ceph存储 ceph-deploy部署挂载目录的osd
所以如果只有一个单节点的话,需要在ceph deploy new命令之后紧接着执行下列命令修改ceph.conf配置:
echo "osd crush chooseleaf type = 0" >> ceph.conf
echo "osd pool default size = 1" >> ceph.conf
osd crush chooseleaf type参数很重要,解释见:https://ceph.com/docs/master/rados/configuration/ceph-conf/
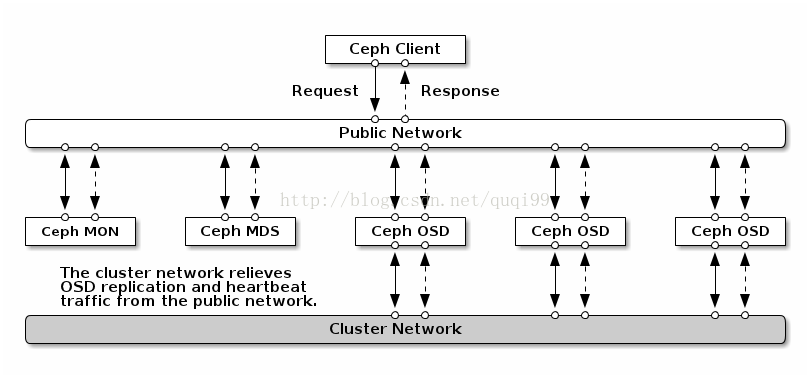
b, 多个网卡的话,可在ceph.conf的[global]段中添加public network = {cidr}参数
c, 一个osd块设备最好大于5G,不然创建日志系统时会空间太小, 或修改:
echo "osd journal size = 100" >> ceph.conf
d, 测试时不想那么涉及权限那么麻烦,可以
echo "auth cluster required = none" >> ceph.conf
echo "auth service required = none" >> ceph.conf
echo "auth client required = none" >> ceph.conf
e, 想使用权限的话,步骤如下:
一旦 cephx 启用, ceph 会在默认的搜索路径寻找 keyring , 像 /etc/ceph/ceph.$name.keyring 。可以的 ceph 配置文件的 [global] 段,加入 keyring 配置指定这个路径。但不推荐这样做。
创建 client.admin key , 并在你的 client host 上保存一份
$ ceph auth get-or-create client.admin mon 'allow *' mds 'allow *' osd 'allow *' -o /etc/ceph/ceph.client.admin.keyring
注意 : 此命令会毁坏己有的 /etc/ceph/ceph.client.admin.keyring 。
为你的 cluster 创建一个 keyring ,创建一个 monitor 安全 key
$ ceph-authtool --create-keyring /tmp/ceph.mon.keyring --gen-key -n mon. --cap mon 'allow *'
复制上面创建的 monitor keyring 到所有 monitor 的 mon data 目录,并命名为 ceph.mon.keyring 。例如,复制它到 cluster ceph 的 mon.a monitor
$ cp /tmp/ceph.mon.keyring /var/lib/ceph/mon/ceph-$(hostname)/keyring
为所有 OSD 生成安全 key , {$id} 指 OSD number
$ ceph auth get-or-create osd.{$id} mon 'allow rwx' osd 'allow *' -o /var/lib/ceph/osd/ceph-{$id}/keyring
为所有 MDS 生成安全 key , {$id} 指 MDS letter
$ ceph auth get-or-create mds.{$id} mon 'allow rwx' osd 'allow *' mds 'allow *' -o /var/lib/ceph/mds/ceph-{$id}/keyring
为 0.51 版本以上的 ceph 启动 cephx 认证,在配置文件的 [global] 段加入
auth cluster required = cephx
auth service required = cephx
auth client required = cephx
环境准备
单节点node1上同时安装osd(一块块设备/dev/ceph-volumes/lv-ceph0),mds, mon, client与admin。
1, 确保/etc/hosts
127.0.0.1 localhost
192.168.99.116 node1
2, 确保安装ceph-deply的机器和其它所有节点的ssh免密码访问(ssh-keygen && ssh-copy-id othernode)
安装步骤(注意,下面所有的操作均在admin节点进行)
1, 准备两块块设备(块设备可以是硬盘,也可以是LVM卷),我们这里使用文件裸设备模拟
dd if=/dev/zero of=/bak/images/ceph-volumes.img bs=1M count=4096 oflag=direct
sgdisk -g --clear /bak/images/ceph-volumes.img
sudo vgcreate ceph-volumes $(sudo losetup --show -f /bak/images/ceph-volumes.img)
sudo lvcreate -L2G -nceph0 ceph-volumes
sudo lvcreate -L2G -nceph1 ceph-volumes
sudo mkfs.xfs -f /dev/ceph-volumes/ceph0
sudo mkfs.xfs -f /dev/ceph-volumes/ceph1
mkdir -p /srv/ceph/{osd0,osd1,mon0,mds0}
sudo mount /dev/ceph-volumes/ceph0 /srv/ceph/osd0
sudo mount /dev/ceph-volumes/ceph1 /srv/ceph/osd1
