JVM 技术内幕——HotSpot VM 的垃圾收集器
如果说收集方法是内存的方法论,那么垃圾收集器就是内存回收的具体实现。JVM 规范中对垃圾收集器应该如何实现并没有任何规定,因此不同厂商、不同版本的 JVM 所提供的垃圾收集器都可能会有很大差别,并且一般都会提供参数供用户根据自己的应用特点和要求组合出各个年代所使用的收集器。
一个重要的概念:
Stop-the-World:
- JVM 由于要执行 GC 而停止了应用程序的执行;
- 任何一种 GC 算法中都会发生;
- 多数 GC 优化通过减少 “Stop-the-World” 发生的时间来提高程序性能。
Safepoint(安全点):
- 可达性分析过程中对象引用关系不会发生变化的点;
- 产生 Safepoint 的地方:方法调用、循环跳转、异常跳转等;
- 安全点数量得适中,太少会让 GC 等待过长的时间,太多会增加程序运行的负荷。
JVM 的运行模式:
- Server 模式:启动较慢,但是启动进入稳定期长期运行之后,Server 模式的程序运行速度要比 Client 模式快,这是因为 Server 模式启动采用的是重量级的 JVM,对程序采用了更多的优化;
- Client 模式:启动较快,Client 模式启动采用的是轻量级的 JVM。
这里讨论的是 JDK 1.7 Update4 (7u4) 之后的 HotSpot VM,这个 VM 包含的所有收集器如下图所示:
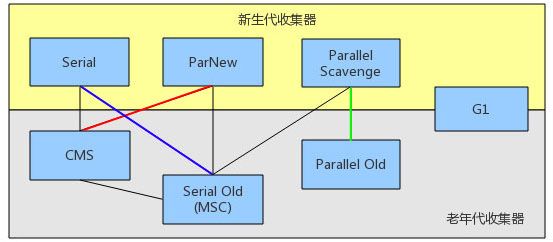
如果两个收集器之间存在连线,就说明它们可以搭配使用,彩色的连线是最常见的搭配。
| 收集器 | 时间 | 线程 | 所属代 | 应用 | 垃圾收集算法 |
|---|---|---|---|---|---|
| Serial | 单线程 | 新生代收集器 | Client模式 | “复制” 算法 | |
| Serial Old | 单线程 | Serial的老年代版本 | Client模式 | “标记-整理” 算法 | |
| ParNew | Serial的多线程版本 | 新生代收集器 | Server模式 | “复制” 算法 | |
| CMS | JDK1.5 | 多线程 | 老年代收集器 | 追求低停顿的场景 | “标记-清除” 算法 |
| Parallel Scavenge | 多线程 | 新生代收集器 | 追求高吞吐的场景 | “复制” 算法 | |
| Parallel Old | JDK1.6 | 多线程 | Parallel Scavenge的老年代版本 | ||
| G1 | JDK1.7 | 多线程 | 可以独立管理整个堆(新生代、老年代) | Server模式 |
HotSpot VM 中垃圾收集器的可用组合:
| Young GC | Old GC | JVM 参数 | 说明 |
|---|---|---|---|
| Serial | Serial Old | -XX:+UseSerialGC | JDK 1.8 Client 模式默认收集器 |
| Parallel Scavenge | Serial Old | -XX:+UseParallelGC | JDK1.8 Server 模式默认收集器 |
| Parallel Scavenge | Parallel Old | -XX:+UseParallelOldGC | |
| ParNew | Serial Old | -XX:+UseParNewGC | |
| Serial | CMS | -XX:-UseParNewGC -XX:+UseConcMarkSweepGC | |
| ParNew | CMS | -XX:+UseParNewGC -XX:+UseConcMarkSweepGC | JDK1.6 Server 模式默认收集器 |
| G1 | G1 | -XX:+UseG1GC | JDK1.9 Server 模式默认收集器 |
