JVM 后台IO阻塞导致GC停顿时间长
本文是个译文
问题:
当JVM管理的Java堆空间进行垃圾回收后,JVM可能会停顿,并对应用程序造成STW停顿。根据在启动Java实例时指定的JVM选项,GC日志文件会记录不同类型的GC和JVM行为。
虽然某些因为GC导致的STW停顿(扫描/标记/压缩堆对象)已经被大家熟知,但是我们发现后台IO负载也会造成长时间的STW停顿。在我们的生产环境中曾经出现过,一些关键的Java应用程序发生许多无法解释的长时间STW停顿(> 5秒) 。这些停顿既不能从应用程序层的逻辑、也无法从JVM GC行为的角度加以解释。如下所示,我们展示了一个超过4秒的长时间STW停顿,以及一些GC信息。当时我们选择的垃圾回收器是G1。在一个只有8GB堆内存和使用并行Young Garbage Collection的G1环境下,垃圾回收通常不需要1秒即可完成,并且GC日志的影响也微乎其微。但是应用程序线程却停顿了超过4秒。所有GC完成的工作总量(例如,回收的堆大小)也无法解释这个长达4.17秒的停顿。
2015-12-20T16:09:04.088-0800: 95.743: [GC pause (G1 Evacuation Pause) (young) (initial-mark) 8258M->6294M(10G), 0.1343256 secs] 2015-12-20T16:09:08.257-0800: 99.912: Total time for which application threads were stopped: 4.1692476 seconds
使用G1收集器时一次4.17秒的GC STW停顿
另一个例子,下面的GC日志显示了另一次11.45秒的STW停顿。这次使用的垃圾回收器是CMS(Concurrent Mark Sweep)。其中“user”/“sys”的时间几乎可以忽略,但是“real”表示的GC时间却超过了11秒。通过最后一行,我们可以确定应用程序发生了11.45秒的停顿。
2016-01-14T22:08:28.028+0000: 312052.604: [GC (Allocation Failure) 312064.042: [ParNew Desired survivor size 1998848 bytes, new threshold 15 (max 15) - age 1: 1678056 bytes, 1678056 total : 508096K->3782K(508096K), 0.0142796 secs] 1336653K->835675K(4190400K), 11.4521443 secs] [Times: user=0.18 sys=0.01, real=11.45 secs] 2016-01-14T22:08:39.481+0000: 312064.058: Total time for which application threads were stopped: 11.4566012 seconds
使用CMS收集器时一次11.45秒的GC STW停顿
由于应用程序要求非常低的延迟,所以我们花费了相当多的精力来调查这个问题。最后,我们成功重现了这个问题,发现了根本原因,以及相应的解决方案。
分析:
后台IO我们通过一个bash脚本,不断地复制大文件来模拟。后台程序会生成150MB/s的写入负载,可以使一个普通磁盘的IO变得足够繁忙。为了更好理解生成的IO负载的压力大小,我们使用“sar -d -p 2”来收集await(磁盘处理IO请求的平均时间(以毫秒计)),tps(每秒发往物理设备的传输总数)和wr_sec-per-s(写入设备的扇区数)。它们分别的平均数值为:await=421 ms, tps=305, wr_sec-per-s=302K。
不含后台IO
运行基准线测试不需要有后台IO。所有JVM GC 停顿的时间序列数据没有观察到超过250ms的停顿
包含后台IO
当后台IO开始运行后,在只有5分钟的运行时间内,压测程序就出现了一次超过3.6秒的STW停顿,以及3次超过0.5秒的停顿!
为了了解是哪个系统调用引起了STW停顿,我们使用了strace来分析JVM实例产生的系统调用。
我们首先确认了JVM将GC信息记录到文件,使用的是异步IO的方式。我们又跟踪了JVM从启动后产生的所有系统调用。GC日志文件在异步模式下打开,并且没有观察到fsync()调用。
16:25:35.411993 open("gc.log", O_WRONLY|O_CREAT|O_TRUNC, 0666) = 3 <0.000073>
所捕获的用于打开GC日志文件的JVM系统调用open()
但是,跟踪结果显示,JVM发起的几个异步系统调用write()出现了不同寻常的长时间执行情况。通过检查系统调用和JVM停顿的时间戳,我们发现它们恰好吻合。
换句话说,实际的STW停顿时间包含两部分:(1) GC时间(例如,young GC)和 (2)GC记录日志的时间(例如, 调用write()的时间)。
这些数据说明,GC记录日志的过程发生在JVM的STW停顿过程中,并且记录日志所用的时间也属于STW停顿时间的一部分。特别需要说明,整个应用程序的停顿主要由两部分组成:由于JVM GC行为造成的停顿,以及为了记录JVM GC日志,系统调用write()被OS阻塞的时间。下面这张图展示了二者之间的关系。
