ceph存储 PG的状态机和peering过程
PG 的状态机和peering过程
首先来解释下什么是pg peering过程?
当最初建立PG之后,那么需要同步这个pg上所有osd中的pg状态。在这个同步状态的过程叫做peering过程。同样当启动osd的时候,这个osd上所有的pg都要进行peering过程,同步pg的状态。peering过程结束后进入pg的Active状态,如果需要进行数据恢复则进行数据的恢复工作。
那么从PG的创建或者扫描开始,PG就开始设置了自己的初始状态,到最后的完全同步,这期间使用一个叫做state_machine的机制进行标记和处理,然后加上事件机制进行通信。最后达到active+clean。
下面是一个pg的所有状态,pg的状态管理全部都交给一个叫做recoverymachine的成员来管理,pg的所有的状态是一个类似树形的结构,每个状态可能存在子状态,子状态还可能存在子状态如下图。
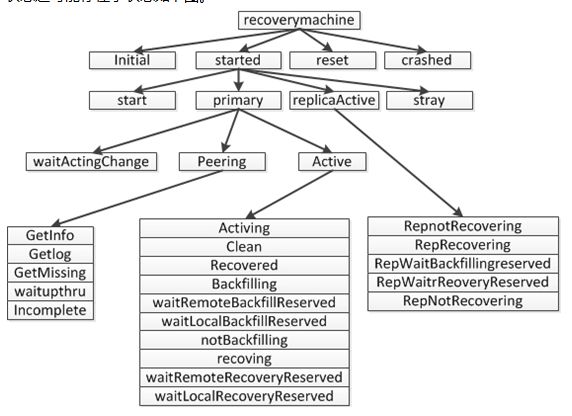
pg的状态变化是一套状态机,根据不同的状态接收到不同的事件进行相互的转化。
一、PG状态变化的时机:
a.创建pg后,会经过一系列的PG的状态变化,由Initial最后演化成Active+clean状态。
b.就是osd启动后,会进行PG扫描,扫描后会重新在本osd上建立PG,然后在经过一系列的pg状态变化,最后达到clean状态。
c.当其他osd启动后,如果和本osd处于同一个PG内,会收到pg成员变化事件,处理该事件则本osd上的pg状态也会重新被设置,再次经历状态变化,最后达到平衡的clean状态。
二、pg的状态演化过程
下面经过一个pg状态变化的过程说起,这个过程叫做PG的peering过程。peering的过程其实就是pg状态从初始状态然后到active+clean的变化过程。一个osd启动之后,上面的pg开始工作,状态为initial,这时进行比对所有osd上的pglog和pg_info,对pg的所有信息进行同步,选举primary osd和replica osd,peering过程结束,然后把peering的结果交给recovering,有recovering过程进行数据的恢复工作(如下图)。primary osd与replica osd经过一系列的状态事件的交互,最后达到active状态。


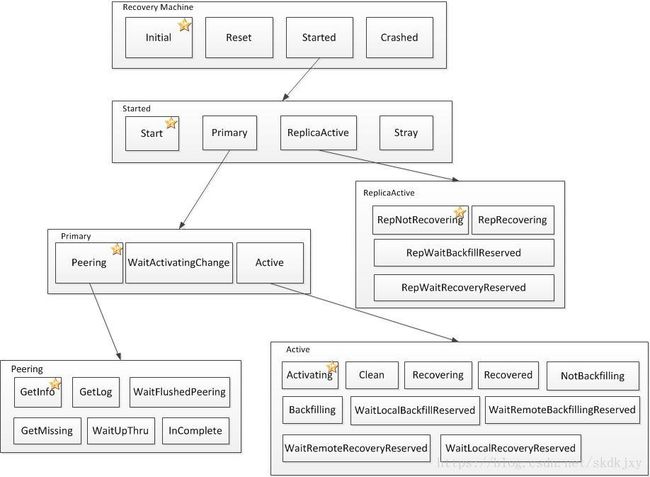
三、pg状态变化实例讲解
3.1 pg状态的管理结构:
1)pg在创建或者扫描时都会重新的把pg的结构创建起来,上一节在pg创建的时候已经说了,由monitor 会发送事件给osd,osd会处理事件,并且完成pg的创建工作。这里和故障恢复有密不可分的关系,下一节讲述数据的故障恢复。
2)创建pg的时候会初始化一个叫做recovery_state的成员,该成员就是用来控制pg的状态变化和处理事件的机制。recover_state中存在一个成员叫做recovery_machie,该成员继承了boost::statechart::state_machine状态机,该状态机就是用来处理状态变化的。
pg与state_machine的关系如下图。
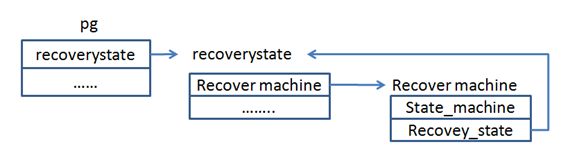
该途中表明了几个数据结构之间的关系。
3.2 数据的pg状态变化过程
3.2.1 NULL -> initial
1).来看一下申请PG的时候 对PG结构的初始化。在PG进行初始化的时候就对recoverystate(this)。
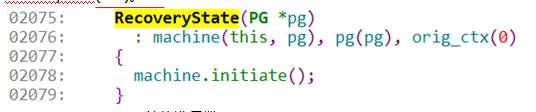
2075:recoverystate的构造函数。
2078:对于machine进行初始化。这时初始化machine的状态为Initial状态。
3.2.2 initial -> reset -> Started
2).创建PG之后,就要对PG的发送一系列的事件了,首先是创建事件,调取函数handle_create()。在handle_create中主要发送了两个事件。

