Federated Machine Learning:Concept and Applications
https://www.cnblogs.com/lucifer1997/p/11223964.html
https://blog.csdn.net/qq_36375505/article/details/88554005
https://blog.csdn.net/weixin_44774630/article/details/97529260?utm_source=app
关键技术:
差分隐私DP:
在数据中添加噪声,或者使用泛化方法对某些敏感属性进行模糊处理,直到第三方无法区分个体。但在root端可能会泄露数据。
定义:对于单个项目中不同的任意两个数据集D和D ',和函数f的任意输出O,ε控制精度和隐私之间的权衡:![]()
多方安全计算SMC:
两方分别拥有各自的私有数据,在不泄漏各自私有数据的情况下,能够计算出关于公共函数 的结果。整个计算完成时,只有计算结果对双方可知,且双方均不知对方的数据以及计算过程的中间数据。框架设计使模型只能得到输入这个模型的数据。完全杜绝了不同用户下相互传递信息的情况。
cr:介绍 、百万富翁问题。
同态加密HE:
数据和模型本身不传输,也不能通过对接收数据进行猜测来还原用户数据
秘密共享:
将秘密以适当的方式拆分,拆分后的每一个份额由不同的参与者管理,单个参与者无法恢复秘密信息,只有若干个参与者一同协作才能恢复秘密消息。更重要的是,当其中任何相应范围内参与者出问题时,秘密仍可以完整恢复。
1.秘密K 被拆分为n 个份额的共享秘密
2.利用任意 t(2≤t≤n)个或更多个共享份额就可以恢复秘密 K
3.任何t – 1或更少的共享份额是不能得到关于秘密SK的任何有用信息
4.强健性:暴露一个份额或多到t – 1个份额都不会危及密钥,且少于 t – 1个用户不可能共谋得到密钥,同时若一个份额被丢失或损坏,还可恢复密钥
姚式混淆电路

Alice准备一个混淆的电路版本,并连同相关的随机输入密钥一起发送给Bob。Bob可以不用知道Alice的任何输入以及中间值,就可以计算出电路的输出,并发送给Alice,作为双方接受的最终计算结果。
布尔电路的输入输出线路通常是0或者1的比特串,而对应的混淆电路的线路是随机的密钥值(或者称为混淆值)。每条线路有两个随机密钥值,分别对应0和1,计算时只能使用其中之一。
Alice的隐私输入为x,其构造电路时可以根据x的二进制比特位,选择其输入线路对应的随机密钥值,发送电路计算者Bob;而Bob隐私输入y串对应的随机密钥值,需要通过多次OT(Oblivious Transfer)协议从Alice处获取对应的随机密钥值,OT协议可以保证不泄露Bob的隐私输入y给Alice。
Alice构造混淆电路时,会采用加密、变换等手段为电路中每个门生成真值表,称为混淆真值表。Bob获得混淆真值表和x,y对应的输入随机密钥值后,就可以应用真值表计算混淆电路,获得最终输出,最后使用解密门电路可以得到实际的输出f(x,y)。
数据泄露问题&解决方法:
泄露:
①随机梯度下降(SGD)等优化算法的参数更新——提出了一种新的“约束和规模”模型-中毒方法,以减少数据中毒。
②推理攻击:协作机器学习系统中潜在的漏洞。敌对参与者可以推断成员身份以及与训练数据子集相关的属性——提出了梯度下降方法的一种安全变体。
③其他方法:研究人员也开始考虑区块链作为促进联邦学习的平台。在[34]中,研究人员考虑了块链式联邦学习(BlockFL)的体系结构, 其中移动设备的本地学习模型更新通过利用块链进行交换和验证。它们考虑了最优块生成、网络可伸缩性和健壮性问题。
联邦学习分类
☆数据集:(I,X,Y) {I:ID space ; X:features space ; Y:label space }
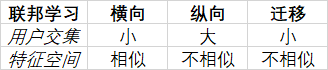
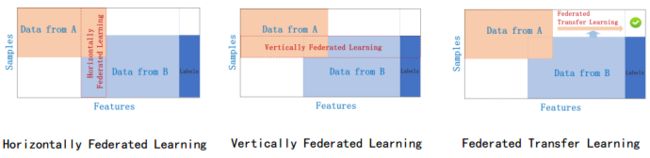
1)横向联邦学习
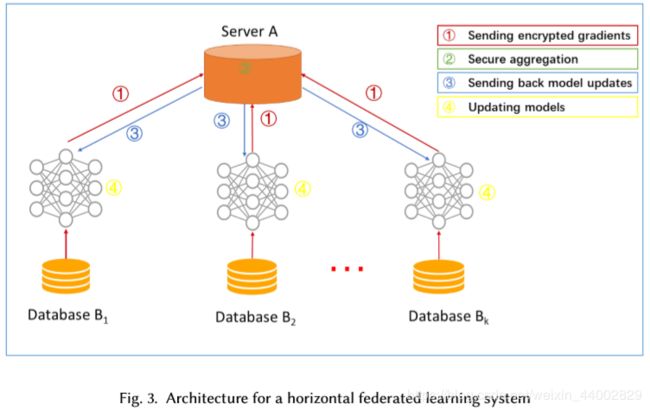
步骤:
