%u7b2c12%u96c6$https://mojing.huoyanzuida.com/20200424/2493_5b52e7e5/index.m3u8#%u7b2c13%u96c6$https://mojing.huoyanzuida.com/20200424/2494_8ebe1863/index.m3u8#%u7b2c14%u96c6$https://mojing.huoyanzuida.com/20200424/2496_a814c3b3/index.m3u8#%u7b2c15%u96c6$https://mojing.huoyanzuida.com/20200424/2500_cafb68ab/index.m3u8#%u7b2c16%u96c6$https://mojing.huoyanzuida.com/20200424/2498_9e696bf2/index.m3u8#%u7b2c17%u96c6$https://mojing.huoyanzuida.com/20200424/2499_0015700c/index.m3u8#%u7b2c18%u96c6$https://mojing.huoyanzuida.com/20200424/2502_c39cb88d/index.m3u8#%u7b2c19%u96c6$https://mojing.huoyanzuida.com/20200424/2501_c12a81f8/index.m3u8#%u7b2c20%u96c6$https://mojing.huoyanzuida.com/20200424/2503_5fd7c956/index.m3u8#%u7b2c21%u96c6$https://mojing.huoyanzuida.com/20200424/2553_5efba16b/index.m3u8#%u7b2c22%u96c6$https://mojing.huoyanzuida.com/20200424/2510_41b6e254/index.m3u8#%u7b2c23%u96c6$https://mojing.huoyanzuida.com/20200424/2508_92bd89a2/index.m3u8#%u7b2c24%u96c6$https://mojing.huoyanzuida.com/20200424/2504_02863479/index.m3u8#%u7b2c25%u96c6$https://mojing.huoyanzuida.com/20200424/2505_45f36385/index.m3u8#%u7b2c26%u96c6$https://mojing.huoyanzuida.com/20200424/2506_307718a8/index.m3u8#%u7b2c27%u96c6$https://mojing.huoyanzuida.com/20200424/2507_2d365300/index.m3u8#%u7b2c28%u96c6$https://mojing.huoyanzuida.com/20200424/2509_2c9d20a5/index.m3u8#%u7b2c29%u96c6$https://mojing.huoyanzuida.com/20200424/2512_47a6b558/index.m3u8#%u7b2c30%u96c6$https://mojing.huoyanzuida.com/20200424/2511_da5c4e6f/index.m3u8'
可以清楚地看到其中具体的网址了,并且可以看到第一个网址正是我们第一个m3u8文件的网址,并且还发现了,这里包含了这个电视剧所有集数的m3u8文件网址,这就太棒了,不用去请求每一集来获取m3u8文件了。不过还没有完,就是这个5014.js的文件网址要去那里找呢?正是在视频播放页的网页源代码当中:
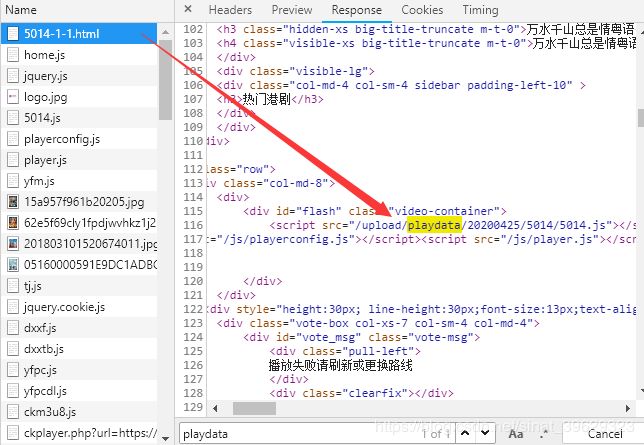
二、整体思路逻辑
1,首先在视频播放页的网页源代码中拿到那个js文件,接着请求这个js,拿到其响应中的通过base64加密的字符串
2,然后解密这个字符串,拿到所有集数的第一个m3u8文件网址,接着通过两个m3u8文件之间存在的关系,拿到所有集数的第二个m3u8文件网址,也就是用来保存所有ts文件的那个m3u8
3,再通过m3u8和ts这两个网址之间的关系,拿到所有的对应集数的全部的ts文件网址
4,最后,就可以通过Python多线程将它们下载下来,并合成mp4视频
三、开始编写代码
# 导入相关包或模块
import threading, queue
import time, os, subprocess
import requests, urllib, parsel
import random, re, base64
# 拿到播放页网址
def get_bofangye_url(url):
r=requests.get(url,headers=headers)
response=parsel.Selector(r.text)
bofangye_url='https://www.dsm8.cc' + response.xpath('//div[@id="vlink_1"]/ul/li/a/@href').get()
return bofangye_url
# 拿到js文件网址
def get_js_url(bofangye_url):
r=requests.get(bofangye_url,headers=headers)
response=parsel.Selector(r.text)
js_url='https://www.dsm8.cc'+response.xpath('//div[@id="flash"]/script/@src').get()