5758:handle_create()处理函数。
5761:申请一个 Initialize d的事件evt。
5762:本端的recoverystate处理该事件。handle_event中调用machine. process_event ()。交由状态机进行处理。当状态为Initial的machine遇见Initialize事件会转化状态为reset状态。因为在initial状态里定义了,如果收到了Initialize事件则将状态转化为reset。
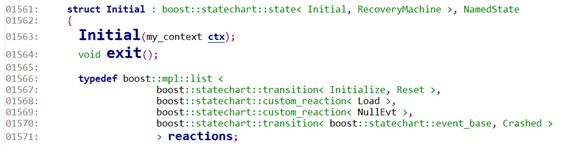
1567:定义了如果在Initial状态的时候,收到了Initialize事件,则转化为Reset状态。
目前是已经为Reset的状态了。带着这个状态再回到handle_create中。

5763:这里定义了第二个事件 ActMap 的evt2.
5764:通过recoverystate.handle_event()再次交给machine。但是这时machine的状态已经变成了Reset了,由Reset状态开始处理Actmap事件。在reset的事件处理函数中boost::statechart::result PG::RecoveryState::Reset::react(const ActMap&),最后将状态转化为了Started。transit< Started >()。然后来看Started状态,转化成该状态后又继续处理状态,在定义Started的时候默认设置了一个子状态start。
3.2.3 Started(start) ->Started( primary(Peering(GetInfo)))
3).来看一下当进入start时是怎么来处理的。
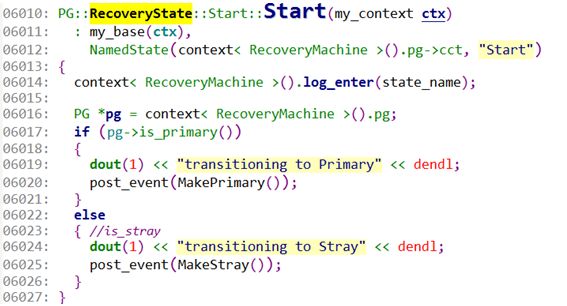
6010:开始处理进入start状态后的处理。
6016:找到对应处理的PG。
6017:如果当前的osd在本pg里是 primary。
6020:向本状态发送事件MakePrimary()事件。
6022:如果当前的osd在本pg里是replica。
6025:向本状态发送事件MakeStray。
4).接下来看看start状态如何来处理MakePrimary和MakeStray的事件吧,下面来看。