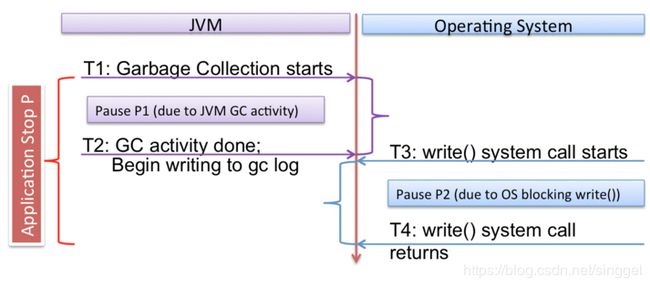
如果记录GC日志的过程(例如write()调用)被OS阻塞,阻塞时间也会被计算到STW的停顿时间内。新的问题是,为什么带有缓存的写入会被阻塞?在深入了解各种资料,包括操作系统内核的源代码之后,我们意识到带有缓存的写入可能被内核代码所阻塞。这里面有多重原因,包括:(1)“stable page write”和(2)“journal committing”。
Stable page write: JVM对GC日志文件的写入,首先会使得相应的文件缓存页“变脏”。即使缓存页稍后会通过OS的回写机制被持久化到磁盘文件,但是在内存中使缓存页变脏的过程,由于“stable page write”仍然会受到页竞争的影响。在“stable page write”下,如果某页正处于OS回写过程中,那么对该页的write()调用就不得不等待回写完成。为了避免只有一部分新页被持久化到磁盘上,内核会锁定该页以确保数据一致性。
Journal committing: 对于带有日志(journaling)的文件系统,在写文件时都会生成相应的journal日志。当JVM向GC日志文件追加内容时,会产生新的块,因此文件系统则需要先将journal日志数据提交到磁盘。在提交journal日志的过程中,如果OS还有其他的IO行为,则提交可能需要等待。如果后台的IO行为非常繁重,那么等待时间可能会非常长。注意,EXT4文件系统有一个“delayed allocation”功能,可以将journal数据提交延迟到OS回写后再进行,从而降低等待时间。还要注意的是,将EXT4的数据模式从默认的“ordered”改成“writeback”并不能解决这个问题,因为journal数据需要在write-to-extend调用返回之前被持久化。
解决:
由于当前HotSpot JVM实现(包括其他实现)中,GC日志会被后台的IO行为所阻塞,所以有一些解决方案可以避免写GC日志文件的问题。
首先,JVM实现完全可以解决掉这个问题。显然,如果将写GC日志的操作与可能会导致STW停顿的JVM GC处理过程分开,这个问题自然就不存在了。例如,JVM可以将记录GC日志的功能放到另一个线程中,独立来处理日志文件的写入,这样就不会增加STW停顿的时间了。但是,这种采用其他线程来处理的方式,可能会导致在JVM崩溃时丢失最后的GC日志信息。最好的方式,可能是提供一个JVM选项,让用户来选择适合的方式。
由于后台IO造成的STW停顿时间,与IO的繁重程度有关,所以我们可以采用多种方式来降低后台IO的压力。例如,不要在同一节点上安装其他IO密集型的应用程序,减少其他类型的日志行为,提高日志回滚频率等等。
对于低延迟应用程序(例如需要提供用户在线互动的程序),长时间的STW停顿(例如>0.25秒)是不可忍受的。因此,必须进行有针对性的优化。如果要避免因为OS导致的长时间STW停顿,首要措施就是要避免因为OS的IO行为导致写GC日志被阻塞。
一个解决办法是将GC日志文件放到tmpfs上(例如,-Xloggc:/tmpfs/gc.log)。因为tmpfs没有磁盘文件备份,所以tmpfs文件不会导致磁盘行为,因此也不会被磁盘IO阻塞。
但是,这种方法存在两个问题:
(1)当系统崩溃后,GC日志文件将会丢失;
(2)它需要消耗物理内存。补救的方法是周期性的将日志文件备份到持久化存储上,以减少丢失量。
另一个办法是将GC日志文件放到SSD(固态硬盘,Solid-State Drives)上,它通常能提供更好的IO性能。根据IO负载情况,可以选择专门为GC日志提供一个SSD作为存储,或者与其他IO程序共用SSD。不过,这样就需要将SSD的成本考虑在内。
与使用SSD这样高成本的方案相比,更经济的方式是将GC日志文件放在单独一个HDD磁盘上。由于这块磁盘上只有记录GC日志的IO行为,所以这块专有的HDD磁盘应该可以满足低停顿的JVM性能要求。实际上,我们之前演示的场景一就可以看做为这一方案,因为在记录GC日志的磁盘上没有任何其他的IO行为。
结论:
有低延迟要求的Java应用程序需要极短的JVM GC停顿。但是,当磁盘IO压力很大时,JVM可能被阻塞一段较长的时间。
我们对该问题进行了调查,并且发现如下原因:
- JVM GC需要通过发起系统调用write(),来记录GC行为。
- write()调用可以被后台磁盘IO所阻塞。
- 记录GC日志属于JVM停顿的一部分,因此write()调用的时间也会被计算在JVM STW的停顿时间内。
我们提出了一系列解决该问题的方案。重要的是,我们的发现可以帮助JVM实现来改进该问题。对于低延迟应用程序来说,最简单有效的措施是将GC日志文件放到单独的HDD或者高性能磁盘(例如SSD)上,来避免IO竞争。
参考链接:
https://engineering.linkedin.com/blog/2016/02/eliminating-large-jvm-gc-pauses-caused-by-background-io-traffic