若想直接使用裸设备的话,直接用losetup加载即可: sudo losetup --show -f /bak/images/ceph-volumes.img
2, 安装ceph-deploy
sudo apt-get install ceph ceph-deploy
3, 找一个工作目录创建集群, ceph-deploy new {ceph-node} {ceph-other-node}
mkdir ceph-cluster
cd /bak/work/ceph/ceph-cluster
ceph-deploy new node1 #如果是多节点,就将节点都列在后面
它将在当前目录生成ceph.conf及ceph.mon.keyring (这个相当于人工执行: ceph-authtool --create-keyring ceph.mon.keyring --gen-key -n mon. --cap mon "allow *' )
如果只有一个节点,还需要执行:
echo "osd crush chooseleaf type = 0" >> ceph.conf
echo "osd pool default size = 1" >> ceph.conf
echo "osd journal size = 100" >> ceph.conf
最终ceph.conf的内容如下:
[global]
fsid = f1245211-c764-49d3-81cd-b289ca82a96d
mon_initial_members = node1
mon_host = 10.55.61.177
auth_cluster_required = cephx
auth_service_required = cephx
auth_client_required = cephx
filestore_xattr_use_omap = true
osd crush chooseleaf type = 0
osd pool default size = 1
osd journal size = 100
也可继续为ceph指定网络,下面两个参数可配置在每个段之中:
cluster network = 10.0.0.0/8
public network = 192.168.5.0/24
4, 安装Ceph基本库(ceph, ceph-common, ceph-fs-common, ceph-mds, gdisk), ceph-deploy install {ceph-node}[{ceph-node} ...]
ceph-deploy purgedata node1
ceph-deploy forgetkeys
ceph-deploy install node1 #如果是多节点,就将节点都列在后面
它会执行,sudo env DEBIAN_FRONTEND=noninteractive DEBIAN_PRIORITY=critical apt-get -q -o Dpkg::Options::=--force-confnew --no-install-recommends --assume-yes install -- ceph ceph-mds ceph-common ceph-fs-common gdisk
5, 增加一个集群监视器, ceph-deploy mon create {ceph-node}
sudo chown -R hua:root /var/run/ceph/
sudo chown -R hua:root /var/lib/ceph/
ceph-deploy --overwrite-conf mon create node1 #如果是多节点就将节点都列在后面
相当于:
sudo ceph-authtool /var/lib/ceph/tmp/keyring.mon.$(hostname) --create-keyring --name=mon. --add-
key=$(ceph-authtool --gen-print-key) --cap mon 'allow *'
sudo ceph-mon -c /etc/ceph/ceph.conf --mkfs -i $(hostname) --keyring /var/lib/ceph/tmp/keyring.mon
.$(hostname)
sudo initctl emit ceph-mon id=$(hostname)
6, 收集远程节点上的密钥到当前文件夹, ceph-deploy gatherkeys {ceph-node}
ceph-deploy gatherkeys node1
7, 增加osd, ceph-deploy osd prepare {ceph-node}:/path/to/directory
ceph-deploy osd prepare node1:/srv/ceph/osd0
ceph-deploy osd prepare node1:/srv/ceph/osd1
若使用了cephx权限的话,可以:
OSD_ID=$(sudo ceph -c /etc/ceph/ceph.conf osd create)
sudo ceph -c /etc/ceph/ceph.conf auth get-or-create osd.${OSD_ID} mon 'allow profile osd ' osd
'allow *' | sudo tee ${CEPH_DATA_DIR}/osd/ceph-${OSD_ID}/keyring
8, 激活OSD, ceph-deploy osd activate {ceph-node}:/path/to/directory
sudo ceph-deploy osd activate node1:/srv/ceph/osd0
sudo ceph-deploy osd activate node1:/srv/ceph/osd1