1.HotSpot VM的垃圾收集器
Young GC 回收新生代 ,Old GC 回收年老代,Full GC 回收新生代、老年代、元数据区/永久代。JVM 性能调优的主要目的就是避免 Full GC 的发生。G1 收集器特有的 Mixed GC 回收新生代、老年代。
1.Serial+Serial Old收集器
JDK 1.8 Client 模式默认使用的组合,这是两个单线程收集器的组合。
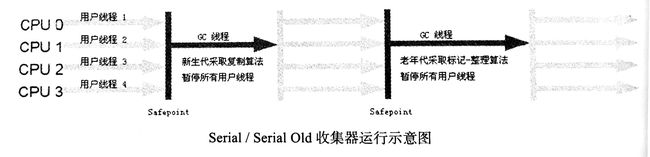
Serial 在进行 GC 时,必须暂停其他所有的工作线程,直到它 GC 结束(即 Stop The World)。“Stop The World” 带给用户的体验是不好的。但是 Serial 也是有优点的,由于没有线程交互的开销,Serial 可以获得最高的单线程 GC 效率。
Serial Old 是 Serial 的老年代版本,现在主要配合 Serial 使用或者作为 CMS 收集器的后备预案(在并发 GC 发生 “Concurrent Mode Failure” 时使用)。GC 参数:
-XX:+UseSerialGC //使用Serial+Serial Old的收集器组合来进行内存回收
2.ParNew+CMS收集器
两个多线程收集器的组合。

ParNew 其实就是 Serial 的多线程版本,除了使用多线程进行 GC 外,其余行为都与 Serial 完全一样,除了 Serial,目前只有它能与 CMS 收集器配合工作。ParNew 默认开启的 GC 线程数与 CPU 的数量相同。

CMS 是以获取最短回收停顿时间为目标的收集器,也被称为 “低停顿” 收集器,注重响应速度,希望系统停顿时间最短。
CMS 收集采用标记-清除法,分为:
1 初始标记,需要 "Stop The World",仅仅是标记一下 GC Roots 能直接关联到的对象,速度很快;
2 并发标记,进行 GC Roots Tracing 的过程;
3 重新标记,需要 "Stop The World",为了修正并发标记期间因用户程序继续运作而导致标记产生变动的那一部分对象的标记记录,这个阶段的停顿时间一般比初始标记阶段稍微长些,但远比并发标记的时间短;
4 并发清除。
初始标记和重新标记会引发 “Stop The World”。
由于整个过程耗时最长的是并发标记和并发清除,所以从整体上来说,CMS 收集器的内存回收过程是与用户线程一起并发执行的。
CMS 优点:并发收集、低停顿。
CMS 缺点:
- 对 CPU 资源非常敏感。在并发阶段,它虽然不会导致用户线程停顿,但是会因为占用了一部分 CPU 资源而导致应用程序变慢,总吞吐量会降低。CMS 默认启动的回收线程数是 (CPU数量+3) / 4。
- 无法处理浮动垃圾,可能出现 “Concurrent Mode Failure” 失败而导致另一次 Full GC 的产生。
- CMS 收集器基于 “标记-清除” 算法实现,所以收集结束时会有大量空间碎片产生。空间碎片过多时,将会给大对象的分配带来很多麻烦。
对于大量空间碎片的问题,CMS 收集器在顶不住要进行 Full GC 时会开启内存碎片的合并整理过程,内存整理的过程是无法并发的,所以碎片问题没有了,但停顿时间变长了。
碎片合并整理的过程,也可以通过 JVM 参数进行调优设置:
-XX:+UseCMSCompactAtFullCollection:在FULL GC的时候, 对年老代进行内存碎片的整理
问题 1:什么是浮动垃圾?
答:由于 CMS 并发清理阶段用户线程还在运行着,伴随程序运行自然就还会有新的垃圾不断产生,这一部分垃圾出现在标记过程之后,CMS 无法在当次收集中处理掉它们,只好留待下一次 GC 时再清理掉,这部分垃圾就称为 “浮动垃圾”。
问题 2:为什么 CMS 收集器老年代达到 92% 时就要回收?