1653:如果接受到MakePrimary事件,则将状态start转化为Primary状态。
1654:如果接受到Makestray事件,则将状态start转化为stray状态。
接下来按着Primary osd的流程走。在进入Primary状态之后,在Primary状态存在一个子状态叫做Peering状态。并且Peering也同样存在一个子状态叫做GetInfo。在GetInfo的函数PG::RecoveryState::GetInfo::GetInfo()中做了哪些事情。
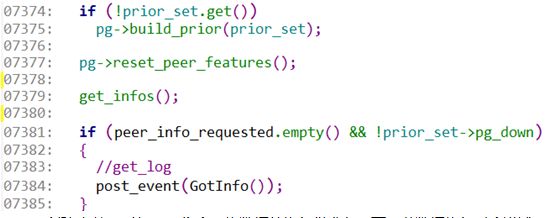
7375:创建当前pg的OSD集合。为数据的恢复做准备。下一节数据恢复时会讲述。
7379:发送请求到所有的副本osd中,请求pg_info信息,发送事件MQuery& query,query的类型是pg_query_t::INFO。然后发送的请求都会记录在peer_info_request队列中。
7381:如果想其他的osd发送的查询pg_info事件,那一定会添加到peer_info_request队列中,所以这里就不为空,然后就结束了。此时状态就到这里,目前是GetInfo的状态。等待replica osd获取pg_info结束后,再将结果通过事件发送给primary osd。
3.2.4 GetInfo->GetLog
5).当primary osd接到事件MNotifyRec& infoevt,然后对该事件展开处理。在GetInfo的状态下处理该事件,在处理该事件的时候会对拉取的pginfo进行处理,最后如果所有的副本都成功的将信息返回了,则会本端再次发起事件post_event(GotInfo());当GetInfo状态收到事件GotInfo(),则会转换状态为GetLog。现在交给了GetLog状态来继续处理,在进入GetLog中,做了如下的操作。

7621:这里要进行选择acting。包括了选择auth_osd、primary选择,副本选择(计算backfill osd,recover osd)。
7635:判断auth是不是正在处理的本osd上,如果是自己的话,那自己本身就是最全的log,所以不需要拉取log。
7637:因为不用拉取其他osd上的log,所以这里直接发送Gotlog事件,说明不需要拉取log,可以进入下一个状态了。
7673:由于自己本事auth osd,所以不是最全的log,所以要从其他osd上拉取log,这里准备事件g_query_t::LOG,发送到目标auth osd上拉取。
3.2.4 GetLog->GetMissing
6).本端使用handle_pg_query 处理g_query_t::LOG,将其封装成为MOSDPGLog消息,该消息发送到目标auth osd后,有auth osd解封消息,并且构造PG::MLogRec事件,发送给auth_osd处理,在auth_osd上形成MQuery& query 交给pg的state_machine处理,处理该事件,pg->fulfill_log(),获取本地log,然后通过消息MOSDPGLog发还给primary osd。这时primary 接到auth_osd发送过来的消息,并且消息携带auth_log的信息。在primary解析成为MLogRec 信息。这时primary osd的状态为GetLog,开始处理MLogRec 事件。直接出发post_event(GotLog())事件,当GetLog接收到Gotlog事件的时候,先要合并proc_master_log(),然后转换状态为GetMissing状态。
GetMissing的处理,在GetMissing中开始拉取所有副本的log信息,发送事件,等待所有的副本将自己的log和missing准备好发送给primary osd。这时primary osd处于GetMissing状态处理MLogRec事件,处理时proc_replica_log(),合并副本的log。

7974:当接受的log事件时候,将peer_missing_requested 队列中对应osd的计数删除。这个队列方便统计哪些osd没有及时的反馈消息。
7975:接收事件后,开始处理事件,proc_replica_log()合并副本的INFO,log,missing等信息。
7978:判断是否需要更新up_thru。
7983:如果需要更新up_thru。则发送NeedupThru事件。
7989:如果不需要更新up_thru,则发送Activate()事件。
3.2.6 GetMissing->Active(Activating)
7). 假设这里发送了Activate()事件,GetMissing状态会对Activate事件直接将状态转化为Active状态,在进入Active后会调用PG::activate的处理。在Activete的处理中有两件事儿.。a.准备事务的回调准备工作,申请注册C_PG_ActivateCommitted。b.准备想其他的osd发送合并后的log,将权威的log封装成MOSDPGLog,发送给副本,然后提交事务。
这时其他osd副本接收到MOSDPGLog事件,将解释为本地的MLogRec,副本osd的pg状态为stray,接收到MLogRec事件后。主要做的有三件事儿:a.合并接收到的log到本地log中,b.准备发送事件Activate,c.转化到状态ReplicaActive。最后由ReplicaActive状态处理事件Activate。这时同样会调用PG::activate()处理。这里主要准备了两件事儿,1.准备申请注册事务的回调处理函数C_PG_ActivateCommitted,2.准备进行数据恢复时的各种状态设置。完成后提交事务操作,等待事务完成。
目前,有两件事儿需要说明一下,primary osd提交了事务等待C_PG_ActivateCommitted处理,replica osd同样提交了事务等待C_PG_ActivateCommitted处理。接下来就来看看这个里边做了哪些工作。
primary osd处理完成后,提交事务回调进入_activate_committed中,