若出现错误ceph-disk: Error: No cluster conf found,那是需要清空/src/ceph/osd0
9, 复制 admin 密钥到其他节点, 复制 ceph.conf, ceph.client.admin.keyring 到 ceph{1,2,3}:/etc/ceph
ceph-deploy admin node1
10, 验证
sudo ceph -s
sudo ceph osd tree
11, 添加新的mon
多个mon可以高可用,
1)修改/etc/ceph/ceph.conf文件,如修改:mon_initial_members = node1 node2
2) 同步配置到其它节点,ceph-deploy --overwrite-conf config push node1 node2
3) 创建mon, ceph-deploy node1 node2
12, 添加新mds, 只有文件系统只需要mds,目前官方只推荐在生产环境中使用一个 mds。
13, 作为文件系统使用直接mount即可,mount -t ceph node1:6789:/ /mnt -o name=admin,secret=
14, 作为块设备使用:
sudo modprobe rbd
sudo ceph osd pool set data min_size 2
sudo rbd create --size 1 -p data test1 #创建1M块设备/dev/rbd/{poolname}/imagename
sudo rbd map test1 --pool data
sudo mkfs.ext4 /dev/rbd/data/test1
15, 命令操作
1)默认有3个池
$ sudo rados lspools
data
metadata
rbd
创建池:$ sudo rados mkpool nova
2)将data池的文件副本数设为2, 此值是副本数(总共有2个osd, 如果只有一个osd的话就设置为1),如果不设置这个就命令一直不返回
$ sudo ceph osd pool set data min_size 2
set pool 0 min_size to 1
3)上传一个文件,$ sudo rados put test.txt ./test.txt --pool=data
4)查看文件,
$ sudo rados -p data ls
test.txt
5)查看对象位置
$ sudo ceph osd map data test.txt
osdmap e9 pool 'data' (0) object 'test.txt' -> pg 0.8b0b6108 (0.8) -> up ([0], p0) acting ([0], p0)
$ cat /srv/ceph/osd0/current/0.8_head/test.txt__head_8B0B6108__0
test
6)添加一个新osd后,可以用“sudo ceph -w”命令看到对象在群体内迁移
16, Ceph与Cinder集成, 见:http://ceph.com/docs/master/rbd/rbd-openstack/
1) 集建池
sudo ceph osd pool create volumes 8
sudo ceph osd pool create images 8
sudo ceph osd pool set volumes min_size 2
sudo ceph osd pool set images min_size 2
2) 配置glance-api, cinder-volume, nova-compute的节点作为ceph client,因为我的全部是一台机器就不需要执行下列步骤
a, 都需要ceph.conf, ssh {openstack-server} sudo tee /etc/ceph/ceph.conf < /etc/ceph/ceph.conf
b, 都需要安装ceph client, sudo apt-get install Python-ceph ceph-common
c, 为images池创建cinder用户,为images创建glance用户,并给用户赋予权限
sudo ceph auth get-or-create client.cinder mon 'allow r' osd 'allow class-read object_prefixrbd_children,allow rwx pool=volumes,allow rx pool=images'
sudo ceph auth get-or-create client.glance mon 'allow r' osd 'allow class-read object_prefixrbd_children,allow rwx pool=images'\
如果涉及了权限的话,命令看起来像这样:
ceph --name mon. --keyring /var/lib/ceph/mon/ceph-p01-storage-a1-e1c7g8/keyring auth get-or-create client.nova-compute mon allow rw osd allow rwx
d, 为cinder和glance生成密钥(ceph.client.cinder.keyring与ceph.client.glance.keyring)
sudo chown -R hua:root /etc/ceph
ceph auth get-or-create client.glance | ssh {glance-api-server} sudo tee /etc/ceph/ceph.client.glance.keyring
ssh {glance-api-server} sudo chown hua:root /etc/ceph/ceph.client.glance.keyring