- 参与者本地计算训练梯度,使用加密、差异隐私或秘密共享技术屏蔽梯度,并将屏蔽结果发送给服务器;
- 服务器在没有关于任何参与者的学习信息的情况下执行安全聚合;
- 服务器向参与者发送聚合的结果;
- 参与者更新它们各自的模型具有解密的梯度。
安全问题:
如果用SMC或同态加密进行梯度聚合,则上述结构可以防止半诚实服务器的数据泄漏。
但可能在另一个安全模型中,恶意参与者在协作学习过程中训练生成的AdversarialNetwork(GAN)。
2)纵向联邦学习
由于数据隐私和安全原因,A和B不能直接交换数据。以确保培训过程中数据的保密性 ,涉及第三方合作者C【governments或者Software Guard Extensions (SGX)】。在此,我们假设合作者C诚实,并不与A或B串通,但甲方和B是诚实的,但彼此好奇。
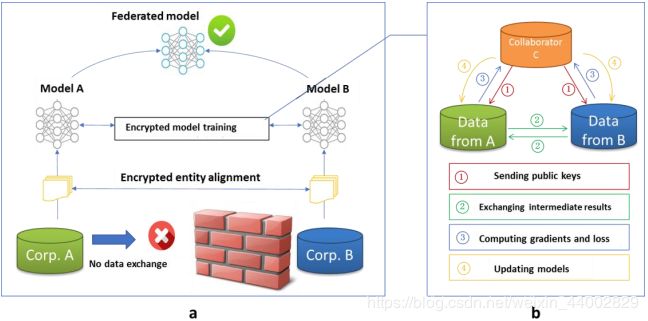
系统组成:
- 加密实体对齐:
由于两家公司的用户组并不相同,所以系统使用基于加密的用户ID对齐技术,关于双方的用户,没有A和B暴露他们各自的数据。在实体对齐过程中,系统不会公开不重叠的用户。 - 加密模型训练:
在确定公共实体后,可以利用这些公共实体的数据来训练机器学习模型。
训练过程:
- 协作者C创建加密对,将公钥发送给A和B。
- A和B对梯度和损失进行计算的中间结果进行加密和交换。
- A和B分别计算加密梯度,并分别添加附加掩码,B还计算加密损失;A和B向C发送加密值。
- C解密并发送解密梯度和损失回到A和B;A和B去除梯度的掩码,相应地更新模型参数。
本文以线性回归和同态加密为例说明了训练过程:用梯度下降法训练线性回归模型,需要对损失和梯度进行安全计算其损耗和梯度。 梯度下降法与线性回归模型
假设学习率η,正则化参数λ,数据集![]() ,对应特征空间
,对应特征空间![]()
![]() 的模型参数ΘA,ΘB。
的模型参数ΘA,ΘB。
训练目标:
假设![]() ,加密损失:
,加密损失: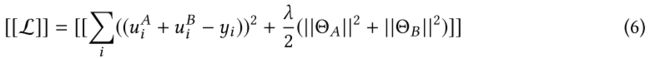
![]() 表示加法同态加密。
表示加法同态加密。
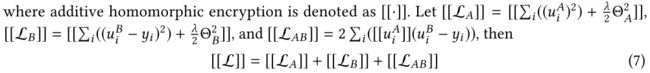
![]() ,梯度计算:
,梯度计算:
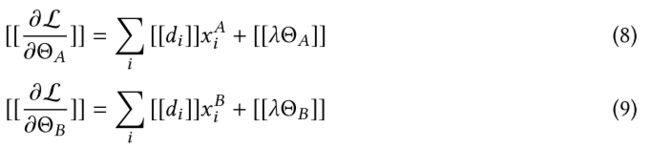


在实体对齐和模型训练过程中,A和B的数据在本地保存,训练中的数据交互不会导致数据隐私泄露。(注:向C泄漏的潜在信息可能被视为侵犯隐私。为了进一步阻止C从A或B中学到信息,在这种情况下,A和B可以通过添加加密的随机掩码进一步向C隐藏其梯度。)
因此,双方在联邦学习的帮助下实现了共同模型的训练。因为在训练过程中,每一方收到的损失和梯度与他们在一个没有隐私限制的地方汇聚数据,然后联合建立一个模型收到的损失和梯度是完全相同的,也就是说,这个模型是无损的。模型的效率取决于加密数据的通信成本和计算成本。在每次迭代中,A和B之间发送的信息按重叠样本的数量进行缩放。因此,采用分布式并行计算技术可以进一步提高算法的效率。
安全性分析:
表1所示的训练协议没有向C透露任何信息,因为所有C学习的都是掩码后的梯度,并且保证了掩码矩阵的随机性和保密性[16]。在上述协议中,A方在每一步都会学习其梯度,但这不足以让A根据等式8从B中学习任何信息。
因为标量积协议的安全性是建立在无法用n个方程解n个以上未知数[16,65]的基础上的。这里我们假设样本数NA比nA大得多(nA是特征数)。同样,B方也不能从A处获得任何信息,因此协议的安全性得到了证明。
【注意,我们假设双方都是半诚实的。如果一方是恶意的,并且通过伪造其输入来欺骗系统,例如,A方只提交一个只有一个非零特征的非零输入,它可以辨别该样本的该特征值uiB。但是,它仍然不能辨别xiB或ΘB,并且偏差会扭曲下一次迭代的结果,从而警告另一方终止学习过程。】
在训练过程结束时,每一方(A或B)都会不会察觉到另一方的数据结构,只获取与其自身特征相关的模型参数。推断时,双方需要协同计算预测结果,步骤如表2所示,这仍不会导致信息泄露。