2109:如果这时判断本osd是主osd。
2117:判断是不是所有的osd都返回了提交了结果。
2119:如果是primary osd,并且所有的replica都提交了结果,则进行all_activated_and_committed()处理。
2125:如果不是primary osd,而是replica osd这时就要告诉primary osd,我已经处理好了,发送消息 MOSDPGInfo。
8).当primary osd接收到MOSDPGInfo消息,解析为MInfoRec事件,这时primary osd的状态为active,接收MInfoRec开始处理。

6998:当向一个osd发送MOSDPGLog后,会在对应osd的序号添加到peer_active的队列中,当osd反馈消息MOSDPGInfo后,会将osd的序号添加到actingbackfill队列中。这里判断是不是所有的osd都处理完成了事务。
7000:如果所有的osd都完成了事务的处理,接下来进入all_activated_and_committed处理中。在all_activated_and_committed中主要是要发送事件通知PG的状态,通知告知已经是AllReplicasActivated事件。
3.2.7 Active(Activating)-> WaitLocalRecoveryReserved->WaitRemoteRecoveryReserved-> Active(recovering)
active接受到AllReplicasActivated事件后,开始处理,这其中主要调用pg-> on_activate ()函数。由于PG是由ReplicatedPG子类继承的,所以这里调用ReplicatedPG::on_activate 进行处理。
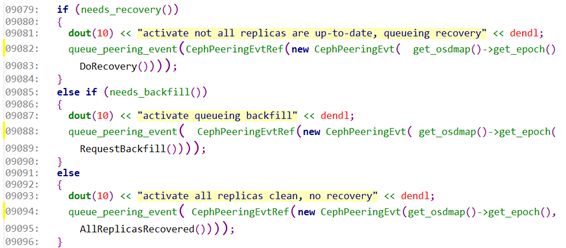
9079:判断是否需要进行recovery数据的恢复。
9082:如果需要进行数据恢复,则发送事件DoRecovery()事件。
9085:判断是否需要进行backfill数据恢复。
9088:如果需要进行backfill数据恢复,则需要发送事件RequestBackfill()事件。
9091:即不需要recovery也不需要backfill等操作,则发送事件AllReplicasRecovered事件。
9).假设这里需要进行数据的恢复,这时发送了DoRecovery事件。activ状态接受到事件DoRecovery后进入子状态WaitLocalRecoveryReserved。该状态是active的子状态,仍让处于active状态中。在WaitLocalRecoveryReserved中会进行reserver处理并且发送LocalRecoveryReserved事件,WaitLocalRecoveryReserved接受到该事件后将转化为WaitRemoteRecoveryReserved状态。进入该状态后发RemoteRecoveryReserved事件,处理该事件时再次发送事件AllRemotesReserved,状态转化为Recovering。

6651:进入recovering时要进行的处理。
6658:清除PG的state中的PG_STATE_RECOVERY_WAIT。
6659:设置PG的state中的 PG_STATE_RECOVERING。
6660:准备将pg交给osd的recovery线程处理,进行数据恢复,这里是先添加到recovery_wq,然后等待线程处理队列中的pg数据恢复请求。
3.2.8 recovering->recoverd->clean
10). 该队列是由osd->recovery_wq 来实现的,而不是OSDService-> recovery_wq。
该队列的处理线程直接调用函数OSD::do_recovery()进行处理。在其中主要使用pg-> start_recovery_ops进行处理,在start_recovery_ops中判断这个pg已经数据恢复完成的时候。

代码能进行到这里说明已经PG的数据恢复完成。具体的数据恢复过程,后面的章节会讲述。
9510:这时检测状态是不是正在进行数据恢复状态是否为PG_STATE_RECOVERING。
9512:清除状态PG_STATE_RECOVERING。
9513:判断是不是要进行backfill处理?
9522:如果不需要进行backfill处理,这时代表所有的数据恢复都完成了,则发送事件AllReplicasRecovered。
11).这时recovering状态的pg接收到AllReplicasRecovered事件,则将pg的状态转化为Recovered状态。这时将会再次发送GoClean()事件。PG接收到GoClean()事件,将转化为clean状态。
最后的PG状态就是Active+clean的状态。clean是Active的一个子状态。最终完成了PG的所有状态变换。