return js_url
# 拿到所有的m3u8文件网址
def get_all_url(js_url):
r=requests.get(js_url,headers=headers)
a=re.findall("base64decode\('(.*?)\)",r.text)[0]
temp_url=re.findall('\$(.*?)\#',urllib.parse.unquote(str(base64.b64decode(a))))
r=requests.get(temp_url[0],headers=headers)
all_url=[]
for i in temp_url:
all_url.append(i.replace('index.m3u8',r.text.split('\n')[-1]))
return all_url
# 下载ts文件
def download_ts(urlQueue):
while True:
try:
#不阻塞的读取队列数据
url = urlQueue.get_nowait()
n=int(url[-6:-3])
except Exception as e:
break
response=requests.get(url,stream=True,headers=headers)
ts_path = "./ts/%03d.ts"%n # 注意这里的ts文件命名规则
with open(ts_path,"wb+") as file:
for chunk in response.iter_content(chunk_size=1024):
if chunk:
file.write(chunk)
print("%03d.ts OK..."%n)
if __name__ == '__main__':
url='https://www.dsm8.cc/TVB/wanshuiqianshanzongshiqingyueyu.html' # 万水千山总是情粤语版
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3741.400 QQBrowser/10.5.3863.400'}
bofangye_url=get_bofangye_url(url)
js_url=get_js_url(bofangye_url)
all_url=get_all_url(js_url)
# 下面开始循环下载所有剧集
for num,url in enumerate(all_url):
r=requests.get(url,headers=headers)
urlQueue = queue.Queue()
for i in r.text.split('\n'):
if i.endswith('.ts'):
urlQueue.put(url.replace('index.m3u8',i))
# 下面开始多线程下载
startTime = time.time()
threads = []
# 可以适当调节线程数,进而控制抓取速度
threadNum = 4
for i in range(threadNum):
t = threading.Thread(target=download_ts, args=(urlQueue,))
threads.append(t)
for t in threads:
t.start()
for t in threads:
t.join()
endTime = time.time()
print ('Done, Time cost: %s ' % (endTime - startTime))
# 下面是执行cmd命令来合成mp4视频
command=r'copy/b D:\python3.7\HEHE\爬虫\ts\*.ts D:\python3.7\HEHE\爬虫\mp4\万水千山总是情-第{0}集.mp4'.format(num+1)
output=subprocess.getoutput(command)
print('万水千山总是情-第{0}集.mp4 OK...'.format(num+1))
# 下面是把这一集所有的ts文件给删除
file_list = []
for root, dirs, files in os.walk('D:/python3.7/HEHE/爬虫/ts'):
for fn in files:
p = str(root+'/'+fn)
file_list.append(p)
for i in file_list:
os.remove(i)
四、一些技巧
- ts合成mp4的cmd命令(在ts文件的路径下):
copy/b *.ts xxx.mp4 - ts文件的命名规则:要类似这样的 000.ts,001.ts……,这样合成的mp4才不会乱套
- 下完一集并合成mp4之后要及时删除ts文件
写在最后
- 时隔3个月,我又来写博客啦,因为之前一直在忙毕业论文的事情,现在终于有空了。
- 那么,我为什么写这篇博客呢,其实主要是因为最近一直在爬这个网站的视频,并且爬的净是些很久之前的粤语电视剧,然后上传到天翼云盘,再在电视机上播放给我爸看的,这不,天翼云盘之前免费送了3个月黄金会员,送的内存直接是用不完的节奏呀,害得我想用电视剧把它给填满哈哈。
- 那可能又有人会问了,直接找资源下载它不香吗?这其实我也是被逼无奈呀,这些很久远的电视剧资源是真的少,而且又要是粤语版的,就更是少得可怜,并且好不容易找到了,可是是在百度网盘上的,那个下载速度慢的呀,所以我才会想到用爬虫来搞,然后就找到了这网站,真的太多粤语剧了,爽歪歪呀。
- 最后如果大家遇到了那种困难级别的网站也可以跟我分享一下哦
最近我开了个微信公众号,也会在公众号同步文章的哦,大家有需要可以点点关注,谢谢!
ps:在公众号中回复20200526,即可拿到本文的源代码