ceph auth get-or-create client.cinder | ssh {volume-server} sudo tee /etc/ceph/ceph.client.cinder.keyring
ssh {cinder-volume-server} sudo chown hua:root /etc/ceph/ceph.client.cinder.keyring
e, 配置glance, /etc/glance/glance-api.conf,注意,是追加,放在后面
default_store=rbd
rbd_store_user=glance
rbd_store_pool=images
show_image_direct_url=True
f, 为nova-compute的libvirt进程也生成它所需要的ceph密钥client.cinder.key
sudo ceph auth get-key client.cinder | ssh {compute-node} tee /etc/ceph/client.cinder.key
$ sudo ceph auth get-key client.cinder | ssh node1 tee /etc/ceph/client.cinder.key
AQAXe6dTsCEkBRAA7MbJdRruSmW9XEYy/3WgQA==
$ uuidgen
e896efb2-1602-42cc-8a0c-c032831eef17
$ cat > secret.xml <
EOF
$ sudo virsh secret-define --file secret.xml
Secret e896efb2-1602-42cc-8a0c-c032831eef17 created
$ sudo virsh secret-set-value --secret e896efb2-1602-42cc-8a0c-c032831eef17 --base64 $(cat /etc/ceph/client.cinder.key)
$ rm client.cinder.key secret.xml
vi /etc/nova/nova.conf
libvirt_images_type=rbd
libvirt_images_rbd_pool=volumes
libvirt_images_rbd_ceph_conf=/etc/ceph/ceph.conf
rbd_user=cinder
rbd_secret_uuid=e896efb2-1602-42cc-8a0c-c032831eef17
libvirt_inject_password=false
libvirt_inject_key=false
libvirt_inject_partition=-2
并重启nova-compute服务后在计算节点可以执行:
sudo rbd --keyring /etc/ceph/client.cinder.key --id nova-compute -p cinder ls
f,配置cinder.conf并重启cinder-volume,
sudo apt-get install librados-dev librados2 librbd-dev python-ceph radosgw radosgw-agent
cinder-volume --config-file /etc/cinder/cinder.conf
volume_driver =cinder.volume.drivers.rbd.RBDDriver
rbd_pool=volumes
glance_api_version= 2
rbd_user = cinder
rbd_secret_uuid = e896efb2-1602-42cc-8a0c-c032831eef17
rbd_ceph_conf=/etc/ceph/ceph.conf
17, 运行一个实例
wget http://download.cirros-cloud.net/0.3.2/cirros-0.3.2-x86_64-disk.img
qemu-img convert -f qcow2 -O raw cirros-0.3.2-x86_64-disk.img cirros-0.3.2-x86_64-disk.raw
glance image-create --name cirros --disk-format raw --Container-format ovf --file cirros-0.3.2-x86_64-disk.raw --is-public True
$ glance index
ID Name Disk Format Container Format Size
------------------------------------ ------------------------------ -------------------- -------------------- --------------
dbc2b04d-7bf7-4f78-bdc0-859a8a588122 cirros raw ovf 41126400
$ rados -p images ls
rbd_id.dbc2b04d-7bf7-4f78-bdc0-859a8a588122
cinder create --image-id dbc2b04d-7bf7-4f78-bdc0-859a8a588122 --display-name storage1 1
cinder list
18, Destroying a cluster
cd /bak/work/ceph/ceph-cluster/
ceph-deploy purge node1
ceph-deploy purgedata node1
rm -rf /bak/work/ceph/ceph-cluster/*