答:CMS 会产生浮动垃圾,如果是用户程序产生的垃圾速度要更快一些,导致要填满了老年代,那么用户的程序就因为没有内存而无法运行了。因此 CMS 不能像其他收集器那样等到老年代几乎被填满了再进行收集,需要预留一部分空间提供并发收集时的程序运行使用。JDK 1.6 中 CMS 收集器的默认启动阀值为 92%。如果预留的内存任然无法满足程序需求,就会出现一次 “Concurrent Mode Failure” 失败,此时 JVM 将启动后备预案,临时使用 Serial Old 收集器来重新进行老年代的 GC,这样停顿的时间就很长了。
我们可以通过设置 GC 参数 -XX:CMSInitiatingOccupancyFraction 的值自定义触发百分比,以便获取最好的性能。
GC 参数:
-XX:ParallelGCThreads=20 //限制垃圾收集的线程数
在注重低停顿以及 IO 密集型的场合,都可以优先考虑使用 ParNew + CMS 收集器。
3.Parallel Scavenge+Parallel Old收集器
Parallel Scavenge + Parallel Old 收集器,这是两个多线程收集器的组合。

Parallel Scavenge 看上去跟 ParNew 都一样,它的特别之处在于 Parallel Scavenge 的目的是达到一个可控制的吞吐量,吞吐量 = 运行用户代码时间 / (运行用户代码时间 + 垃圾收集时间),垃圾收集时间越短,吞吐量越高。
高吞吐量可以高效的利用 CPU 时间,尽快完成程序的运算任务,主要适合在后台运算而不需要太多交互的任务。Parallel Scavenge 也经常被称为 “吞吐量优先” 收集器。
Parallel Scavenge 提供了一个参数:
–XX:-UseAdaptiveSizePolicy
这是一个开关参数,当这个参数打开后,就不需要手工指定新生代的大小(-Xmn)、Eden 与 Survivor 区的比例(-XX:SurvivorRatio)、晋升老年代对象大小(-XX:PretenureSizeThreshold)等细节参数了,JVM 会根据当前系统的运行情况收集性能监控数据,动态调整这些参数以提供最合适的停顿时间或最大的吞吐量,这种方式也被称为 GC 自适应的调节策略。
使用自适应的调节策略,只需要把基本的内存数据设置好(如 -Xmx 设置最大堆),然后使用 -XX:MaxGCPauseMillis(更关注最大停顿时间)参数或 -XX:GCTimeRatio(更关注吞吐量)参数给 JVM 设置一个优化目标,那具体细节参数的调节工作就交由 JVM 就好了。
Parallel Old 是 Parallel Scavenge 的老年代版本,在注重吞吐量以及 CPU 密集型的场合,都可以优先考虑使用 Parallel Scavenge + Parallel Old 收集器。
4.G1收集器
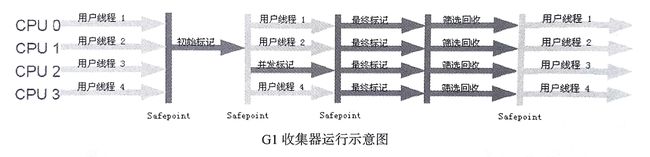
G1 收集器是一款面向 Server 端应用的收集器,与其它收集器相比,它具备如下特点:
- 并行与并发。充分利用多 CPU、多核优势,使用多个 CPU 来缩短 “Stop The World” 停顿的时间,部分其他收集器原本需要停顿 Java 线程执行的 GC 动作,G1 收集器仍然能通过并发的方式让 Java 程序继续执行。
- 分代收集。G1 可以不需要其他收集器配合就能独立管理整个 GC 堆,它能够采用不同的方式去处理新创建的对象和已经存活了一段时间、熬过多次 GC 的旧对象以获取更好的收集效果。
- 不会产生内存碎片。G1 从整体上来看上基于 “标记-整理” 算法实现的,从局部 (两个 Region 之间) 上来看上基于 “复制” 算法实现的,这两种算法意味着 G1 运作期间不会产生内存碎片,GC 后能提供规整的可用内存,有利于程序长时间运行。
- 可预测的停顿。G1 除了追求低停顿外,还能建立可预测的停顿时间模型,能让使用者明确指定在一个长度为 M 毫秒的时间片段内,消耗在 GC 上的时间不得超过 N 毫秒,这几乎是实时 Java 的垃圾收集器的特征了。
G1 将整个 Java 堆划分为多个大小相等的独立区域 (Region),新生代和老年代不是物理隔离的了,它们都是一部分 Region (不需要连续) 的集合。
最后还有一点需要说明的是:没有最好的收集器,只有对具体应用最合适的收集器。
5.ZGC收集器
在 JDK11 当中,加入了实验性质的 ZGC。ZGC 收集器是一种并发的、不分代的、基于 Region 且支持 NUMA 的压缩收集器,它的回收耗时平均不到 2 毫秒,是一款低停顿高并发的收集器。目前只在 Linux/x64 上可用。
ZGC 几乎在所有地方并发执行的,除了初始标记的是 “Stop-The-World” 的。所以停顿时间几乎就耗费在初始标记上,这部分的实际是非常少的。那么其他阶段是怎么做到可以并发执行的呢?
ZGC 主要新增了两项技术,一个是着色指针 Colored Pointer,另一个是读屏障 Load Barrier。