sudo umount /srv/ceph/osd0
sudo umount /srv/ceph/osd1
mkdir -p /srv/ceph/{osd0,mon0,mds0}
devstack对ceph的支持见:https://review.openstack.org/#/c/65113/
一些调试经验:
收集数据
ceph status --format=json-pretty, 提供健康状态,monitors, osds和placement groups的状态,当前的epoch
ceph health detail --format=json-pretty, 提供像monitors,placement groups的错误和警告信息等
ceph osd tree --format=json-pretty, 提供了osd的状态,以及osd在哪个cluster上
问诊Placement Groups
ceph health detail
ceph pg dump_stuck --format=json-pretty
ceph pg map
ceph pg
ceph -w
例如:pg 4.63 is stuck unclean for 2303.828665, current state active+degraded, last acting [2,1]
它说明4.63这个placement groups位于pool 4, stuck了2303.828665秒,这个pg里的[2, 1]这些osd受到了影响
a, inactive状态,一般是osd是down状态的,'ceph pg
b, unclean状态,意味着object没有复制到期望的备份数量,这一般是recovery有问题
c, Degraded状态,复制数量多于osd数量时可能出现这种情况,'ceph -w'可查看复制过程
d, Undersized状态,意味着placement groups和pgnum不匹配,一般是配置错误,像池的pgnum配置的太多, cluster's crush map, 或者osd没空间了。总之,是有什么情况阻止了crush算法为pg选择osd
e, Stale状态,pg内没有osd报告状态时是这样的,可能osd离线了,重启osd去重建PG
替换出错的osd或磁盘
见:http://ceph.com/docs/master/rados/operations/add-or-rm-osds/
总得来说:
Remove the OSD
1, Mark the OSD as out of the cluster
2, Wait for the data migration throughout the cluster (ceph -w)
3, Stop the OSD
4, Remove the OSD from the crushmap (ceph osd crush remove
5, Delete the OSD’s authentication (ceph auth del
6, Remove the OSD entry from any of the ceph.conf files.
Adding the OSD
1, Create the new OSD (ceph osd create
2, Create a filesystem on the OSD
3, Mount the disk to the OSD directory
4, Initialize the OSD directory & create auth key
5, Allow the auth key to have access to the cluster
6, Add the OSD to the crushmap
7, Start the OSD
磁盘Hung了无法unmount
echo offline > /sys/block/$DISK/device/state
echo 1 > /sys/block/$DISK/device/delete
恢复incomplete PGs
在ceph集群中,如果有的节点没有空间的话容易造成incomplete PGs,恢复起来很困难,可以采用osd_find_best_info_ignore_history_les这招(在ceph.conf中设置osd_find_best_info_ignore_history_les选项后, PG peering进程将忽略last epoch,从头在历史日志中找到和此PG相关的信息回放)。可以采用reweight-by-utilization参数控制不要发生一个节点空间不够的情况。
参考:
1, http://blog.scsorlando.com/post/2013/11/21/Ceph-Install-and-Deployment-in-a-production-environment.aspx
2, http://mathslinux.org/?p=441
3, http://blog.zhaw.ch/icclab/deploy-ceph-and-start-using-it-end-to-end-tutorial-installation-part-13/
4, http://dachary.org/?p=1971
5, http://blog.csdn.net/EricGogh/article/details/24348127
6, https://wiki.debian.org/OpenStackCephHowto
7, http://ceph.com/docs/master/rbd/rbd-openstack/#configure-openstack-to-use-ceph
8, http://openstack.redhat.com/Using_Ceph_for_Cinder_with_RDO_Havana
9, http://dachary.org/?p=2374